Réglage de Ministral-3 sur vLLM
Guide pratique pour les réponses en texte brut et JSON
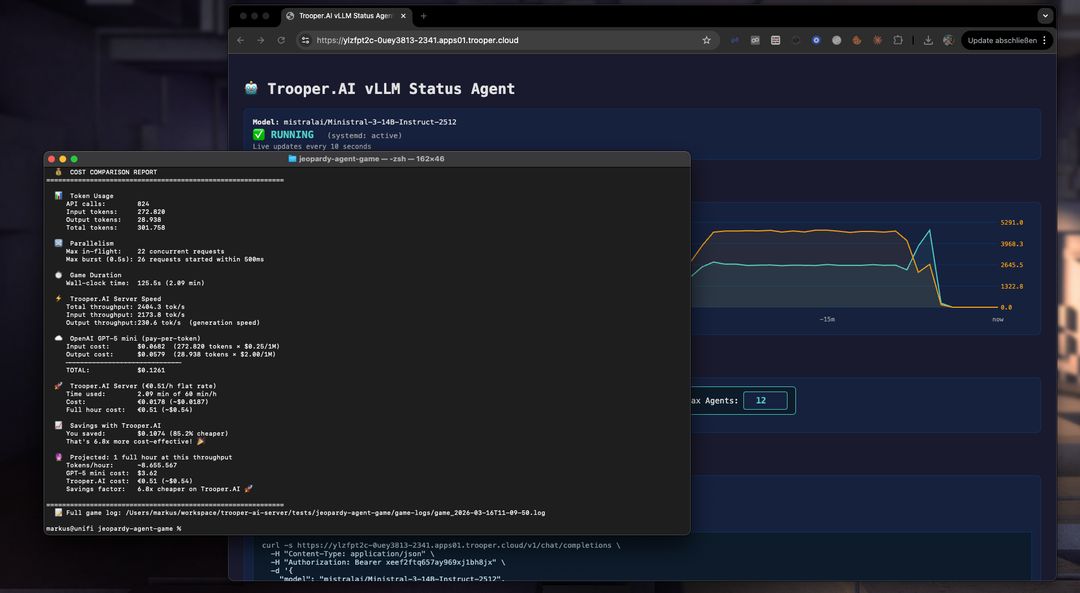
Leçons apprises lors de la construction d’une simulation de jeu Jeopardy à 12 joueurs alimentée par Ministral-3-14B-Instruct-2512.
Guide pratique pour les réponses en texte brut et JSON
Leçons apprises lors de la construction d’une simulation de jeu Jeopardy à 12 joueurs alimentée par Ministral-3-14B-Instruct-2512.
Exécuter Ministral-3 sur vLLM est surprenantement puissant. Le modèle est rapide, créatif et capable de produire des réponses de haute qualité, même sous forte charge.
Mais dès que l’on passe des invites de discussion simples à des sorties structurées, automatisation ou utilisation programmatique, les choses deviennent rapidement complexes.
Développement d'un jeu de type Jeopardy piloté par IA avec 12 joueurs simultanés et des centaines d'appels au modèle
Ce guide résume les leçons pratiques tirées de la résolution de ces problèmes, ainsi que des modèles concrets réutilisables dans vos propres projets.
Notre projet de référence simule un jeu complet de Jeopardy où :
Une seule partie peut facilement dépasser 800 appels d'API.
Cet environnement a révélé des cas limites qui apparaissent rarement dans les démonstrations simples — en faisant un excellent banc d'essai pour comprendre comment Ministral se comporte sous de réelles charges de travail en production.
Les modèles Ministral n’utilisent pas la configuration de tokeniseur standard de HuggingFace.
Cela signifie que la commande de lancement doit explicitement activer le format de tokeniseur Mistral.
vllm serve mistralai/Ministral-3-14B-Instruct-2512 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral
Si votre application repose sur l'appel de fonctions, ajoutez les drapeaux d'outil suivants :
--enable-auto-tool-choice
--tool-call-parser mistral
Contrairement à d'autres modèles, Ministral ne prend pas en charge chat_template_kwargs
Si vous envoyez une requête comme celle-ci :
{
"chat_template_kwargs": {
"enable_thinking": false
}
}
vLLM renvoie :
HTTP 400: chat_template is not supported for Mistral tokenizers
Cela signifie que des fonctionnalités comme le basculement en mode de réflexion explicite (utilisé avec des modèles tels que Qwen ou DeepSeek) sont simplement indisponibles
Heureusement, ce n'est que rarement nécessaire car Ministral produit déjà des sorties concises par défaut.
