Serveur compatible vLLM OpenAI
Trooper.AI fournit un modèle de déploiement vLLM entièrement automatisé qui installe, configure et exécute un serveur d'inférence compatible OpenAI sur votre serveur GPU en utilisant systemd.
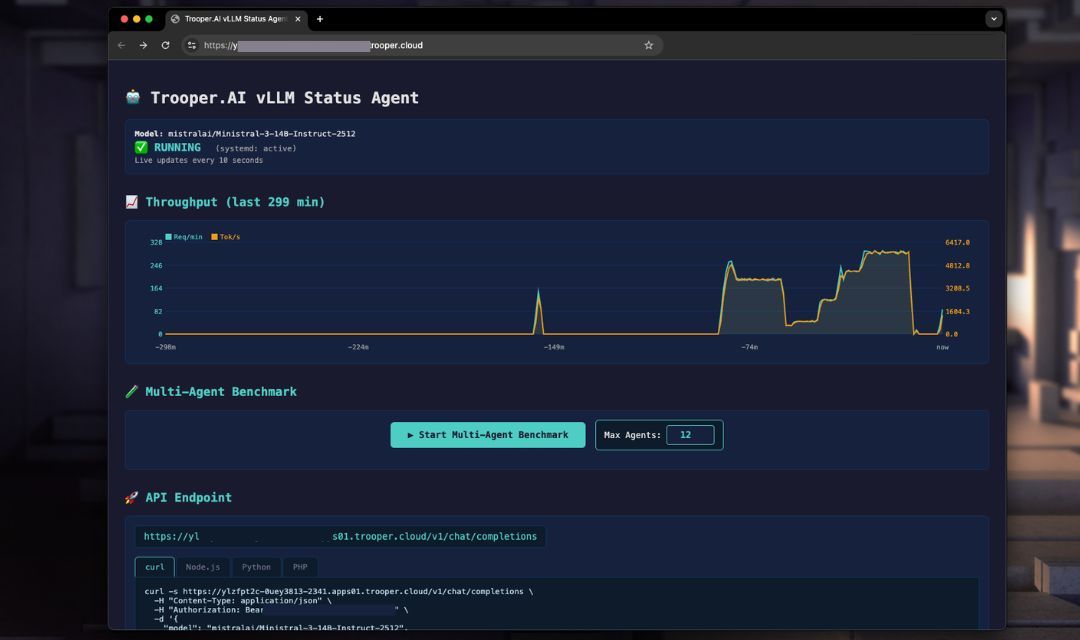
L'objectif :
- Débit maximal
- Réglage automatique de l'architecture du GPU
- API compatible OpenAI
- Valeurs par défaut garantissant la stabilité en production
- Aucun réglage manuel du GPU requis
Le modèle automatique :
- Détecte l’architecture du GPU et la VRAM
- Sélectionne la précision optimale (FP16 / BF16 / FP8)
- Optimise le traitement par lots et la concurrence
- Installe vLLM dans un environnement virtuel
- Crée un service systemd persistant
- Expose des points de terminaison compatibles OpenAI
- Évaluer les performances pour affiner les paramètres
Vous ne contrôlez qu'un petit ensemble de paramètres publics.
Comprendre les nombres de GPU : vLLM fonctionne avec plusieurs GPU, mais il nécessite que le nombre de GPU divise exactement le nombre de têtes d’attention du modèle. Par exemple, un modèle comme Gemma, qui possède 32 têtes d’attention, peut utiliser 1, 2, 4 ou 8 GPU – mais pas 3.
Avis important sur les captures d’écran : Les serveurs présentés dans ces captures sont uniquement à des fins démonstratives et sont sécurisés par le pare-feu réseau de niveau Trooper.AI, inclus avec toutes les commandes de serveurs GPU. Pour plus de détails, voir 🛡️ Pare-feu réseau personnalisable Trooper.AI
Paramètres du modèle vLLM
Ce modèle déploie un serveur d'inférence vLLM prêt à l'emploi sur votre instance Trooper.AI. Il installe le runtime requis, configure le point de terminaison (endpoint) de l'API et prépare le modèle pour des requêtes compatibles avec OpenAI.
Voici une brève explication de chaque option de configuration.
