Optimierung von Ministral-3 auf vLLM
Ein praktischer Leitfaden für Klartext- und JSON-Antworten
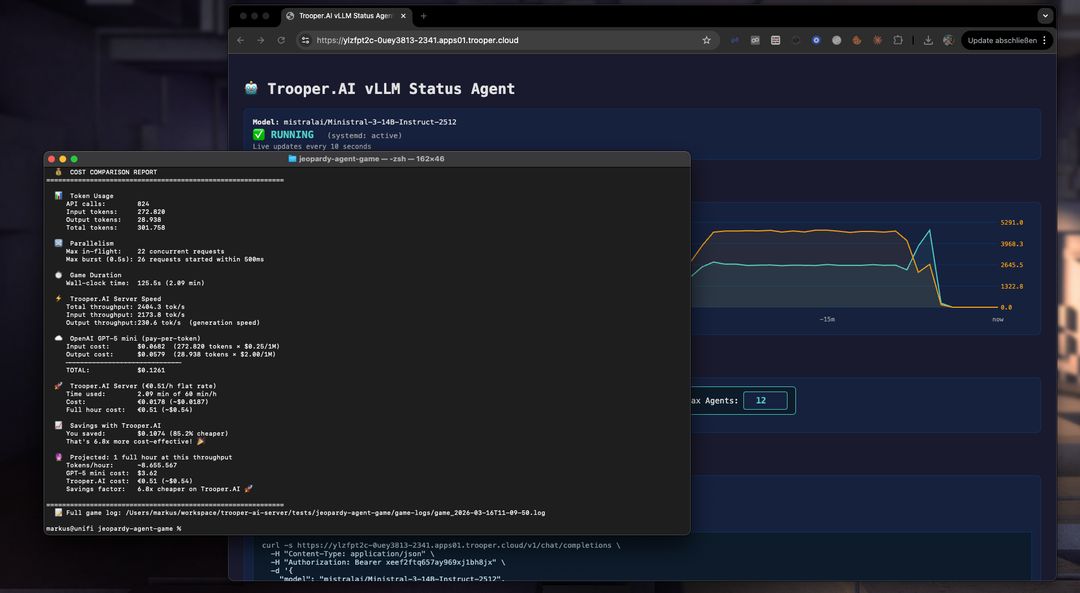
Erfahrungen aus dem Aufbau einer KI-Jeopardy-Simulation mit 12 Spielern, betrieben durch Ministral-3-14B-Instruct-2512.
Ein praktischer Leitfaden für Klartext- und JSON-Antworten
Erfahrungen aus dem Aufbau einer KI-Jeopardy-Simulation mit 12 Spielern, betrieben durch Ministral-3-14B-Instruct-2512.
Ministral-3 auf vLLM zu betreiben ist überraschend leistungsstark. Das Modell ist schnell, kreativ und liefert selbst unter hoher Auslastung hochwertige Antworten.
Doch sobald man von einfachen Chat-Aufforderungen zu strukturierten Ausgaben, Automatisierung oder programmtechnischer Nutzung übergeht, wird es schnell kompliziert.
Entwicklung eines KI-gesteuerten Jeopardy-Spiels mit 12 gleichzeitigen Spielern und Hunderten von Modellabfragen
Diese Anleitung fasst die praktischen Erkenntnisse zusammen, die beim Lösen dieser Probleme gewonnen wurden, sowie konkrete Muster, die Sie in eigenen Projekten wiederverwenden können.
Unser Benchmark-Projekt simuliert ein vollständiges Jeopardy-Spiel, bei dem:
Ein einzelner Spielablauf kann leicht über 800 API-Aufrufe hinausgehen.
Diese Umgebung deckte Edge-Cases auf, die in einfachen Demos selten vorkommen – was sie zu einem hervorragenden Testfeld macht, um zu verstehen, wie sich Ministral unter echten Produktionslasten verhält.
Ministral-Modelle verwenden keine Standard-HuggingFace-Tokenizer-Konfiguration.
Das Tokenizer-Format von Mistral muss explizit aktiviert werden.
vllm serve mistralai/Ministral-3-14B-Instruct-2512 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral
Falls Ihre Anwendung auf Function Calling angewiesen ist, fügen Sie folgende Tool-Flags hinzu:
--enable-auto-tool-choice
--tool-call-parser mistral
Im Gegensatz zu anderen Modellen unterstützt chat_template_kwargs
Wenn Sie eine Anfrage wie diese senden:
{
"chat_template_kwargs": {
"enable_thinking": false
}
}
vLLM gibt zurück:
HTTP 400: chat_template is not supported for Mistral tokenizers
Das bedeutet, dass Funktionen wie das explizite Aktivieren/Deaktivieren eines Denkmodus (wie bei Modellen wie Qwen oder DeepSeek verwendet wird) einfach nicht unterstützt werden
Glücklicherweise ist dies selten erforderlich, da Ministral bereits standardmäßig prägnante Ausgaben erzeugt.