La documentation officielle de vLLM utilise systématiquement la valeur suivante avec Ministral-3 :
temperature = 0.15
À première vue, cette valeur semble extrêmement faible. Pourtant, elle s'avère être critique pour les tâches structurées.
En utilisant la valeur par défaut de type OpenAI :
temperature: 0.7
trop créatif au niveau de la structure
Une simple requête comme :
{ "expertise": "2-3 topics they know best" }
peut renvoyer quelque chose comme :
{
"expertise": [
{
"category": "Gourmet Pizza Alchemy",
"detail": "Can transform random ingredients into Michelin-star pizza"
},
{
"category": "Sumo Wrestling Physics",
"detail": "Understands body mechanics and center-of-gravity combat"
}
]
}
Ce n'est pas ce que le schéma demandait
Le résultat :
max_tokens les limites sont dépassées0.15 fonctionne mieuxstructurellement rigoureux
temperature: 0.15
Avantages :
Même la génération de texte créatif reste performante — le modèle cesse simplement d'improviser avec la structure.
Recommandation :
Utilisez temperature : 0,15 comme valeur par défaut pour Ministral-3.
Générer un JSON lisible par machine à partir des modèles de langage est plus difficile qu'il n'y paraît.
Ministral tend à interpréter les champs de schéma de manière sémantique plutôt que structurale, ce qui conduit à des sorties profondément imbriquées.
Une invite comme :
Return JSON with these fields.
produit souvent des structures verbeuses.
Exemple de requête :
{ "expertise": "2-3 topics they know best" }
Réponse typique :
{
"expertise": [
{
"category": "Ancient Roman Engineering",
"detail": "Knows aqueduct systems in surprising detail"
},
{
"category": "Pizza Dough Chemistry",
"detail": "Obsessed with yeast fermentation dynamics"
}
]
}
Cela consomme trois fois plus de jetons que prévu
La solution la plus fiable combine deux consignes.
Respond with ONLY valid JSON.
No markdown, no explanation, no text before or after the JSON.
Keep values as short plain strings — never use nested objects or arrays.
Juste à côté de la définition du schéma :
Every value MUST be a short plain string — NO arrays, NO nested objects.
Associé à une température de 0,15, cela génère un JSON plat et prévisible.
Des valeurs plus longues que les autres modèles
Exemple d'observation de notre référence :
| Modèle | Jetons nécessaires |
|---|---|
| GPT-4o | ~512 |
| Qwen | ~512 |
| Ministral-3 | ~1024 |
Une règle de sécurité :
Prévoir un budget de 1,5 à 2 fois le nombre de jetons pour les sorties en format JSON.
Même avec des invites parfaites, les modèles génèrent occasionnellement du JSON malformé.
Une bonne stratégie consiste à ajouter des couches de parsing défensif.
function extractJSON(raw, shape) {
var text = raw.replace(/^```(?:json)?\s*/i, '').replace(/\s*```$/i, '').trim();
if (shape === 'array') {
var m = text.match(/\[[\s\S]*\]/);
if (m) text = m[0];
} else {
var m = text.match(/\{[\s\S]*\}/);
if (m) text = m[0];
}
return text;
}
Suivre les crochets ouverts et les fermer automatiquement :
var stack = [];
var inStr = false, esc = false;
for (var i = 0; i < text.length; i++) {
var ch = text[i];
if (esc) { esc = false; continue; }
if (ch === '\\') { esc = true; continue; }
if (ch === '"') { inStr = !inStr; continue; }
if (inStr) continue;
if (ch === '{') stack.push('}');
else if (ch === '[') stack.push(']');
else if (ch === '}' || ch === ']') stack.pop();
}
text = text.replace(/,\s*$/, '');
while (stack.length > 0)
text += stack.pop();
Si le modèle renvoie encore des structures imbriquées :
if (Array.isArray(value)) {
flat = value.map(function(item) {
if (typeof item === 'string') return item;
if (typeof item === 'object') return Object.values(item).join(' — ');
return String(item);
}).join(', ');
}
Une simple boucle de nouvelles tentatives augmente considérablement la fiabilité.
