vLLM OpenAI-Compatibele Server
Trooper.AI biedt een volledig geautomatiseerde vLLM-implementatiesjabloon dat een OpenAI-compatibele inferentieserver op uw GPU-server installeert, configureert en uitvoert met behulp van systemd.
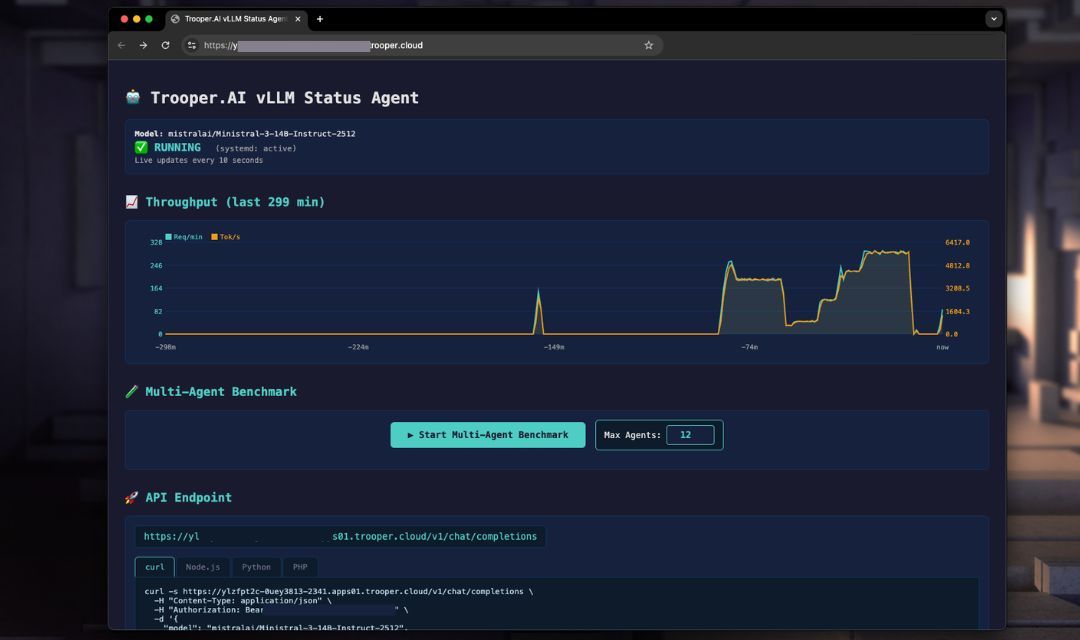
Het doel:
- Maximale doorvoersnelheid
- Automatische GPU-architectuur afstemming
- OpenAI-compatibele API
- Productieveilig standaardinstellingen
- Geen handmatige GPU-tuning vereist
De sjabloon voert automatisch uit:
- Detecteert GPU-architectuur en VRAM
- Selecteert de optimale precisie (FP16 / BF16 / FP8)
- Optimaliseert batching en concurrency
- Installeert vLLM in een virtuele omgeving
- Creëert een permanente systemd-service
- Stelt OpenAI-compatibele eindpunten bloot
- Benchmarkprestaties om parameters af te stemmen
U heeft alleen controle over een kleine set openbare parameters.
GPU-aantallen begrijpen: vLLM werkt met meerdere GPUs, maar vereist dat het aantal GPUs gelijkmatig deelbaar is door het aantal aandachtskoppen van het model. Bijvoorbeeld: een model zoals Gemma met 32 aandachtskoppen kan werken met 1, 2, 4 of 8 GPUs – maar niet met 3.
Belangrijke beveiligingsopmerking over schermafdrukken: De servers die op de schermafdrukken zijn weergegeven dienen enkel demonstratiedoeleinden en worden beschermd door de Trooper.AI Network-Level Firewall, welke standaard wordt meegeleverd bij alle GPU Server-bestellingen. Voor gedetailleerde informatie, zie 🛡️ Trooper.AI aanpasbare Network-Level Firewall
Instellingen van vLLM-template
Deze sjabloon deployt een kant-en-klaar vLLM inferentie-server op uw Trooper.AI-instance. Hiermee wordt de vereiste runtime geïnstalleerd, de API-endpoint geconfigured en het model voorbereid op OpenAI-compatibele verzoeken.
