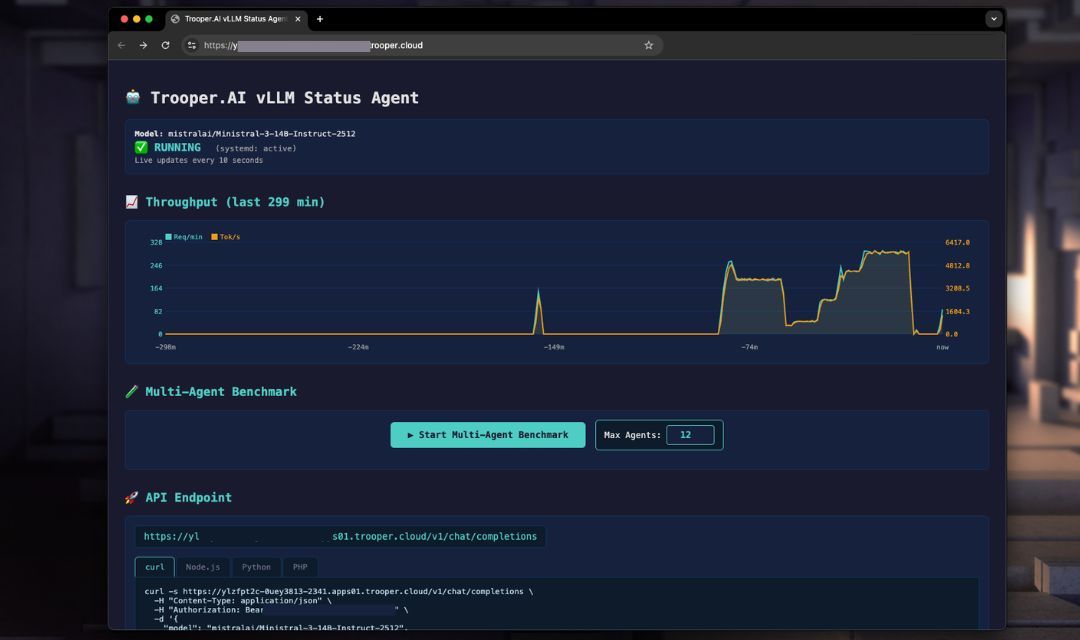
vLLM OpenAI-kompatibler Server
Trooper.AI provides a fully automated vLLM deployment template that installs, configures, and runs an OpenAI-compatible inference server on your GPU server using systemd.
Das Ziel:
- Maximaler Durchsatz
- Automatische GPU-Architekturabstimmung
- OpenAI-kompatible API
- Produktionssichere Standardeinstellungen
- Keine manuelle GPU-Optimierung erforderlich
Die Vorlage übernimmt automatisch:
- Erkennt GPU-Architektur und VRAM
- Wählt die optimale Präzision (FP16 / BF16 / FP8)
- Optimiert Batching und Parallelität
- Installiert vLLM in einer virtueller Umgebung
- Erstellt einen persistenten systemd-Dienst
- Stellt OpenAI-kompatible Endpunkte
- Leistung zur Parametereinstellung testen
Sie steuern nur einen kleinen Satz öffentlicher Parameter.
Verständnis der GPU-Anzahl: vLLM funktioniert mit mehreren GPUs, erfordert jedoch, dass die Anzahl der GPUs gleichmäßig durch die Aufmerksamkeitsköpfe des Modells teilbar ist. Beispielsweise kann ein Modell wie Gemma mit 32 Aufmerksamkeitsköpfen 1, 2, 4 oder 8 GPUs nutzen – aber nicht 3.
Wichtiger Sicherheitshinweis zu den Screenshots: Die in den Screenshots gezeigten Server dienen ausschließlich Demonstrationszwecken und sind durch die Trooper.AI Network-Level Firewall gesichert, welche mit allen GPU-Server-Bestellungen inklusive ist. Für detaillierte Informationen siehe 🛡️ Trooper.AI individuell anpassbare Network-Level Firewall.
Einstellungen der vLLM-Vorlage
Dieses Template deployt einen vorgefertigten vLLM-Inferenzserver, der direkt auf Ihrer Trooper.AI-Instanz bereitgestellt wird. Es installiert die benötigte Laufzeitumgebung, konfiguriert das API-Endpoint und bereitet das Modell für Anfragen im OpenAI-Kompatiblen Format vor.
