Ministral-3 afstemmen op vLLM
Een praktische handleiding voor platte tekst en JSON-antwoorden
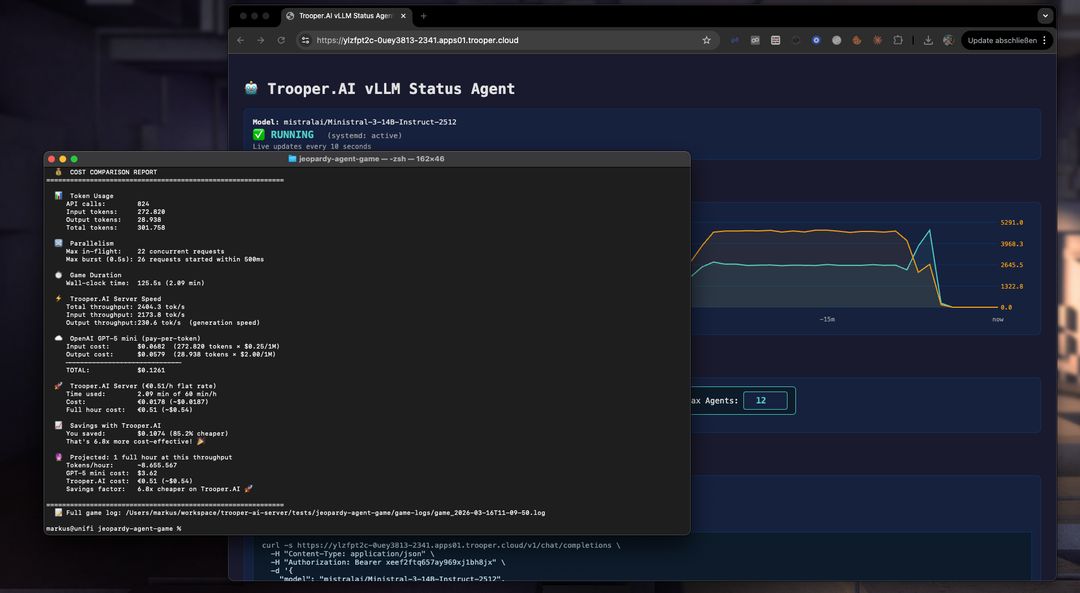
Lessons geleerd bij het bouwen van een AI Jeopardy-simulatie met 12 spelers, aangedreven door Ministral-3-14B-Instruct-2512.
Een praktische handleiding voor platte tekst en JSON-antwoorden
Lessons geleerd bij het bouwen van een AI Jeopardy-simulatie met 12 spelers, aangedreven door Ministral-3-14B-Instruct-2512.
Ministral-3 op vLLM uitvoeren is verrassend krachtig. Het model is snel, creatief en kan ook onder zware belastingen hoogwaardige antwoorden produceren.
Maar zodra je overstapt van eenvoudige chat-opdrachten naar gestructureerde uitvoer, automatisering of programmeerbare toepassingen, wordt het snel gecompliceerd.
Een door AI gestuurd Jeopardy-spel met 12 gelijktijdige spelers en honderden modellellenroepen
Deze gids vat de prktische lessen samen die we hebben geleerd bij het oplossen van deze problemen, inclusief concrete patronen die je kunt hergebruiken in jouw eigen projecten.
Ons benchmarkproject simuleert een volledig Jeopardy-spel waarin:
Een enkele uitvoering van het spel kan gemakkelijk meer dan 800 API-oproepen
Ministral gedraagt zich onder echte productieomstandigheden, wat deze omgeving een uitstekende testomgeving maakt voor het blootleggen van randgevallen die zelden voorkomen in eenvoudige demonstraties.
Ministral-modellen gebruiken geen standaard HuggingFace-tokenizersetup.