Hieronder vindt u een korte uitleg van elke configuratieoptie.
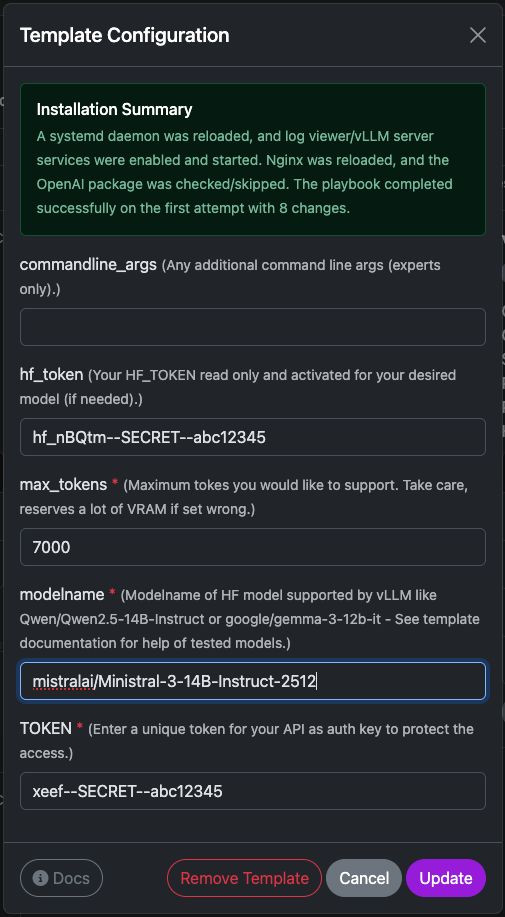
commandline_args
Optionele geavanceerde argumenten die rechtstreeks worden doorgegeven aan de opstartcommando van de vLLM-server
Gebruik dit als u extra functies wilt inschakelen:
- tensor parallelisme
- kwantisatie
- tool aanroepen
- aangepaste tokenizer-instellingen
- speculatieve decoding
Voorbeeld:
--tensor-parallel-size 2
Laat leeg, tenzij u precies weet welke vlaggen u wilt gebruiken.
hf_token
Je Hugging Face-toegangstoken
Dit is vereist als het model:
- beperkt toegankelijk
- authenticatie
- of uit een privé-repository
Voor openbare modellen kan dit veld leeg worden gelaten.
U kunt hier een token genereren:
https://huggingface.co/settings/tokens
Het token wordt alleen gebruikt tijdens het downloaden van het model.
max_tokens
definieert het maximale contextvenster dat de server moet ondersteunen.
VRAM-gebruik
Typische waarden:
| Context | Aanbevolen |
|---|---|
| kleine modellen | 4096 |
| gemiddelde modellen | 8192 |
| modellen met lange context | 16384+ |
Hogere waarden verhogen het geheugengebruik aanzienlijk. Als uw server geen VRAM meer heeft, verlaag dan deze waarde.
modelnaam
De HuggingFace-modelidentificatie die vLLM moet laden.
Voorbeeld:
mistralai/Ministral-3-14B-Instruct-2512
Andere compatibele voorbeelden:
Qwen/Qwen2.5-14B-Instruct
google/gemma-3-12b-it
meta-llama/Meta-Llama-3-8B-Instruct
... and many more
Zorg ervoor dat het model wordt ondersteund door vLLM en in het geheugen van uw GPU past.
TOKEN
Dit is uw API-authenticatie sleutel.
Alle verzoeken naar de vLLM-server moeten deze token in de header bevatten:
Authorization: Bearer YOUR_TOKEN
Dit beschermt uw server tegen ongeautoriseerde toegang.
Voorbeeld aanvraag:
curl https://your-server/v1/chat/completions \
-H "Authorization: Bearer YOUR_TOKEN"
Gebruik een sterke willekeurige string.
Modelgrootte & GPU-vereisten
U kunt een breed scala aan grote taalmodellen van HuggingFace gebruiken binnen vLLM. Zorg ervoor dat er voldoende VRAM beschikbaar is, aangezien de prestaties afhangen van voldoende vrije GPU VRAM om het model en de contextgrootte te accommoderen, vermenigvuldigd met het aantal gelijktijdige gebruikers.
Trooper.AI selecteert automatisch de optimale precisie per GPU-architectuur.