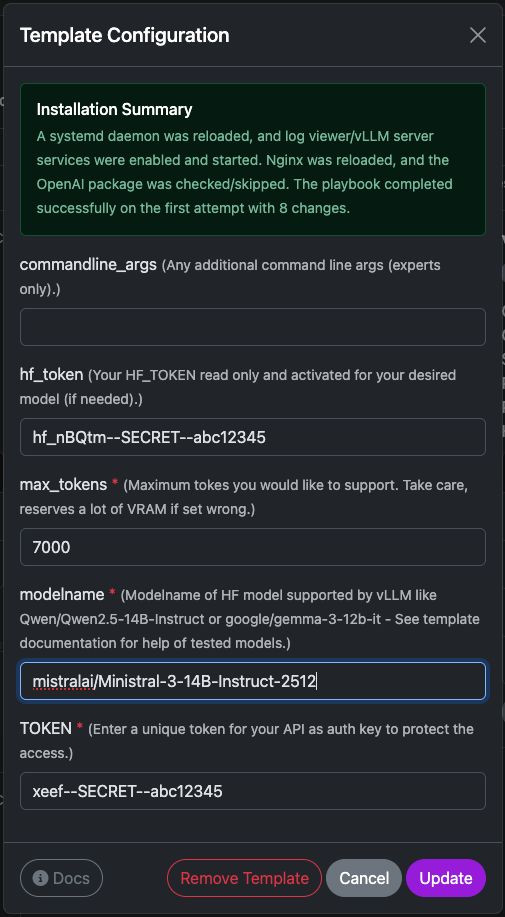
commandline_args
Arguments avancés optionnels passés directement à la commande de démarrage du serveur vLLM.
Utilisez ceci si vous devez activer des fonctionnalités supplémentaires telles que :
- parallélisme tenseur
- quantification
- appel d'outils
- paramètres de tokenizer personnalisés
- décodage spéculatif
Exemple :
--tensor-parallel-size 2
Laisser vide à moins que vous ne sachiez exactement quels indicateurs vous souhaitez utiliser.
hf_token
Votre jeton d’accès Hugging Face
Ceci est requis si le modèle :
- nécessite une autorisation
- une authentification
- ou est téléchargé depuis un dépôt privé
Pour les modèles publics, ce champ peut être laissé vide.
Vous pouvez générer un jeton ici :
https://huggingface.co/settings/tokens
Le jeton n'est utilisé que pendant le téléchargement du modèle.
max_tokens
Définit la fenêtre de contexte maximale que le serveur doit prendre en charge.
Cela affecte directement l'utilisation de la VRAM.
Valeurs typiques :
| Contexte | Recommandé |
|---|---|
| petits modèles | 4096 |
| modèles moyens | 8192 |
| modèles de contexte long | 16384+ |
Des valeurs plus élevées augmentent considérablement l'utilisation de la mémoire. Si votre serveur manque de VRAM, diminuez cette valeur.
nom du modèle
L'identifiant du modèle Hugging Face que vLLM doit charger.
Exemple :
mistralai/Ministral-3-14B-Instruct-2512
Autres exemples compatibles :
Qwen/Qwen2.5-14B-Instruct
google/gemma-3-12b-it
meta-llama/Meta-Llama-3-8B-Instruct
... and many more
Assurez-vous que le modèle est pris en charge par vLLM et qu'1il tient dans la mémoire de votre GPU.
JETON
Voici votre clé d’authentification API.
Toutes les requêtes au serveur vLLM doivent inclure ce jeton dans l'en-tête :
Authorization: Bearer YOUR_TOKEN
Ceci protège votre serveur contre les accès non autorisés.
Exemple de requête :
curl https://your-server/v1/chat/completions \
-H "Authorization: Bearer YOUR_TOKEN"
Utilisez une chaîne aléatoire forte.
Taille du modèle et exigences GPU
Vous pouvez utiliser une large gamme de grands modèles de langage de HuggingFace au sein de vLLM. Assurez-vous qu'il y ait suffisamment de VRAM disponible, car la performance dépend de la quantité de VRAM GPU libre disponible pour accueillir la taille du modèle et du contexte, multipliée par le nombre d'utilisateurs simultanés.
Trooper.AI sélectionne automatiquement la précision optimale en fonction de l’architecture du GPU.
Calcul de la VRAM : Poids du modèle + ~25 % de mémoire tampon (KV-Cache).