Dit betekent dat de opstartcommando het Mistral-tokenisatieformaat expliciet moet inschakelen.
vllm serve mistralai/Ministral-3-14B-Instruct-2512 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral
Functieaanroepen gebruikt uw applicatie? Voeg dan de volgende hulpmiddelenflags toe:
--enable-auto-tool-choice
--tool-call-parser mistral
Ministral ondersteunt in tegenstelling tot sommige andere modellen geen chat_template_kwargs
Als u een verzoek als dit verzendt:
{
"chat_template_kwargs": {
"enable_thinking": false
}
}
vLLM retourneert:
HTTP 400: chat_template is not supported for Mistral tokenizers
Expliciet inschakelen van een "denkmodus" (zoals gebruikt bij modellen zoals Qwen of DeepSeek) zijn simpelweg niet beschikbaar
Gelukkig is dit zelden nodig omdat Ministral standaard al beknopte uitvoer produceert.
De officiële vLLM-documentatie gebruikt consistent de volgende waarde voor Ministral-3:
temperature = 0.15
Uiterst belangrijk voor gestructureerde taken, hoewel het op het eerste gezicht erg laag lijkt.
Met de standaardinstellingen van OpenAI:
temperature: 0.7
te veel structuurvrij of afwijkend in opbouw
Een eenvoudige vraag zoals:
{ "expertise": "2-3 topics they know best" }
kan zoiets retourneren:
{
"expertise": [
{
"category": "Gourmet Pizza Alchemy",
"detail": "Can transform random ingredients into Michelin-star pizza"
},
{
"category": "Sumo Wrestling Physics",
"detail": "Understands body mechanics and center-of-gravity combat"
}
]
}
niet wat het schema vraagt
Het resultaat:
max_tokens limieten worden overschreden0.15 werkt beterstructureel gedisciplineerd
temperature: 0.15
Voordelen:
Zelfs creatieve tekstgeneratie blijft sterk — het model stopt simpelweg met het improviseren met structuur.
Aanbeveling:
Gebruik temperature: 0.15 als standaardwaarde voor Ministral-3.
Machinaal leesbare JSON genereren uit grote taalmodellen (LLMs) is lastiger dan het klinkt.
Semantisch in plaats van structureel
Een prompt zoals:
Return JSON with these fields.
produceert vaak uitvoerige structuren.
Voorbeeld aanvraag:
{ "expertise": "2-3 topics they know best" }
Typische reactie:
{
"expertise": [
{
"category": "Ancient Roman Engineering",
"detail": "Knows aqueduct systems in surprising detail"
},
{
"category": "Pizza Dough Chemistry",
"detail": "Obsessed with yeast fermentation dynamics"
}
]
}
Dit kost drie keer zoveel tokens als verwacht
twee instructies
Respond with ONLY valid JSON.
No markdown, no explanation, no text before or after the JSON.
Keep values as short plain strings — never use nested objects or arrays.
Direct naast de schema definitie:
Every value MUST be a short plain string — NO arrays, NO nested objects.
temperatuur 0.15, dit levert voorspelbaar plat JSON op.
Ministral levert onder beperkingen nog steeds langere waarden op dan andere modellen
Voorbeeld observatie uit onze benchmark:
| Model | Benodigde tokens |
|---|---|
| GPT-4o | ~512 |
| Qwen | ~512 |
| Ministral-3 | ~1024 |
Een veilige regel:
Reserveer 1,5–2× het aantal tokens voor JSON-outputs.
Zelfs met perfecte prompts genereren modellen af en toe ongeldige JSON.
Defensieve parsemethodes toevoegen
function extractJSON(raw, shape) {
var text = raw.replace(/^```(?:json)?\s*/i, '').replace(/\s*```$/i, '').trim();
if (shape === 'array') {
var m = text.match(/\[[\s\S]*\]/);
if (m) text = m[0];
} else {
var m = text.match(/\{[\s\S]*\}/);
if (m) text = m[0];
}
return text;
}
Open en sluit haakjes automatisch:
var stack = [];
var inStr = false, esc = false;
for (var i = 0; i < text.length; i++) {
var ch = text[i];
if (esc) { esc = false; continue; }
if (ch === '\\') { esc = true; continue; }
if (ch === '"') { inStr = !inStr; continue; }
if (inStr) continue;
if (ch === '{') stack.push('}');
else if (ch === '[') stack.push(']');
else if (ch === '}' || ch === ']') stack.pop();
}
text = text.replace(/,\s*$/, '');
while (stack.length > 0)
text += stack.pop();
Als het model nog steeds geneste structuren retourneert:
if (Array.isArray(value)) {
flat = value.map(function(item) {
if (typeof item === 'string') return item;
if (typeof item === 'object') return Object.values(item).join(' — ');
return String(item);
}).join(', ');
}
Een eenvoudige herhaallus verhoogt de betrouwbaarheid aanzienlijk.