VRAM-berekening: Gewichten van het model + ~25% KV-Cache-buffer.
VRAM kan worden gedeeld over meerdere GPUs via tensor parallelisme (--tensor-parallel-size N).
| Model | Parameters | Precisie | Min. VRAM Totaal | GPU Configuratie | GPU's |
|---|---|---|---|---|---|
| Qwen/Qwen3-4B | 4B | BF16 | ~8 GB | 1× V100 16GB / RTX 4070 Ti Super | 1 |
| Qwen/Qwen3-8B | 8B | BF16 | ~20 GB | 1× RTX 3090 / RTX 4090 (24 GB) | 1 |
| mistralai/Ministral-3-14B-Instruct-2512 | 14B | FP8 | ~29 GB | 1× RTX 4080 Pro 32GB of 1× A100 40GB | 1 |
| Qwen/Qwen3-32B | 32B | FP8 | ~40 GB | 1× A100 40GB of 2× RTX 4090 (2×24 GB) | 1–2 |
| meta-llama/Llama-3.1-8B-Instruct | 8B | FP8 | ~20 GB | 1× RTX 3090 / RTX 4090 (24 GB) | 1 |
| meta-llama/Llama-3.1-70B-Instruct | 70B | FP8 | ~90 GB | 1× RTX Pro 6000 Blackwell (96 GB) of 2× A100 (2×40 GB) | 1–2 |
Opmerking: FP8 wordt gebruikt op Ada/Hopper-architecturen (RTX 40-serie, A100, H100) voor maximaal rendement. Trooper.AI kiest automatisch de optimale precisie voor je GPU.
Configuraties met meerdere GPUs gebruiken Tensor Parallelism – het VRAM schaalt lineair over alle GPUs.
Openbare Parameters
Deze parameters kunnen worden ingesteld via omgevingsvariabelen voordat u de installateur uitvoert.
| Variabele | Beschrijving |
|---|---|
TOKEN |
API-sleutel voor authenticatie |
modelname |
HuggingFace modelpad |
hf_token |
HuggingFace token (voor afgesloten modellen) |
commandline_args |
Optionele extra vLLM CLI argumenten |
Automatische Benchmarking om Parameters af te stemmen
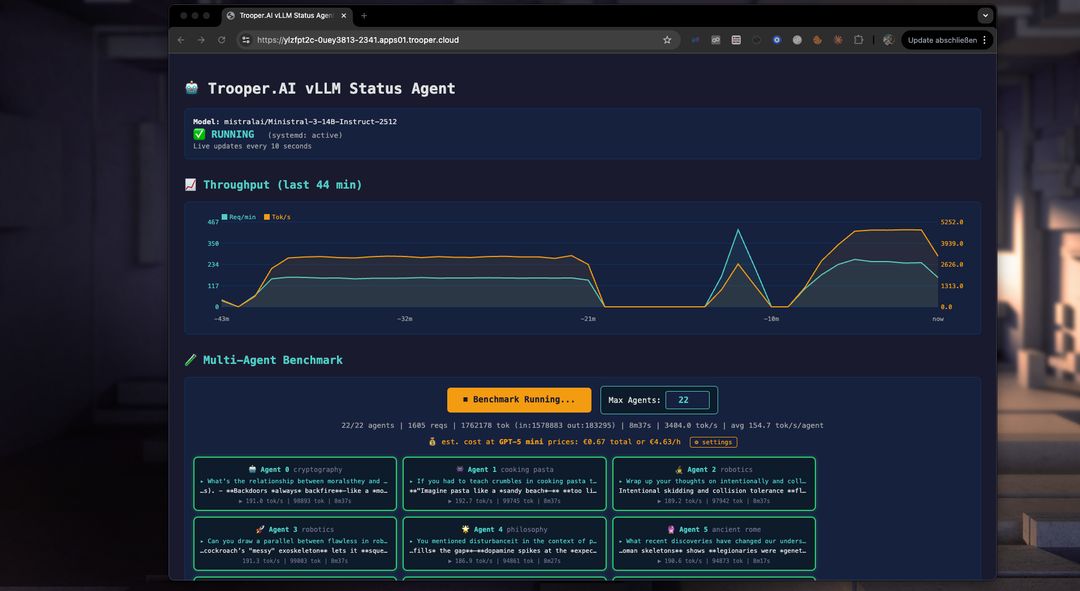
Onze template bevat een performance benchmark om u te helpen uw GPU-server te optimaliseren voor multi-agent gebruik. Gebruik het om modellen, GPU-types en parameters te testen en te vergelijken om de throughput en het aantal gelijktijdige gebruikers te maximaliseren.