Die offizielle vLLM-Dokumentation verwendet durchgehend folgenden Wert mit Ministral-3:
temperature = 0.15
Auf den ersten Blick wirkt dieser Wert extrem niedrig. Allerdings erweist er sich als entscheidend für strukturierte Aufgaben.
Unter Verwendung der OpenAI-Standardeinstellung:
temperature: 0.7
zu kreativ mit der Struktur
Eine einfache Anfrage wie:
{ "expertise": "2-3 topics they know best" }
kann beispielsweise Folgendes zurückgeben:
{
"expertise": [
{
"category": "Gourmet Pizza Alchemy",
"detail": "Can transform random ingredients into Michelin-star pizza"
},
{
"category": "Sumo Wrestling Physics",
"detail": "Understands body mechanics and center-of-gravity combat"
}
]
}
entspricht nicht dem vom Schema geforderten Format
Das Ergebnis:
max_tokens Grenzen werden überschritten0.15 funktioniert besserstrukturell diszipliniert
temperature: 0.15
Vorteile:
Auch die kreative Textgenerierung bleibt stark – das Modell hört einfach auf, mit der Struktur zu improvisieren.
Empfehlung:
Nutzen Sie temperature: 0.15 als Standardwert für Ministral-3.
Maschinelles JSON, das lesbar ist (und korrekt verarbeitet werden kann), aus Sprachmodellen zu generieren, ist schwieriger als es klingt.
Ministral deutet Schemabefelde semantisch statt strukturell, was zu stark verschachtelten Ausgaben führt.
Ein Prompt wie:
Return JSON with these fields.
führt oft zu ausführlichen Strukturen.
Beispielanfrage:
{ "expertise": "2-3 topics they know best" }
Typische Antwort:
{
"expertise": [
{
"category": "Ancient Roman Engineering",
"detail": "Knows aqueduct systems in surprising detail"
},
{
"category": "Pizza Dough Chemistry",
"detail": "Obsessed with yeast fermentation dynamics"
}
]
}
Das verbraucht das Dreifache der erwarteten Tokens.
Die zuverlässigste Lösung kombiniert zwei Anweisungen.
Respond with ONLY valid JSON.
No markdown, no explanation, no text before or after the JSON.
Keep values as short plain strings — never use nested objects or arrays.
Direkt neben der Schema-Definition:
Every value MUST be a short plain string — NO arrays, NO nested objects.
Temperatur 0.15 führt dazu, dass vorhersehbar flaches JSON erzeugt wird.
Längere Werte als andere Modelle
Beispielbeobachtung aus unserem Benchmark:
| Modell | Benötigte Token |
|---|---|
| GPT-4o | ~512 |
| Qwen | ~512 |
| Ministral-3 | ~1024 |
Eine sichere Regel:
Planen Sie für JSON-Ausgaben mit einem Faktor von 1,5–2× der Tokens ein.
Selbst bei perfekten Prompts generieren Modelle gelegentlich fehlerhaften JSON.
Defensive Parsing-Schichten hinzufügen
function extractJSON(raw, shape) {
var text = raw.replace(/^```(?:json)?\s*/i, '').replace(/\s*```$/i, '').trim();
if (shape === 'array') {
var m = text.match(/\[[\s\S]*\]/);
if (m) text = m[0];
} else {
var m = text.match(/\{[\s\S]*\}/);
if (m) text = m[0];
}
return text;
}
Öffnende Klammern verfolgen und automatisch schließen:
var stack = [];
var inStr = false, esc = false;
for (var i = 0; i < text.length; i++) {
var ch = text[i];
if (esc) { esc = false; continue; }
if (ch === '\\') { esc = true; continue; }
if (ch === '"') { inStr = !inStr; continue; }
if (inStr) continue;
if (ch === '{') stack.push('}');
else if (ch === '[') stack.push(']');
else if (ch === '}' || ch === ']') stack.pop();
}
text = text.replace(/,\s*$/, '');
while (stack.length > 0)
text += stack.pop();
Wenn das Modell weiterhin verschachtelte Strukturen zurückgibt:
if (Array.isArray(value)) {
flat = value.map(function(item) {
if (typeof item === 'string') return item;
if (typeof item === 'object') return Object.values(item).join(' — ');
return String(item);
}).join(', ');
}
Eine einfache Wiederholungsschleife erhöht die Zuverlässigkeit drastisch.
