Elke Docker
Deze template stelt u in staat om zowel GPU-versnelde Docker containers, zoals ComfyUI, als containers zonder GPU-ondersteuning, zoals n8n, te implementeren. Deze flexibiliteit maakt een breed scala aan toepassingen mogelijk, van AI-beeldgeneratie tot geautomatiseerde workflows, allemaal binnen een enkele, beheersbare omgeving. Configureer en voer uw gewenste Docker containers moeiteloos uit, gebruikmakend van de kracht en het gemak van deze veelzijdige template.
Hoewel u misschien liever zelf de Docker-configuraties beheren wilt, raden wij aan om ons "Any Docker"-template te gebruiken voor de initiële instelling. Het configureren van Docker met GPU-support kan complex zijn en deze sjabloon biedt een gestroomlijnde basis voor het bouwen en deployen van uw containers.
🚨 Belangrijke overweging voor meerdere Docker-containers!
Om een correcte werking te garanderen bij het uitvoeren van meerdere Docker containers op uw GPU server, is het essentieel om elke container een unieke naam en data directory toe te wijzen. Gebruik bijvoorbeeld, in plaats van “my_docker_container”, een naam als “my_comfyui_container” en stel de data directory in op een uniek pad zoals /home/trooperai/docker_comfyui_dataDeze eenvoudige stap zorgt ervoor dat er meerdere Docker-containers zonder conflicten kunnen worden uitgevoerd.
Voorbeeld 1: vLLM OpenAI Compatibele LLM Server via HF
Dit voorbeeld legt stap voor stap uit hoe je een OpenAI-compatibele vLLM-API kunt draaien met behulp van de Trooper.AI any-docker-sjabloon.
Het is geschreven om ook begrijpelijk te zijn bij minimale kennis van Docker of AI.
Deze configuratie gebruikt Qwen/Qwen3-4B, wat ondersteund en uitvoerbaar is op alle Trooper.AI GPU-servers
Wat deze setup doet
- vLLM-server start binnen Docker
- Ladt het model Qwen/Qwen3-4B van Hugging Face
- Een met OpenAI compatibele HTTP-API
- Werkt met moderne NVIDIA-drivers (CUDA 13 / 580+)
Waarom deze configuratie nodig is
Op nieuwere NVIDIA-stuurprogramma's kunnen oudere vLLM Docker-images crashen met CUDA-fouten tijdens het opstarten.
Om dit te voorkomen, gebruikt de any-docker template:
- de nachtelijke versie van de vLLM-image
- Dwingt Docker om de NVIDIA-besturingbibliotheken van de gastheer te laden
U hoeft deze logica niet aan te passen — gebruik gewoon de configuratie hieronder.
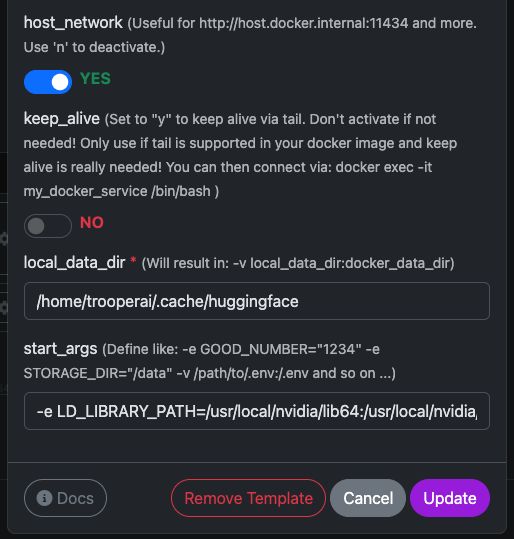
Sjabloonvariabelen
Zie hier een screenshot over hoe te configureren en hieronder de volledige tekst om te kopiëren en te plakken.
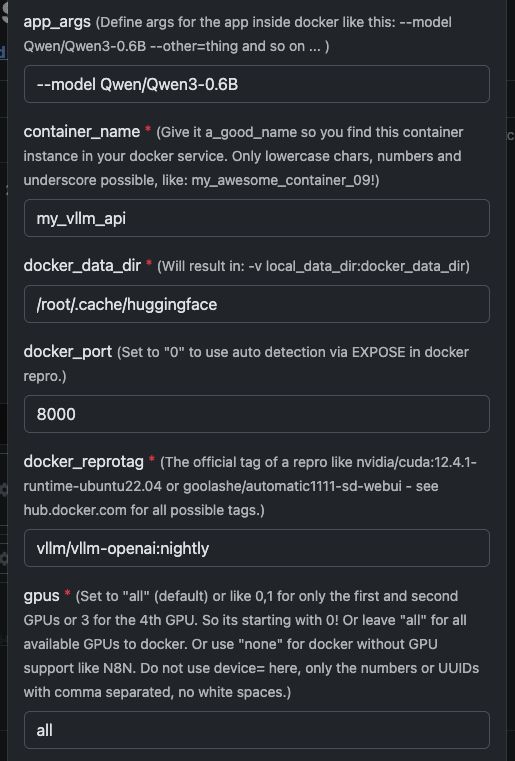
| Variabele | Waarde | Wat het betekent |
|---|---|---|
app_args |
--model Qwen/Qwen3-4B |
Definieert welk model vLLM moet laden. |
container_name |
my_vllm_api |
Naam van de Docker container. |
docker_reprotag |
vllm/vllm-openai:nightly |
vLLM-image met fixes voor moderne NVIDIA-drivers. |
docker_port |
8000 |
Interne poort gebruikt door vLLM. |
gpus |
all |
Maakt alle GPU's beschikbaar voor Docker. |
host_network |
YES |
Stelt de API direct bloot op het hostnetwerk. |
keep_alive |
NO |
Normale container levenscyclus (aanbevolen). |
local_data_dir |
/home/trooperai/.cache/huggingface |
Model cache-directory op de host. |
docker_data_dir |
/root/.cache/huggingface |
Model cache directory in de container. |
start_args |
-e LD_LIBRARY_PATH=/usr/local/nvidia/lib64:/usr/local/nvidia/lib:/usr/lib/x86_64-linux-gnu --ipc=host --env HF_TOKEN=… |
Vereiste correctie voor CUDA + gedeeld geheugen. |
Belangrijke opmerking over LD_LIBRARY_PATH
Deze instelling is verplicht op systemen met CUDA 13.