Hoe werkt de benchmark?
De benchmark start meerdere agents tegelijkertijd, die elk met het vLLM server eindpunt op een ander onderwerp communiceren. Dit voorkomt caching en test real-world prestaties. U kunt de throughput van elke agent, de totale throughput bekijken en kosten vergelijken voor tokenized services zoals GPT-5 mini. Vaak is een vLLM server van Trooper.AI 2-4x goedkoper dan grote token-based inference services, terwijl uw LLM werk privé blijft!
Wat de Template doet
-
Detecteert GPU-architectuur (Volta, Ampere, Ada, Hopper, Blackwell)
-
Detecteert VRAM-grootte
-
Selecteert automatisch de optimale precisie:
- FP8 > BF16 > FP16
-
Gebruikt FP16 KV-cache voor stabiliteit
-
Instellingen:
- maximale gelijktijdige reeksen
- batch grootte van tokens
- geheugengebruik
-
Installeert vLLM met CUDA
Maakt een systemd-dienst aan:
Codevllm-server.service-
Start een permanente OpenAI-compatibele API-server op een beveiligde HTTPS-endpoint.
Er is geen handmatige afstemming vereist.
API-eindpunten
Basis URL:
http://YOUR_SERVER:PORT/v1
Eindpunten:
/v1/models/v1/completions/v1/chat/completions
Authenticatieheader:
Authorization: Bearer YOUR_TOKEN_FROM_CONFIG
Python Client Voorbeeld
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1"
)
resp = client.chat.completions.create(
model="Qwen/Qwen3-14B",
messages=[
{"role": "user", "content": "Hello, what is vLLM?"}
],
max_tokens=200
)
print(resp.choices[0].message.content)
Node.js Client Voorbeeld
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "YOUR_API_KEY",
baseURL: "https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1"
});
const completion = await client.chat.completions.create({
model: "Qwen/Qwen3-14B",
messages: [
{ role: "user", content: "Hello from Node.js" }
],
max_tokens: 200
});
console.log(completion.choices[0].message.content);
PHP Client Voorbeeld
<?php
$ch = curl_init("https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1/chat/completions");
$data = [
"model" => "Qwen/Qwen3-14B",
"messages" => [
["role" => "user", "content" => "Hello from PHP"]
],
"max_tokens" => 200
];
curl_setopt_array($ch, [
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_HTTPHEADER => [
"Authorization: Bearer YOUR_API_KEY",
"Content-Type: application/json"
],
CURLOPT_POSTFIELDS => json_encode($data)
]);
$response = curl_exec($ch);
curl_close($ch);
echo $response;
Streaming Voorbeeld
Python Streaming
resp = client.chat.completions.create(
model="Qwen/Qwen3-14B",
messages=[{"role":"user","content":"Explain transformers"}],
stream=True
)
for chunk in resp:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Node.js Streaming
const stream = await client.chat.completions.create({
model: "Qwen/Qwen3-14B",
messages: [{ role: "user", content: "Explain transformers" }],
stream: true
});
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0].delta?.content || "");
}
Gebruiksscenario's
Trooper.AI vLLM servers zijn ontworpen voor:
- SaaS AI backends
- Chatbots
- Code-assistenten