Im Folgenden eine kurze Erläuterung der einzelnen Konfigurationsoptionen.
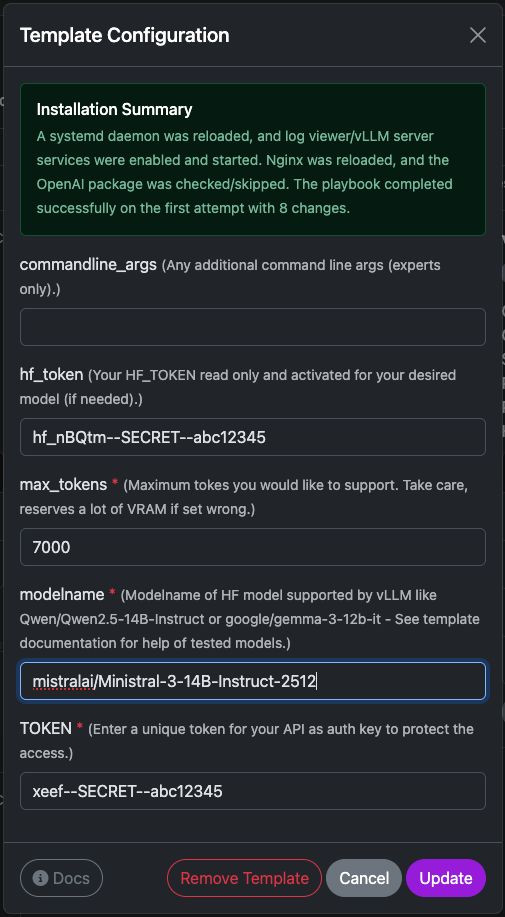
commandline_args
Optionale erweiterte Argumente, die direkt an den vLLM-Serverstartbefehl übergeben werden.
Verwenden Sie dies, wenn Sie zusätzliche Funktionen wie z. B. aktivieren müssen:
- Tensor-Parallelität
- Quantisierung
- Toolaufruf
- benutzerdefinierte Tokenizer-Einstellungen
- spekulative Dekodierung
Beispiel:
--tensor-parallel-size 2
Leer lassen, es sei denn, Sie wissen genau, welche Flags Sie verwenden möchten.
hf_token
Ihr Hugging Face-Zugriffstoken
Dies ist erforderlich, wenn das Modell:
- ist gesperrt (oder erfordert Authentifizierung)
- Authentifizierung
- oder aus einem privaten Repository
Für öffentliche Modelle kann dieses Feld leer gelassen werden.
Sie können hier ein Token generieren:
https://huggingface.co/settings/tokens
Der Token wird nur während des Modell-Downloads verwendet.
max_tokens
Legt das maximale Kontextfenster fest, das der Server unterstützen soll.
Dies beeinflusst direkt den VRAM-Verbrauch.
Typische Werte:
| Kontext | Empfohlen |
|---|---|
| kleine Modelle | 4096 |
| mittlere Modelle | 8192 |
| Modelle mit langem Kontext | 16384+ |
Höhere Werte erhöhen den Speicherverbrauch erheblich. Wenn Ihr Server keinen VRAM mehr hat, verringern Sie diesen Wert.
Modellname
Der HuggingFace-Modellidentifikator, der von vLLM geladen werden soll.
Beispiel:
mistralai/Ministral-3-14B-Instruct-2512
Weitere kompatible Beispiele:
Qwen/Qwen2.5-14B-Instruct
google/gemma-3-12b-it
meta-llama/Meta-Llama-3-8B-Instruct
... and many more
Stellen Sie sicher, dass das Modell von vLLM unterstützt wird und in Ihren GPU-Speicher passt.
TOKEN
Dies ist Ihr API-Authentifizierungsschlüssel.
Alle Anfragen an den vLLM-Server müssen dieses Token im Header enthalten:
Authorization: Bearer YOUR_TOKEN
Dies schützt Ihren Server vor unbefugtem Zugriff.
Beispielanfrage:
curl https://your-server/v1/chat/completions \
-H "Authorization: Bearer YOUR_TOKEN"
Verwenden Sie eine starke, zufällige Zeichenfolge.