La VRAM peut être mutualisée entre plusieurs GPU via le Tensor Parallelism (--tensor-parallel-size N).
| Modèle | Paramètres | Précision | VRAM totale min. | Configuration GPU | GPU |
|---|---|---|---|---|---|
| Qwen/Qwen3-4B | 4B | BF16 | ~8 GB | 1× V100 16GB / RTX 4070 Ti Super | 1 |
| Qwen/Qwen3-8B | 8B | BF16 | ~20 GB | 1× RTX 3090 / RTX 4090 (24 Go) | 1 |
| mistralai/Ministral-3-14B-Instruct-2512 | 14B | FP8 | ~29 GB | 1× RTX 4080 Pro 32GB ou 1× A100 40GB | 1 |
| Qwen/Qwen3-32B | 32B | FP8 | ~40 GB | 1× A100 40GB ou 2× RTX 4090 (2×24 GB) | 1–2 |
| meta-llama/Llama-3.1-8B-Instruct | 8B | FP8 | ~20 GB | 1× RTX 3090 / RTX 4090 (24 Go) | 1 |
| meta-llama/Llama-3.1-70B-Instruct | 70B | FP8 | ~90 GB | 1× RTX Pro 6000 Blackwell (96 Go) ou 2× A100 (2×40 Go) | 1–2 |
Note : FP8 est utilisé sur les architectures Ada/Hopper (RTX 40 Series, A100, H100) pour un débit maximal. Trooper.AI choisit automatiquement la précision optimale pour votre GPU.
Les configurations multi-GPUs exploitent le Tensor Parallelism — la VRAM se scale linéairement à travers les GPUs.
Paramètres publics
Ces paramètres peuvent être définis via les variables d'environnement avant d'exécuter le programme d'installation.
| Variable | Description |
|---|---|
TOKEN |
Clé d'API pour l'authentification |
modelname |
Chemin du modèle HuggingFace |
hf_token |
Token HuggingFace (pour les modèles restreints) |
commandline_args |
Arguments CLI vLLM supplémentaires |
Banc d'essai automatique pour l'optimisation des paramètres
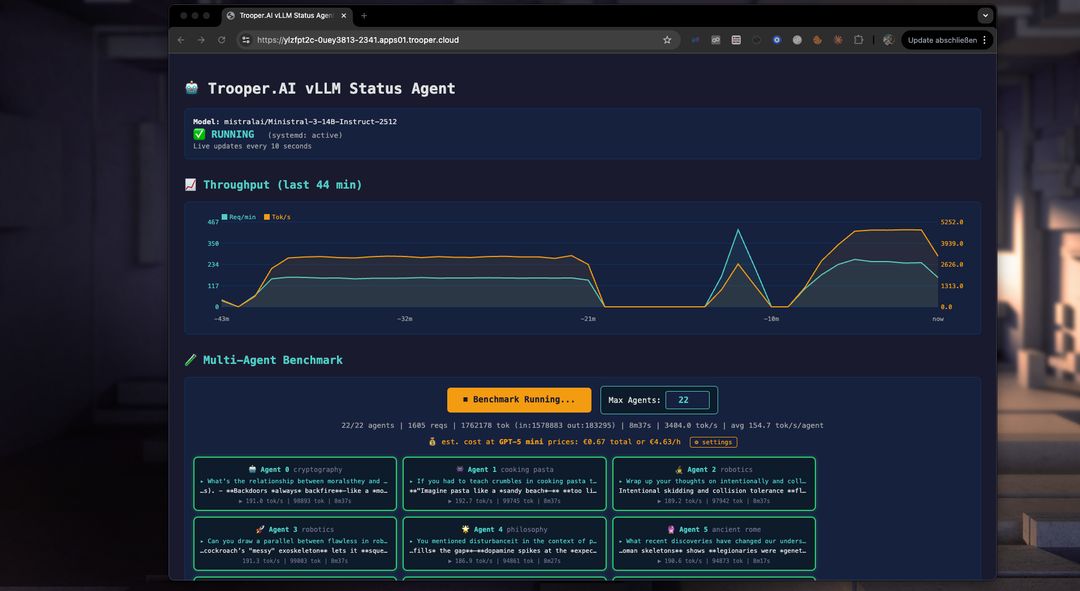
Notre modèle inclut un test de performance pour vous aider à optimiser votre serveur GPU pour une utilisation multi-agents. Utilisez-le pour tester et comparer les modèles, les types de GPU et les paramètres afin de maximiser le débit et le nombre d'utilisateurs simultanés.