Ministral gedraagt zich bij lage temperatuur consistent, waardoor herprobeerpogingen meestal slagen.
Aanbevolen:
2–3 retry attempts
Ministral houdt van opmaak.
Zelfs wanneer je om platte tekst vraagt, heeft het de neiging om te produceren:
Dit gebeurt omdat het model standaard wordt geleverd met een ingebouwde systeemopdracht die rijke Markdown-opmaak aanmoedigt
Veel pipelines vertrouwen op eenvoudige stringcontroles.
Voorbeeld:
verdict.toUpperCase().startsWith('CORRECT')
Maar als het model teruggeeft:
**CORRECT**
de controle mislukt.
De veiligste aanpak is om alle uitvoer te normaliseren voordat deze wordt verwerkt.
function stripMarkdown(text) {
if (!text) return text;
var s = text.replace(/\*\*([^*]+)\*\*/g, '$1');
s = s.replace(/__([^_]+)__/g, '$1');
s = s.replace(/\*([^*]+)\*/g, '$1');
s = s.replace(/^#{1,6}\s+/gm, '');
s = s.replace(/`([^`]+)`/g, '$1');
s = s.replace(/^```[a-z]*\s*$/gm, '');
return s.trim();
}
Pas dit toe op elke modellevering, niet alleen bij Ministral.
Het vermijdt model-specifieke vertakkingen en houdt pipelines consistent.
Als uw systeem meerdere modelfamilies ondersteunt (Mistral, Qwen, DeepSeek, Llama enz.), is de meest onderhoudbare ontwerpkeuze om het gedrag van de modellen op één plek te centraliseren
Voorbeeld:
function buildModelProfile(modelName) {
var lower = modelName.toLowerCase();
var isMistral = lower.includes('mistral') || lower.includes('ministral');
return {
family: isMistral ? 'Mistral' : 'Generic',
jsonSystemInstruction: isMistral
? 'Respond with ONLY valid JSON. No markdown. Keep values as short plain strings.'
: 'You output only valid JSON. No markdown fences, no explanation.',
jsonSchemaHint: isMistral
? ' Every value MUST be a short plain string — NO arrays, NO nested objects.'
: '',
jsonTemperature: isMistral ? 0.15 : 0.7,
defaultTemperature: isMistral ? 0.15 : 0.7,
plainTextInstruction: ' Do not use markdown formatting.'
};
}
model-onafhankelijk
Het toevoegen van een nieuw model wordt later triviaal.
| Instelling | Aanbevolen Waarde | Reden |
|---|---|---|
| tokenizer_mode | mistral | Vereist voor de juiste tokenizer |
| config_format | mistral | Vereist |
| load_format | mistral | Vereist |
| chat_template_kwargs | Niet verzenden | Niet ondersteund |
| temperatuur | 0.15 | Voorkomt structurele hallucinaties |
| JSON-instructie | Expliciete platte waarden | Vermijd geneste objecten |
| max_tokens | 1,5–2× gebruikelijk | Het model is uitvoerig |
| Markdown verwijdering | Altijd | Voorkom formateringsfouten |
| JSON-pogingen | 2–3 pogingen | Betrouwbare herstel |
Ministral-3 presteert uitzonderlijk goed wanneer het correct is afgestemd.
Zodra je:
opmerkelijk voorspelbaar en kant-en-klaar voor productieomgevingen
In onze Jeopardy benchmark ondersteunde deze setup:
Alle draait lokaal op de Trooper.AI GPU-infrastructuur.
Probeer de volledige vLLM-deploymentsjabloon hier uit: vLLM OpenAI-compatibele server
Huur vandaag nog uw eigen GPU-server en begin met het bouwen van geweldige AI-applicaties! Trooper.AI GPU-servers zijn gebouwd met uitsluitend gerecyclede high-end technologie van de afgelopen jaren, ontworpen om u de beste prestaties, beveiliging en betrouwbaarheid te bieden voor al uw AI-behoeften.
EU-locatie · Hoge privacy · Geweldige prestaties · Beste ondersteuning