Modellgröße & GPU-Anforderungen
Sie können eine große Auswahl an Large Language Models von HuggingFace innerhalb von vLLM verwenden. Stellen Sie sicher, dass ausreichend VRAM verfügbar ist, da die Leistung davon abhängt, dass genügend freier GPU-VRAM vorhanden ist, um die Modell- und Kontextgröße multipliziert mit der Anzahl der gleichzeitigen Benutzer aufzunehmen.
Trooper.AI wählt automatisch die optimale Präzision pro GPU-Architektur aus.
VRAM-Berechnung: Modelltiefen (Model weights) + ca. 25 % KV-Cache-Puffer.
Der VRAM lässt sich mithilfe von Tensor Parallelism auf mehrere GPUs verteilen (--tensor-parallel-size N).
| Modell | Parameter | Präzision | Min. VRAM Gesamt | GPU-Konfiguration | GPUs |
|---|---|---|---|---|---|
| Qwen/Qwen3-4B | 4B | BF16 | ~8 GB | 1× V100 16GB / RTX 4070 Ti Super | 1 |
| Qwen/Qwen3-8B | 8B | BF16 | ~20 GB | 1× RTX 3090 / RTX 4090 (24 GB) | 1 |
| mistralai/Ministral-3-14B-Instruct-2512 | 14B | FP8 | ~29 GB | 1× RTX 4080 Pro 32GB oder 1× A100 40GB | 1 |
| Qwen/Qwen3-32B | 32B | FP8 | ~40 GB | 1× A100 40GB oder 2× RTX 4090 (2×24 GB) | 1–2 |
| meta-llama/Llama-3.1-8B-Instruct | 8B | FP8 | ~20 GB | 1× RTX 3090 / RTX 4090 (24 GB) | 1 |
| meta-llama/Llama-3.1-70B-Instruct | 70B | FP8 | ~90 GB | 1× RTX Pro 6000 Blackwell (96 GB) oder 2× A100 (2×40 GB) | 1–2 |
Hinweis: FP8 kommt bei Ada-/Hopper-Architekturen (z. B. RTX 40-Reihe, A100, H100) zum Einsatz, um die Leistung zu maximieren.
Trooper.AI wählt automatisch die optimale Präzision für Ihre GPU aus.
Bei Multi-GPU-Anordnungen kommt Tensor Parallelism zum Einsatz – der VRAM skaliert linear über alle GPUs hinweg.
Öffentliche Parameter
Diese Parameter können über Umgebungsvariablen festgelegt werden, bevor der Installer ausgeführt wird.
| Variable | Beschreibung |
|---|---|
TOKEN |
API-Schlüssel zur Authentifizierung |
modelname |
HuggingFace-Modellpfad |
hf_token |
HuggingFace Token (für geschützte Modelle) |
commandline_args |
Optionale zusätzliche vLLM CLI-Argumente |
Automatisches Benchmarking zur Parameteroptimierung
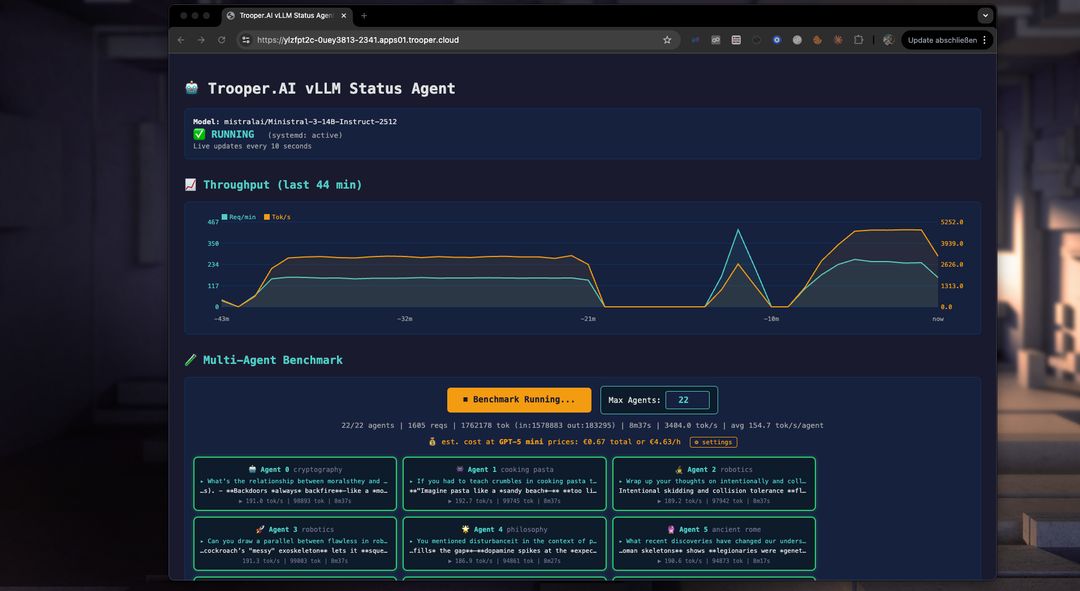
Unsere Vorlage beinhaltet einen Performance-Benchmark, der Ihnen hilft, Ihren GPU-Server für die Multi-Agent-Nutzung zu optimieren. Verwenden Sie ihn, um Modelle, GPU-Typen und Parameter zu testen und zu vergleichen, um den Durchsatz und die Anzahl gleichzeitiger Benutzer zu maximieren.