Da Ministral bei niedriger Temperatur konsistent reagiert, führen Wiederholungsversuche meist zum Erfolg.
Empfohlen:
2–3 retry attempts
Ministral liebt die Formatierung.
Selbst wenn Sie nach reinem Text fragen, neigt es dazu, Folgendes zu erzeugen:
Dies geschieht, weil das Modell mit einem eingebauten Systemhinweis ausgeliefert wird, der reichhaltige Markdown-Formatierung fördert.
Viele Pipelines verlassen sich auf einfache String-Prüfungen.
Beispiel:
verdict.toUpperCase().startsWith('CORRECT')
Wenn das Modell jedoch Folgendes zurückgibt:
**CORRECT**
Der Test schlägt fehl.
Der sicherste Ansatz besteht darin, alle Ausgaben vor der Verarbeitung zu normalisieren.
function stripMarkdown(text) {
if (!text) return text;
var s = text.replace(/\*\*([^*]+)\*\*/g, '$1');
s = s.replace(/__([^_]+)__/g, '$1');
s = s.replace(/\*([^*]+)\*/g, '$1');
s = s.replace(/^#{1,6}\s+/gm, '');
s = s.replace(/`([^`]+)`/g, '$1');
s = s.replace(/^```[a-z]*\s*$/gm, '');
return s.trim();
}
Wenden Sie dies auf jede Modellantwort an, nicht nur bei Ministral.
Es vermeidet modellspezifische Verzweigungen und hält Pipelines konsistent.
Falls Ihr System mehrere Modellfamilien unterstützt (Mistral, Qwen, DeepSeek, Llama usw.), ist das am besten wartbare Design, das Verhalten der Modelle an einer zentralen Stelle zu bündeln.
Beispiel:
function buildModelProfile(modelName) {
var lower = modelName.toLowerCase();
var isMistral = lower.includes('mistral') || lower.includes('ministral');
return {
family: isMistral ? 'Mistral' : 'Generic',
jsonSystemInstruction: isMistral
? 'Respond with ONLY valid JSON. No markdown. Keep values as short plain strings.'
: 'You output only valid JSON. No markdown fences, no explanation.',
jsonSchemaHint: isMistral
? ' Every value MUST be a short plain string — NO arrays, NO nested objects.'
: '',
jsonTemperature: isMistral ? 0.15 : 0.7,
defaultTemperature: isMistral ? 0.15 : 0.7,
plainTextInstruction: ' Do not use markdown formatting.'
};
}
Dies ermöglicht es dem Rest Ihres Systems, modellunabhängig zu bleiben.
Das Hinzufügen eines neuen Modells wird später trivial.
| Einstellung | Empfohlener Wert | Grund |
|---|---|---|
| tokenizer_mode | Mistral | Erforderlich für den korrekten Tokenizer |
| config_format | Mistral | Erforderlich |
| load_format | Mistral | Erforderlich |
| chat_template_kwargs | Nicht senden | Nicht unterstützt |
| Temperatur | 0.15 | Verhindert strukturelle Halluzinationen |
| JSON-Anweisung | Explizite flache Werte | Vermeiden Sie verschachtelte Objekte |
| max_tokens | 1,5–2× typisch | Das Modell ist ausführlich. |
| Markdown-Entfernung | Immer | Formatierungsfehler vermeiden |
| JSON-Wiederholungen | 2–3 Versuche | Zuverlässige Wiederherstellung |
Ministral-3 funktioniert außergewöhnlich gut, wenn es richtig abgestimmt ist.
Sobald Sie:
außergewöhnlich vorhersagbar und produktionsreif
In unserem Jeopardy-Benchmark unterstützte diese Konfiguration:
Alle Ausführungen laufen lokal auf der Trooper.AI-GPU-Infrastruktur.
Vollständiges vLLM-Deploymentsvorlage hier testen:
Mieten Sie noch heute Ihren eigenen GPU-Server und beginnen Sie mit dem Erstellen erstaunlicher KI-Anwendungen! Die Trooper.AI GPU-Server basieren auf rein wiederaufbereiteten High-End-Technologien der letzten Jahre und wurden entwickelt, um Ihnen die beste Leistung, Sicherheit und Zuverlässigkeit für alle Ihre KI-Bedürfnisse zu bieten.
EU-Standort · Hohe Privatsphäre · Hervorragende Leistung · Bester Support