Ministral se comporte de manière cohérente à basse température, les tentatives de réessai aboutissent généralement.
Recommandé :
2–3 retry attempts
Ministral adore le formatage.
Même lorsque vous demandez du texte brut, il a tendance à produire :
Le modèle est livré avec une invite système intégrée qui encourage le formatage Markdown riche.
De nombreux pipelines s'appuient sur des vérifications de chaînes de caractères simples.
Exemple :
verdict.toUpperCase().startsWith('CORRECT')
Mais si le modèle renvoie :
**CORRECT**
la vérification échoue.
L’approche la plus sûre consiste à normaliser toutes les sorties avant le traitement.
function stripMarkdown(text) {
if (!text) return text;
var s = text.replace(/\*\*([^*]+)\*\*/g, '$1');
s = s.replace(/__([^_]+)__/g, '$1');
s = s.replace(/\*([^*]+)\*/g, '$1');
s = s.replace(/^#{1,6}\s+/gm, '');
s = s.replace(/`([^`]+)`/g, '$1');
s = s.replace(/^```[a-z]*\s*$/gm, '');
return s.trim();
}
Appliquez ceci à toutes les réponses de modèle, et pas seulement pour Ministral.
Cela évite les branchements spécifiques aux modèles et maintient la cohérence des pipelines.
Si votre système prend en charge plusieurs familles de modèles (Mistral, Qwen, DeepSeek, Llama, etc.), la conception la plus maintenable consiste à centraliser le comportement des modèles dans un seul endroit.
Exemple :
function buildModelProfile(modelName) {
var lower = modelName.toLowerCase();
var isMistral = lower.includes('mistral') || lower.includes('ministral');
return {
family: isMistral ? 'Mistral' : 'Generic',
jsonSystemInstruction: isMistral
? 'Respond with ONLY valid JSON. No markdown. Keep values as short plain strings.'
: 'You output only valid JSON. No markdown fences, no explanation.',
jsonSchemaHint: isMistral
? ' Every value MUST be a short plain string — NO arrays, NO nested objects.'
: '',
jsonTemperature: isMistral ? 0.15 : 0.7,
defaultTemperature: isMistral ? 0.15 : 0.7,
plainTextInstruction: ' Do not use markdown formatting.'
};
}
Cela permet au reste de votre système de rester modèle-agnostique.
L'ajout d'un nouveau modèle devient trivial.
| Paramètre | Valeur recommandée | Raison |
|---|---|---|
| tokenizer_mode | mistral | Requis pour le tokenizer correct |
| config_format | mistral | Requis |
| load_format | mistral | Requis |
| chat_template_kwargs | Ne pas envoyer | Non pris en charge |
| température | 0.15 | Empêche les hallucinations structurelles |
| Instruction JSON | Valeurs explicites et plates | Évitez les objets imbriqués |
| max_tokens | 1,5–2× typique | Le modèle est verbeux |
| Suppression du Markdown | Toujours | Éviter les erreurs de formatage |
| Nouvelles tentatives JSON | 2–3 tentatives | Récupération fiable |
Ministral-3 fonctionne extrêmement bien lorsqu'il est correctement réglé.
Une fois que vous :
remarquablement prévisible et prêt pour la production
Dans notre évaluation Jeopardy, cette configuration a pris en charge :
L'infrastructure GPU Trooper.AI, tout exécuté en local.
Essayez le modèle de déploiement complet vLLM ici : Serveur compatible OpenAI vLLM
Louez votre propre serveur GPU dès aujourd'hui et commencez à développer des applications d'IA incroyables ! Les serveurs GPU Trooper.AI sont construits à partir de technologies haut de gamme entièrement recyclées des dernières années, conçus pour vous offrir les meilleures performances, sécurité et fiabilité pour tous vos besoins en IA.
Localisation dans l'UE · Haute confidentialité · Excellentes performances · Meilleur support