Comment fonctionne le benchmark ?
Le benchmark lance plusieurs agents simultanément, chacun interagissant avec le point de terminaison du serveur vLLM sur un sujet différent. Cela empêche la mise en cache et teste les performances en conditions réelles. Vous pouvez voir le débit de chaque agent, le débit total et comparer les coûts des services basés sur des tokens comme GPT-5 mini. Souvent, un serveur vLLM de Trooper.AI est 2 à 4 fois moins cher que les grands services d'inférence basés sur des tokens tout en gardant votre travail LLM privé !
Ce que fait le modèle
-
Détecte l'architecture GPU (Volta, Ampere, Ada, Hopper, Blackwell)
-
Détecte la taille de la VRAM
-
Sélectionne automatiquement la précision optimale :
- FP8 > BF16 > FP16
-
Utilise le cache KV FP16 pour la stabilité
-
Régler :
- séquences concurrentes maximales
- taille des lots de jetons
- utilisation de la mémoire
-
Installe vLLM avec CUDA
Crée un service systemd :
Codevllm-server.service-
Démarre un serveur d'API compatible OpenAI, persistant, sur un point de terminaison HTTPS sécurisé.
Aucun réglage manuel n'est requis.
Points de terminaison de l’API
URL de base :
http://YOUR_SERVER:PORT/v1
Points de terminaison:
/v1/models/v1/completions/v1/chat/completions
En-tête d'authentification :
Authorization: Bearer YOUR_TOKEN_FROM_CONFIG
Exemple de client Python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1"
)
resp = client.chat.completions.create(
model="Qwen/Qwen3-14B",
messages=[
{"role": "user", "content": "Hello, what is vLLM?"}
],
max_tokens=200
)
print(resp.choices[0].message.content)
Exemple de client Node.js
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "YOUR_API_KEY",
baseURL: "https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1"
});
const completion = await client.chat.completions.create({
model: "Qwen/Qwen3-14B",
messages: [
{ role: "user", content: "Hello from Node.js" }
],
max_tokens: 200
});
console.log(completion.choices[0].message.content);
Exemple de client PHP
<?php
$ch = curl_init("https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1/chat/completions");
$data = [
"model" => "Qwen/Qwen3-14B",
"messages" => [
["role" => "user", "content" => "Hello from PHP"]
],
"max_tokens" => 200
];
curl_setopt_array($ch, [
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_HTTPHEADER => [
"Authorization: Bearer YOUR_API_KEY",
"Content-Type: application/json"
],
CURLOPT_POSTFIELDS => json_encode($data)
]);
$response = curl_exec($ch);
curl_close($ch);
echo $response;
Exemple de streaming
Streaming Python
resp = client.chat.completions.create(
model="Qwen/Qwen3-14B",
messages=[{"role":"user","content":"Explain transformers"}],