Wie funktioniert der Benchmark?
Der Benchmark startet mehrere Agenten gleichzeitig, die jeweils mit dem vLLM-Server-Endpunkt zu einem anderen Thema interagieren. Dies verhindert Caching und testet die Leistung in realen Szenarien. Sie können den Durchsatz jedes Agenten, den Gesamt-Durchsatz und die Kosten für tokenbasierte Dienste wie GPT-5 mini vergleichen. Oft ist ein vLLM-Server von Trooper.AI 2-4x günstiger als große tokenbasierte Inferenzdienste, während Ihre LLM-Arbeit privat bleibt!
Was die Vorlage bewirkt
-
Erkennt GPU-Architektur (Volta, Ampere, Ada, Hopper, Blackwell)
-
Erkennt die VRAM-Größe
-
Wählt automatisch die optimale Präzision aus:
- FP8 > BF16 > FP16
-
Verwendet FP16 KV-Cache für Stabilität
-
Abstimmungen:
- maximale parallele Sequenzen
- Batch-Token-Größe
- Speicherauslastung
-
Installiert vLLM mit CUDA
Erstellt einen systemd-Dienst:
Quellcodevllm-server.service-
Startet einen persistenten, OpenAI-kompatiblen API-Server auf einem sicheren HTTPS-Endpunkt.
Es ist keine manuelle Konfiguration erforderlich.
API-Endpunkte
Basis-URL:
http://YOUR_SERVER:PORT/v1
Endpunkte:
/v1/models/v1/completions/v1/chat/completions
Authentifizierungsheader:
Authorization: Bearer YOUR_TOKEN_FROM_CONFIG
Python Client Beispiel
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1"
)
resp = client.chat.completions.create(
model="Qwen/Qwen3-14B",
messages=[
{"role": "user", "content": "Hello, what is vLLM?"}
],
max_tokens=200
)
print(resp.choices[0].message.content)
Node.js Client Beispiel
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "YOUR_API_KEY",
baseURL: "https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1"
});
const completion = await client.chat.completions.create({
model: "Qwen/Qwen3-14B",
messages: [
{ role: "user", content: "Hello from Node.js" }
],
max_tokens: 200
});
console.log(completion.choices[0].message.content);
PHP Client Beispiel
<?php
$ch = curl_init("https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1/chat/completions");