- RAG-systemen
- Multi-user inference servers
- Batch-inferentie met hoge doorvoer
- GPU-huur omgevingen
Prestatiefilosofie
Trooper.AI gebruikt:
- Automatische architectuuraanpassing
- Automatische precisiekeuze
- VRAM-bewuste batching
- Stabiele KV-cacheconfiguratie
Dit voorkomt:
- GPU-configuratiefout
- Precisie crashes
- VRAM-fragmentatie
- Context instabiliteit
Kostenvergelijking: Ministral-3 op Trooper.AI vs GPT-5 mini
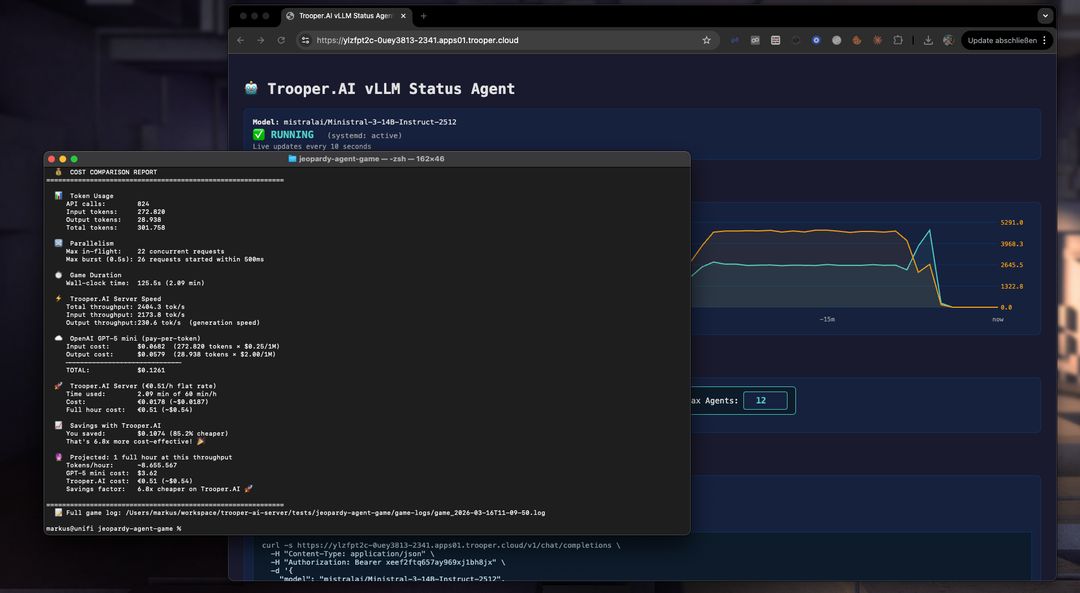
Om een ruw idee te geven van de economie van zelf-hosten, vergelijkt het volgende de kosten van het uitvoeren van Ministral-3-14B-Instruct-2512 op een Trooper.AI GPU-server versus het gebruik van de GPT-5 mini API voor dezelfde workload.
De schatting is gebaseerd op de werkelijke benchmarkrun die in dit artikel wordt beschreven en geëxtrapoleerd naar een uur continue inferentiestroom.
Uurlijk kosten bij gemeten doorvoer
| Platform | Uurkosten |
|---|---|
| GPT-5 mini API | ~$3.12 |
| Ministral-3-14B op een Trooper.AI GPU-server | €0.51 (~$0.54) |
Hoe dit is berekend
Deze schatting is gebaseerd op de werkelijke benchmarksessie uit dit artikel met behulp van Ministral-3-14B-Instruct-2512 op een Trooper.AI GPU-server
| Meetwaarde | Waarde |
|---|---|
| Totaal aantal verwerkte tokens | 307,028 |
| Uitvoeringstijd | 153 seconden |
| Doorvoer | ~2006 tokens/sec |
| Verwachte tokens/uur | ~7,22 miljoen tokens |
Tokenmix in de benchmark:
| Token type | Tokens |
|---|---|
| Invoertokens | 275,186 |
| Uitvoer tokens | 31,842 |
~7,22 miljoen tokens/uur schalen en de prijsstelling van GPT-5 mini toe te passen:
- $0,25 / 1M invoertokens
- $2,00 / 1M output tokens
ongeveer €2,90 per uur
De Ministral-3-server op Trooper.AI draait daarentegen tegen een vast tarief van €0.51/u (~$0.54), ongeacht het aantal tokens, waardoor het mogelijk wordt om miljoenen tokens per uur te verwerken tegen voorspelbare kosten
Projectie van langlopende werklast
Voor een volledige uur
| Meetwaarde | Waarde |
|---|---|
| Tokens per uur | ~7,221,543 |
| GPT-5 mini kosten | $3.12 |
| Trooper.AI serverkosten | €0.51 (~$0.54) |
Uurlijk besparing
Dezelfde workload een uur uitvoeren zou nog steeds zijn:
≈ 5,8× goedkoper op Trooper.AI
Wanneer Self-Hosting Veel Goedkoper Wordt
Self-hosting van LLM's is economisch voordeliger wanneer:
- werklasten bestaan uit veel kleine verzoeken
- parallelle inferentie vereist
- miljoenen tokens per uur
- continue
Typische voorbeelden zijn:
- AI-gamesimulaties
- agentsystemen
- automatiseringspijplijnen
- chattoepassingen met veel gebruikers
Samenvatting
In deze benchmark:
| Meetwaarde | Resultaat |
|---|---|
| Model | Ministral-3-14B |
| Serverkosten | €0.51/hour |
| Verwerkte tokens | 307k |
| Uitvoeringstijd | 153 seconden |
| Kostenverlaging | 82.8% |
| Kostenvoordeel | 5,8× goedkoper dan GPT-5 mini |
Ministral-3 op Trooper.AI GPU-servers uitvoeren kan de kosten voor inferentie drastisch verlagen, terwijl tegelijkertijd API-beperkingen worden opgeheven.