stream=True
)
for chunk in resp:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Streaming Node.js
const stream = await client.chat.completions.create({
model: "Qwen/Qwen3-14B",
messages: [{ role: "user", content: "Explain transformers" }],
stream: true
});
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0].delta?.content || "");
}
Cas d'utilisation
Les serveurs vLLM de Trooper.AI sont conçus pour :
- Backends d'IA SaaS
- Chatbots
- Assistants de code
- Systèmes RAG
- Serveurs d'inférence multi-utilisateurs
- Inférence par lots à haut débit
- Environnements de location de GPU
Philosophie de la performance
Trooper.AI utilise :
- Réglage automatique de l'architecture
- Sélection automatique de la précision
- Regroupement tenant compte de la VRAM
- Configuration du cache KV stable
Cela permet d’éviter :
- Mauvaise configuration du GPU
- Plantages de précision
- Fragmentation de la VRAM
- Instabilité contextuelle
Comparaison des coûts : Ministral-3 sur Trooper.AI vs GPT-5 mini
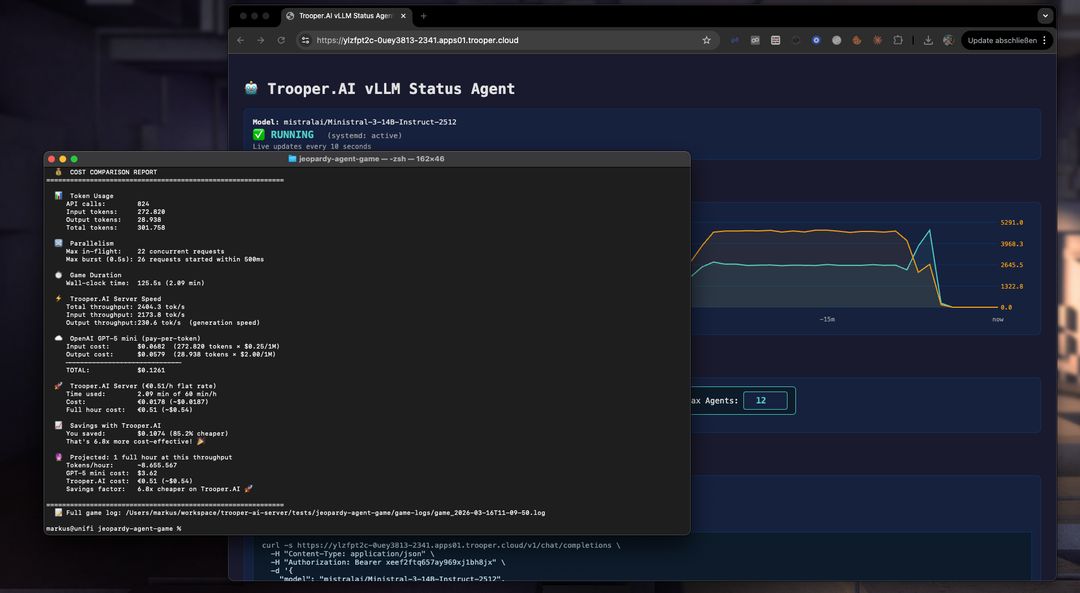
Pour donner une idée approximative de l'économie de l'auto-hébergement, la comparaison suivante projette le coût de l'exécution de Ministral-3-14B-Instruct-2512 sur un serveur GPU Trooper.AI par rapport à l'utilisation de l'API GPT-5 mini pour la même charge de travail.
L'estimation est basée sur l'exécution réelle du benchmark décrite dans cet article et extrapolée à une heure de débit d'inférence continu.
Coût horaire au débit mesuré
| Plateforme | Coût horaire |
|---|---|
| API GPT-5 mini | ~$3.12 |
| Ministral-3-14B sur un serveur GPU Trooper.AI | €0.51 (~$0.54) |
Comment cela a été calculé
Cette estimation repose sur le test de référence réel effectué dans cet article avec Ministral-3-14B-Instruct-2512 sur un serveur GPU Trooper.AI.
| Mesure | Valeur |
|---|---|
| Nombre total de jetons traités | 307,028 |
| Temps d'exécution | 153 secondes |
| Débit | ~2006 tokens/sec |
| Tokens/heure projetés | ~7,22 millions de tokens |
Répartition des jetons dans le benchmark :
| Type de jeton | Jetons |
|---|---|
| Tokens d'entrée | 275,186 |
| Tokens de sortie | 31,842 |
En extrapolant ce rapport à un débit de ~7,22 M de jetons/heure et en appliquant le tarif de GPT-5 mini :
- 0,25 € / 1 million de jetons d'entrée
- 2,00 $ / 1M tokens de sortie
résulte en un coût estimé à ~€3,12 par heure pour la même charge de travail.
Le serveur Ministral-3 sur Trooper.AI fonctionne quant à lui à un tarif forfaitaire de €0,51/heure (~$0,54), indépendamment du volume de jetons traités, ce qui permet le traitement de des millions de jetons par heure à coût prévisible.