$data = [
"model" => "Qwen/Qwen3-14B",
"messages" => [
["role" => "user", "content" => "Hello from PHP"]
],
"max_tokens" => 200
];
curl_setopt_array($ch, [
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_HTTPHEADER => [
"Authorization: Bearer YOUR_API_KEY",
"Content-Type: application/json"
],
CURLOPT_POSTFIELDS => json_encode($data)
]);
$response = curl_exec($ch);
curl_close($ch);
echo $response;
Streaming Beispiel
Python-Streaming
resp = client.chat.completions.create(
model="Qwen/Qwen3-14B",
messages=[{"role":"user","content":"Explain transformers"}],
stream=True
)
for chunk in resp:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Node.js Streaming
const stream = await client.chat.completions.create({
model: "Qwen/Qwen3-14B",
messages: [{ role: "user", content: "Explain transformers" }],
stream: true
});
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0].delta?.content || "");
}
Anwendungsfälle
Trooper.AI vLLM Server sind konzipiert für:
- SaaS KI-Backends
- Chatbots
- Code-Assistenten
- RAG-Systeme
- Multi-User-Inferenzserver
- Hochdurchsatz-Batch-Inferenz
- GPU-Mietumgebungen
Leistungsphilosophie
Trooper.AI verwendet:
- Automatische Architekturabstimmung
- Automatische Präzisionsauswahl
- VRAM-bewusstes Batching
- Stabile KV-Cache-Konfiguration
Dies vermeidet:
- GPU-Fehlkonfiguration
- Präzisionsabstürze
- VRAM-Fragmentierung
- Kontextinstabilität
Kostenvergleich: Ministral-3 auf Trooper.AI vs. GPT-5 mini
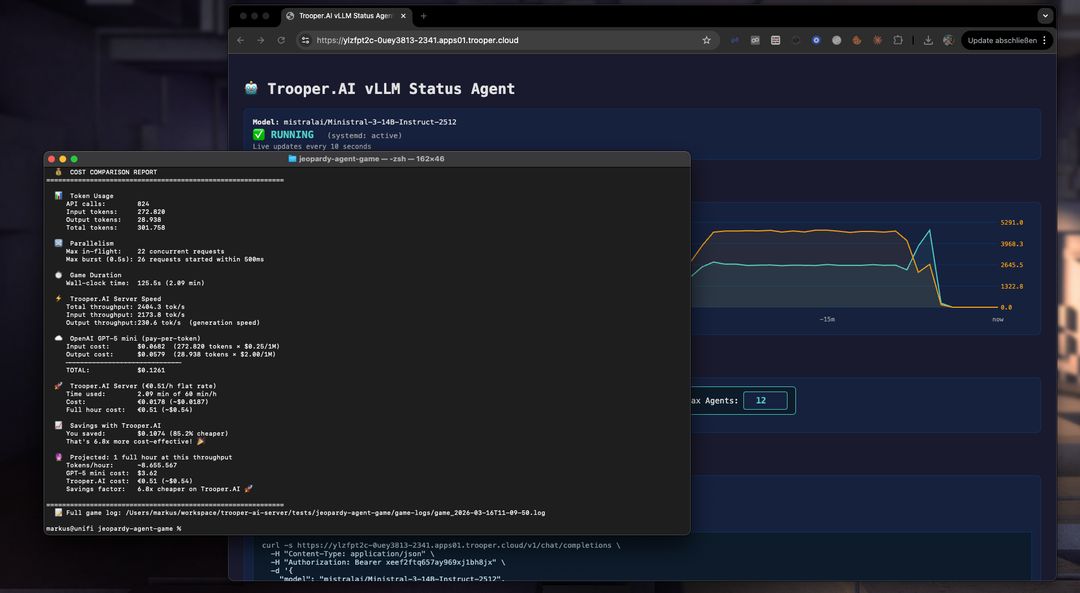
Um eine grobe Vorstellung von der Wirtschaftlichkeit des Self-Hostings zu geben, vergleicht die folgende Gegenüberstellung die Kosten für den Betrieb von Ministral-3-14B-Instruct-2512 auf einem Trooper.AI GPU-Server mit der Verwendung der GPT-5 mini API für dieselbe Arbeitslast.
Die Schätzung basiert auf der in diesem Artikel beschriebenen realen Benchmark-Ausführung und wurde auf eine Stunde kontinuierlichen Inferenzdurchsatz hochgerechnet.