Waarom u de vLLM template nodig heeft
De Trooper.AI vLLM template geeft u:
- OpenAI-compatibele API
- Automatische GPU-optimalisatie
- Productieveilig standaardinstellingen
- Minimale configuratie
- Maximale doorvoersnelheid
Je kiest enkel het model en de API sleutel.
Alles anders wordt automatisch geoptimaliseerd.
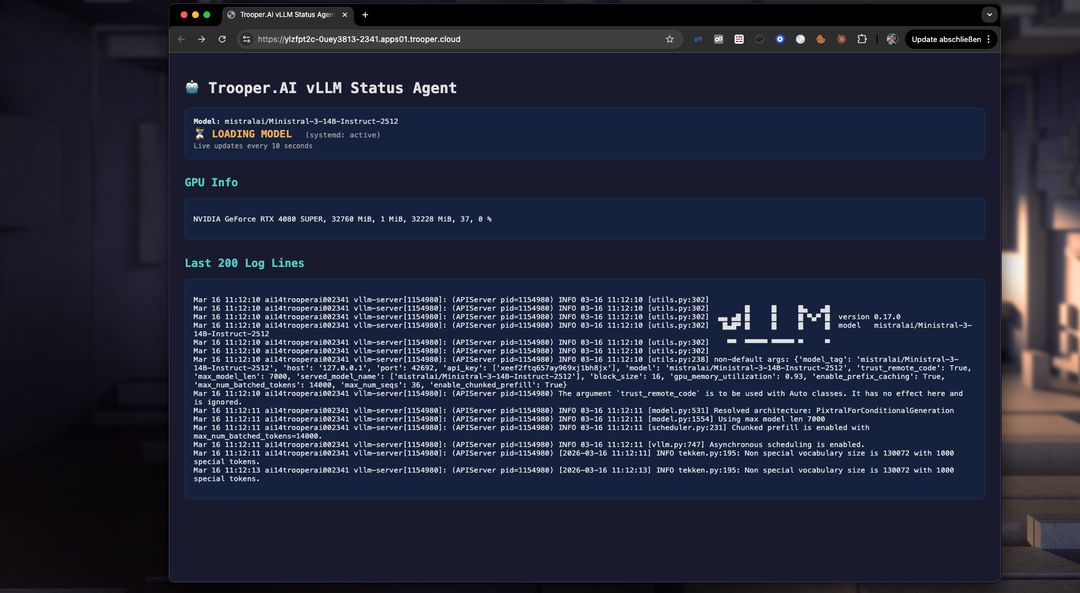
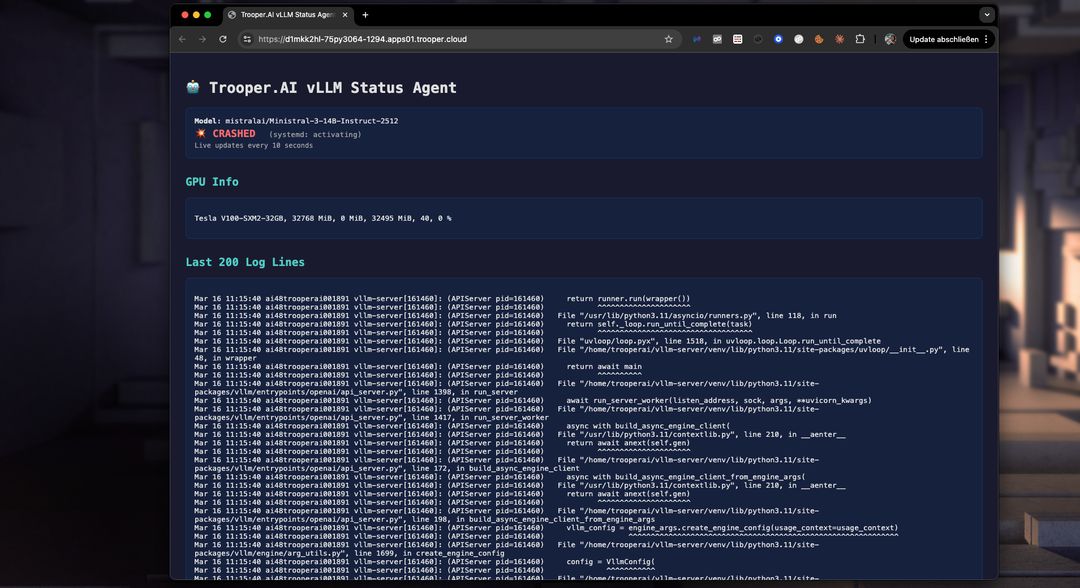
Probleemoplossing
Met het dashboard kunt u eenvoudig problemen bij het opstarten detecteren en oplossen. Niet genoeg VRAM? Upgrade naar een hogere Blib in minuten via het dashboard. Of los het VRAM-gebruik op door de token window size te verlagen. Bekijk de Logs eenvoudig in realtime met het dashboard:
Ministral 3
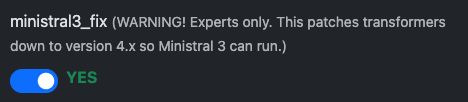
Om Ministral 3 te gebruiken, heb je normaal gesproken Transformers 4.x nodig en dit kan gemakkelijk geforceerd worden met de ‘Ministral 3 Fix’ keuzemogelijkheid in de sjabloonconfiguratie. Opmerking: vLLM is een experttool en u dient te weten hoe u deze optimaliseert en eventuele problemen verhelpt, maar wij bieden zo veel mogelijke ondersteuning.
Schakel eerst de Ministral 3 Fix in:
Ten tweede, gebruik deze parameters om zoveel mogelijk functionaliteit uit het model te halen:
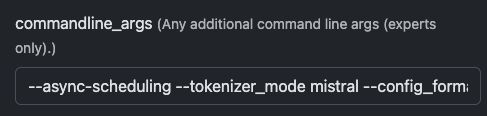