Projection de charge de travail de longue durée
En utilisant le débit observé, nous pouvons estimer le coût d’exécution du système pour une heure complète.
| Mesure | Valeur |
|---|---|
| Jetons par heure | ~7,221,543 |
| Coût GPT-5 mini | $3.12 |
| Coût du serveur Trooper.AI | €0.51 (~$0.54) |
Économies horaires
Exécuter la même charge de travail pendant une heure serait encore :
≈ 5,8 fois moins cher sur Trooper.AI
Quand l'auto-hébergement devient beaucoup plus économique
L'auto-hébergement de LLM est généralement plus avantageux lorsque :
- nombreuses petites requêtes
- inférence parallèle est nécessaire
- des millions de jetons par heure
- en continu
Des exemples typiques incluent :
- Simulations de jeux IA
- systèmes d'agents
- pipelines d'automatisation
- applications de chat avec de nombreux utilisateurs
Résumé
Dans ce test de performance :
| Mesure | Résultat |
|---|---|
| Modèle | Ministral-3-14B |
| Coût du serveur | €0.51/hour |
| Jetons traités | 307k |
| Temps d'exécution | 153 secondes |
| Réduction des coûts | 82.8% |
| Avantage de coût | 5,8 fois moins cher que le GPT-5 mini |
Pour les charges de travail à haut débit, l'exécution de modèles comme Ministral-3 sur des serveurs GPU Trooper.AI permet de réduire considérablement les coûts d'inférence tout en supprimant les limites de taux des APIs.
Pourquoi vous avez besoin du modèle vLLM
Le modèle vLLM Trooper.AI vous offre :
- API compatible OpenAI
- Optimisation automatique du GPU
- Valeurs par défaut garantissant la stabilité en production
- Configuration minimale
- Débit maximal
Vous choisissez uniquement le modèle et la clé API.
Tout le reste est optimisé automatiquement.
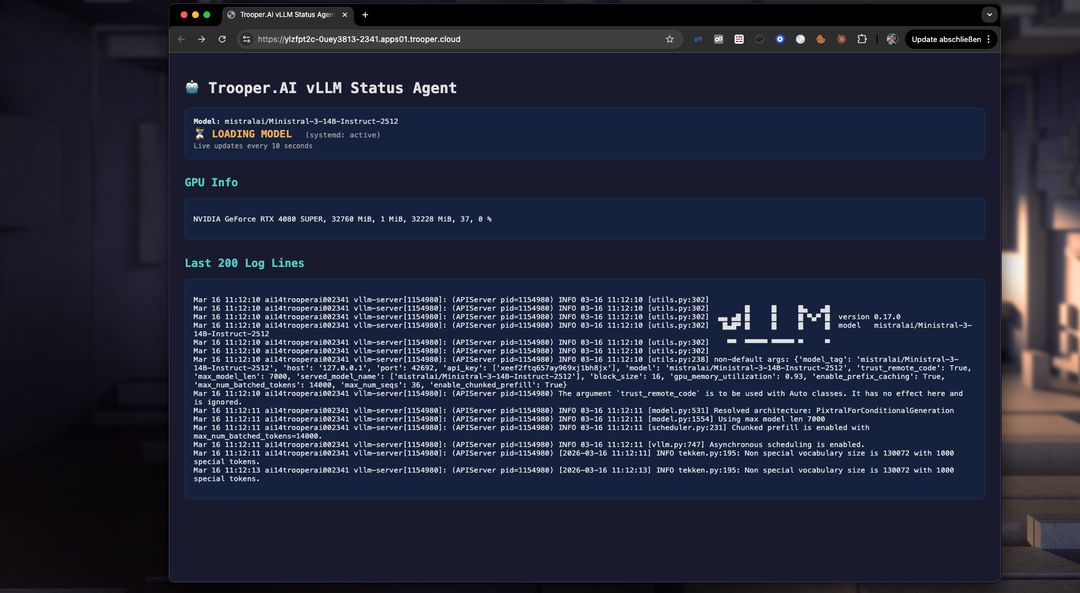
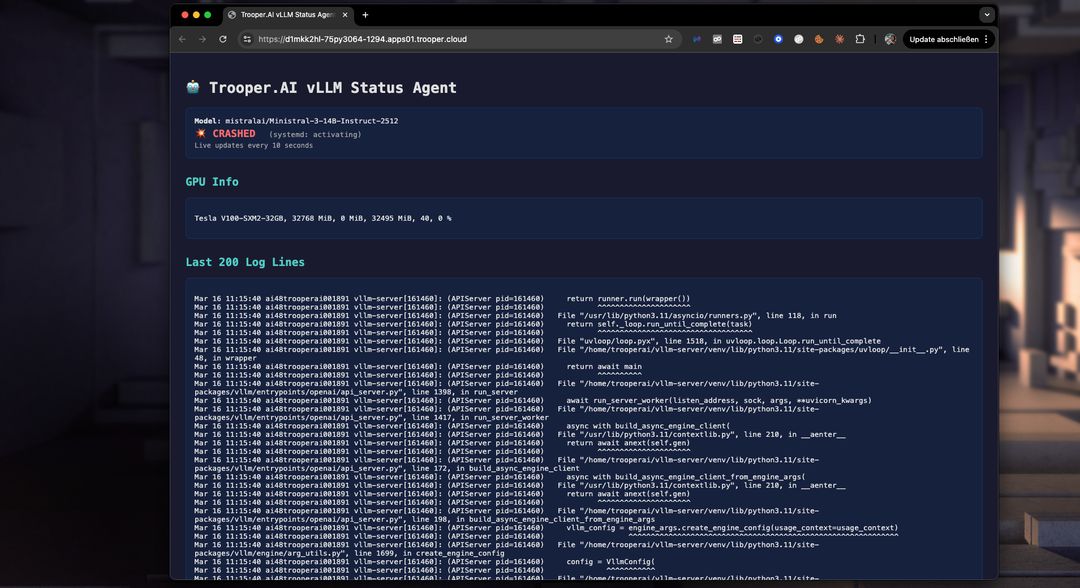
Dépannage
Avec le tableau de bord, vous pouvez facilement détecter les problèmes de démarrage et les résoudre. Pas assez de VRAM ? Passez à un Blib supérieur en quelques minutes via le tableau de bord. Ou corrigez l'utilisation de la VRAM en réduisant la taille de la fenêtre de jetons. Vérifiez facilement les Logs en temps réel avec le tableau de bord :
Ministral 3
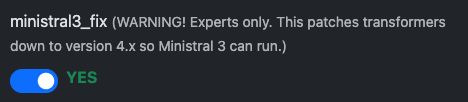