Stündliche Kosten bei gemessener Leistung
| Plattform | Stündliche Kosten |
|---|---|
| GPT-5 mini API | ~$3.12 |
| Ministral-3-14B auf einem Trooper.AI-GPU-Server | €0.51 (~$0.54) |
Wie dies berechnet wurde
Diese Schätzung basiert auf dem tatsächlichen Benchmark-Lauf in diesem Artikel mit Ministral-3-14B-Instruct-2512, durchgeführt auf einem Trooper.AI-GPU-Server.
| Metrik | Wert |
|---|---|
| Verarbeitete Gesamtzahl der Token | 307,028 |
| Laufzeit | 153 Sekunden |
| Durchsatz | ~2006 Token/Sekunde |
| Prognostizierte Token/Stunde | ~7,22 Millionen Tokens |
Token-Mix in der Benchmark:
| Token-Typ | Token |
|---|---|
| Eingabe-Token | 275,186 |
| Ausgabe-Token | 31,842 |
Skalierung dieses Verhältnisses auf ~7,22 Mio. Tokens/Stunde und Anwendung der GPT-5-mini-Preisgestaltung:
- $0,25 / 1M Eingabe-Token
- 2,00 $ / 1M Ausgabetoken
ergibt einen geschätzten Kostenaufwand von ca. €3,12 pro Stunde für dieselbe Arbeitslast.
Der Ministral-3-Server auf Trooper.AI läuft stattdessen zu einem fixen Preis von €0.51/Stunde (ca. $0.54), unabhängig vom Token-Volumen – was das Verarbeiten von Millionen Tokens pro Stunde zu vorhersehbaren Kosten ermöglicht.
Langfristige Workload-Projektion
Für eine volle Stunde
| Metrik | Wert |
|---|---|
| Token pro Stunde | ~7,221,543 |
| Kosten für GPT-5 mini | $3.12 |
| Trooper.AI Serverkosten | €0.51 (~$0.54) |
Stündliche Einsparungen
Die gleiche Arbeitslast für eine Stunde würde immer noch ergeben:
≈ 5,8-mal günstiger auf Trooper.AI
Wenn Self-Hosting deutlich günstiger wird
Self-Hosting von LLMs gewinnt tendenziell wirtschaftlich, wenn:
- Arbeitslasten mit vielen kleinen Anfragen
- parallele Inferenz ist erforderlich
- Millionen von Tokens pro Stunde
- kontinuierlich
Typische Beispiele sind:
- KI-Spielsimulationen
- Agentensysteme
- Automatisierungspipelines
- Chat-Anwendungen mit vielen Benutzern
Zusammenfassung
In diesem Benchmark:
| Metrik | Ergebnis |
|---|---|
| Modell | Ministral-3-14B |
| Serverkosten | €0.51/hour |
| Verarbeitete Token | 307k |
| Laufzeit | 153 Sekunden |
| Kostenreduzierung | 82.8% |
| Kostenersparnis | 5,8-mal günstiger als GPT-5 mini |
Ministral-3 auf Trooper.AI-GPU-Servern auszuführen kann die Inferenzkosten bei Hochlast-Anwendungen deutlich senken – gleichzeitig entfallen API-Ratenbegrenzungen.
Warum Sie die vLLM-Vorlage benötigen
Die Trooper.AI vLLM-Vorlage bietet Ihnen:
- OpenAI-kompatible API
- Automatische GPU-Optimierung
- Produktionssichere Standardeinstellungen
- Minimale Konfiguration
- Maximaler Durchsatz
Sie wählen nur das Modell und den API-Schlüssel.
Alles andere wird automatisch optimiert.