--async-scheduling --tokenizer_mode mistral --config_format mistral --load_format mistral --enable-auto-tool-choice --tool-call-parser mistral --limit-mm-per-prompt='{"image":{"count":4,"width":768,"height":768}}'
Dit start dan Ministral 3 op je server – mits alle andere parameters passen bij de grootte van je VRAM.
Nemotron 3 Nano met Tokensbudget
Voor NVIDIA Nemotron 3 Nano heb je ten minste vLLM versie 0.18.1 nodig (nightly per 2025-03-30). Je kunt de parser en het tokenlimiet configureren om
Wees ervan bewust dat dit de throughput met ongeveer -30% kan verminderen.
Pas `command_line_args` aan naar iets als dit:
--async-scheduling
--reasoning-parser-plugin /home/trooperai/vllm-server/nano_v3_reasoning_parser.py
--reasoning-parser nano_v3
--reasoning-config '{"think_start_str": "<think>", "think_end_str": " - I have to give the solution based on the thinking directly now:</think>"}'
Parser downloaden vanaf:
wget -O - https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16/resolve/main/nano_v3_reasoning_parser.py
Alternatief kun je de optie nemotron_3_parser inschakelen (setten op ON). Dit regelt het voor je. Zorg er ook voor dat je de nachtelijke ontwikkelaarsbuild activeert!
Op deze manier krijg je meer controle over de redeneringsfunctie van NVIDIA Nemotron-3 Nano.
Ondersteuning
Neem voor geavanceerde afstemming, multi-GPU of aangepaste presets contact op met de Trooper.AI support.