Pour utiliser Ministral 3, il faut généralement Transformers 4.x et cela peut être facilement imposé avec la case à cocher « Ministral 3 Fix » dans la configuration du modèle. Notez que vLLM est un outil expert : vous devez savoir l’optimiser et résoudre les problèmes, mais nous vous aidons au mieux.
Activez d'abord la correction pour Ministral 3 :
Deuxièmement, utilisez ces paramètres pour exploiter au maximum les fonctionnalités du modèle :
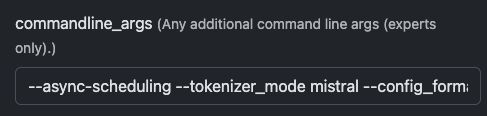
--async-scheduling --tokenizer_mode mistral --config_format mistral --load_format mistral --enable-auto-tool-choice --tool-call-parser mistral --limit-mm-per-prompt='{"image":{"count":4,"width":768,"height":768}}'
Cela démarrera alors Ministral 3 sur votre serveur – à condition que les autres paramètres soient adaptés à la taille de votre VRAM.
Nemotron 3 Nano avec budget de jetons
Pour utiliser NVIDIA Nemotron 3 Nano, vous avez besoin d'au moins la version vLLM 0.18.1 (version nightly au 30/03/2025). Vous pouvez configurer le parseur et la limite de jetons pour utiliser le paramètre «budget_thinking_tokens». En savoir plus ici : https://docs.vllm.ai/fr/latest/features/reasoning_outputs/#online-serving .
Attention : cela réduira le débit (throughput) d'environ -30 % !
Modifiez `command_line_args` comme suit :
--async-scheduling
--reasoning-parser-plugin /home/trooperai/vllm-server/nano_v3_reasoning_parser.py
--reasoning-parser nano_v3
--reasoning-config '{"think_start_str": "<think>", "think_end_str": " - I have to give the solution based on the thinking directly now:</think>"}'
Télécharger le parseur depuis :
wget -O - https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16/resolve/main/nano_v3_reasoning_parser.py
Sinon, vous pouvez activer le paramètre nemotron_3_parser en le définissant sur ON. Cela s'occupera de tout pour vous. N'oubliez pas également d'activer la version développeur nocturne !
Ainsi, vous obtenez un meilleur contrôle sur la fonctionnalité de raisonnement de Nemotron 3 Nano.
Support
Pour un réglage avancé, multi-GPU ou des préréglages personnalisés, contactez le support de Trooper.AI.