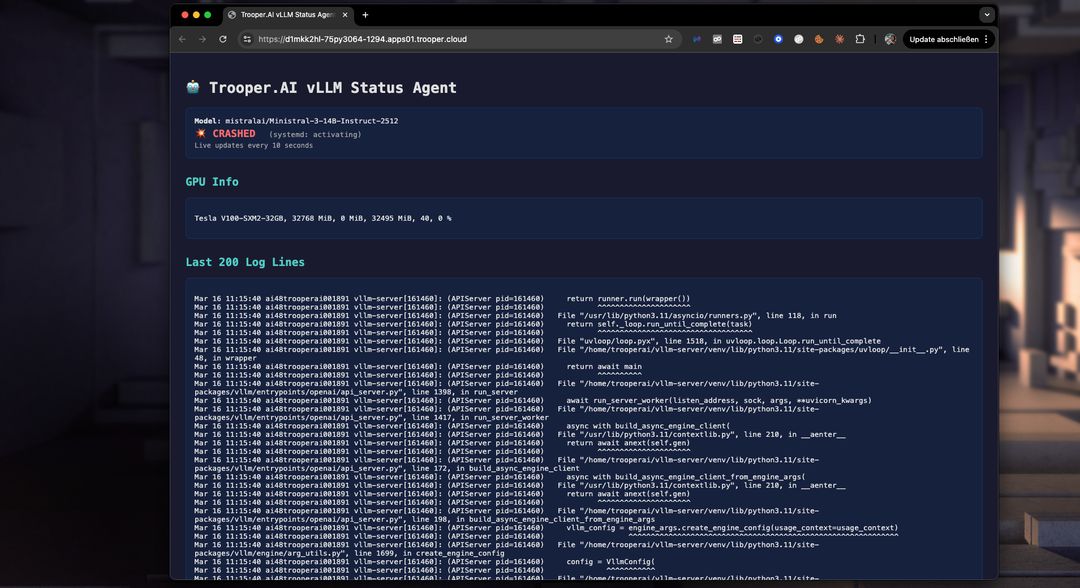
Fehlerbehebung
Mit dem Dashboard können Sie Startprobleme leicht erkennen und beheben. Nicht genügend VRAM? Wechseln Sie über das Dashboard in wenigen Minuten zu einem höheren Blib. Oder beheben Sie die VRAM-Nutzung, indem Sie die Token-Fenstergröße verringern. Überprüfen Sie die Logs einfach in Echtzeit mit dem Dashboard:
Ministral 3
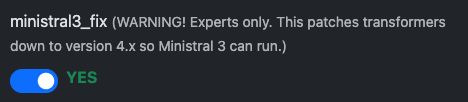
Zur Nutzung von Ministral 3 benötigen Sie in der Regel Transformers 4.x, was sich über das Häkchenfeld »Ministral 3 Fix« in der Template-Konfiguration erzwingen lässt. Beachten Sie bitte, dass vLLM ein Expertentool ist und Sie Optimierungen sowie Fehlerbehebungen selbst vornehmen müssen. Dennoch helfen wir Ihnen nach besten Kräften weiter.
Zuerst aktivieren Sie bitte die Option „Ministral 3 Fix“:
Zweitens, verwenden Sie diese Parameter, um aus dem Modell möglichst viele Funktionen herauszuholen:
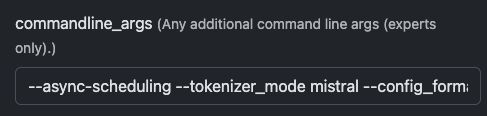
--async-scheduling --tokenizer_mode mistral --config_format mistral --load_format mistral --enable-auto-tool-choice --tool-call-parser mistral --limit-mm-per-prompt='{"image":{"count":4,"width":768,"height":768}}'
Damit wird dann Ministral 3 auf Ihrem Server gestartet – vorausgesetzt, alle anderen Parameter passen zu Ihrer VRAM-Größe.
Nemotron 3 Nano mit Token-Budget
Für NVIDIA Nemotron 3 Nano benötigen Sie mindestens Version vLLM 0.18.1 (Stand Nachtbau vom 2025-03-30). Sie können den Parser sowie das Token-Limit konfigurieren, um thinking_token_budget zu nutzen. Weitere Informationen finden Sie hier: https://docs.vllm.ai/de/stable/merkmale/logisches_ausgabeverhalten/#online-betrieb .
Bitte beachten Sie: Dies reduziert die Durchsatzleistung etwa um -30 %.
Passen Sie `command_line_args` wie folgt an:
--async-scheduling
--reasoning-parser-plugin /home/trooperai/vllm-server/nano_v3_reasoning_parser.py
--reasoning-parser nano_v3
--reasoning-config '{"think_start_str": "<think>", "think_end_str": " - I have to give the solution based on the thinking directly now:</think>"}'
Parser herunterladen von:
wget -O - https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16/resolve/main/nano_v3_reasoning_parser.py
Alternativ können Sie stattdessen den nemotron_3_parser auf ON setzen. Das übernimmt dies für Sie. Stellen Sie sicher, dass auch der nightly-Developer-Build aktiviert ist!
Damit erhalten Sie mehr Kontrolle über die Reasoning-Funktion von NVIDIA Nemotron-3-Nano.
Support
Für fortgeschrittene Anpassungen, Multi-GPU oder benutzerdefinierte Voreinstellungen kontaktieren Sie den Trooper.AI Support.