Zonder deze kan vLLM mogelijk niet starten door onverenigbaarheden met de NVIDIA-drijvers.
Verwijder dit niet.
Hoe te controleren of het werkt
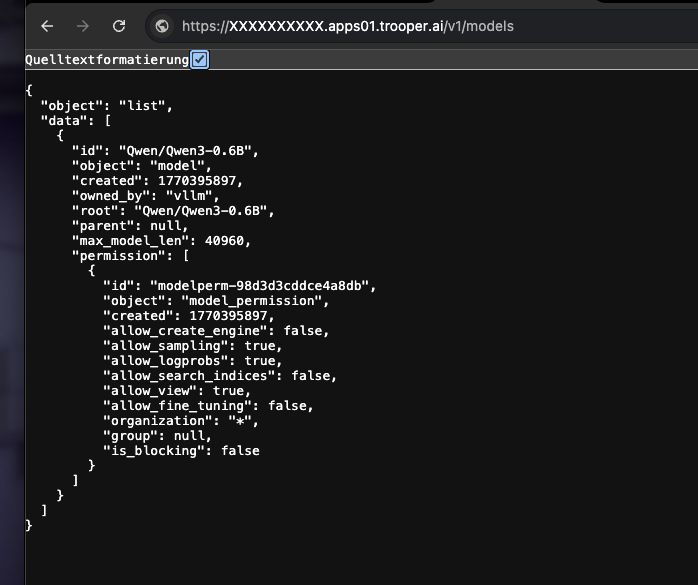
Voer het volgende commando uit:
curl https://XXXXXXXX.apps01.trooper.ai/v1/models
Als u dit ziet Qwen/Qwen3-4B in het antwoord, de server draait correct.
Voorbeeldgebruik met curl
curl https://XXXXXXXX.apps01.trooper.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer dummy-key" \
-d '{
"model": "Qwen/Qwen3-4B",
"messages": [
{ "role": "user", "content": "What is Trooper.AI?" }
]
}'
Voorbeeld gebruik met Node.js
Eenvoudige aanvraag
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const result = await client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: "What is Trooper.AI?" }],
});
console.log(result.choices[0].message.content);
Node.js Concurrent Load Test (16 parallelle verzoeken)
Dit voorbeeld verzendt 16 gelijktijdige verzoeken naar de API en print een eenvoudig doorvoersamenvatting.
import OpenAI from "openai";
import crypto from "crypto";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const CONCURRENCY = 16;
function randomPrompt() {
return `Explain this random concept in one sentence: ${crypto.randomUUID()}`;
}
const startTime = Date.now();
const requests = Array.from({ length: CONCURRENCY }, () =>
client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: randomPrompt() }],
})
);
const responses = await Promise.all(requests);
const endTime = Date.now();
const durationSeconds = (endTime - startTime) / 1000;
let totalTokens = 0;
for (const r of responses) {
totalTokens += r.usage.total_tokens;
}
const tokensPerSecond = (totalTokens / durationSeconds).toFixed(2);
console.log(
`${tokensPerSecond} token/s of total ${totalTokens} tokens in ${durationSeconds.toFixed(
2
)} seconds on ${CONCURRENCY} concurrent connections`
);
Deze test is nuttig voor:
- gelijktijdigheid verifiëren
- doorvoersnelheid schatten
- snelle prestatie-integriteitstests
Hoe krijg ik ondersteuning voor de vLLM GPU Server?
Benchmarksectie raadplegen om uw vLLM-installatie te vergelijken met onze prestatietests, met focus op resultaten bij multiconcurrentie.
Bonus over vLLM Authenticatie: Hoe een Api Key in te stellen en te gebruiken
Een met OpenAI-compatibele API, maar vergt standaard geen echte API-sleutel
U heeft twee opties:
Optie 1: Gebruik een neppe sleutel (standaard, het gemakkelijkst)
Als authenticatie niet wordt afgedwongen, kunt u elke willekeurige tekstreeks als de API-sleutel gebruiken.
curl
-H "Authorization: Bearer dummy-key"
Node.js
apiKey: "dummy-key"
Dit is voldoende voor de meeste interne, privé- of beveiligde netwerkimplementaties.
Optie 2: Stel een echte API-sleutel in (aanbevolen voor openbare eindpunten)
U kunt een API-sleutel afdwingen door deze in te stellen als een omgevingsvariabele bij het starten van de container.
In het any-docker-sjabloon (start_args):
--env OPENAI_API_KEY=your-secret-key
vLLM zal dan deze sleutel vergen bij elke aanvraag.
Voorbeeld cURL-aanvraag:
curl https://your-endpoint/v1/models \
-H "Authorization: Bearer your-secret-key"
Voorbeeld Node.js:
const client = new OpenAI({
apiKey: "your-secret-key",
baseURL: "https://your-endpoint/v1",
});
Hoe de sleutel te roteren of te wijzigen
- Bijwerken
OPENAI_API_KEYin de template - Klik op “sjabloon bijwerken”
- Oude sleutels werken onmiddellijk niet meer
Samenvatting
- Geen sleutel nodig → gebruik
dummy-key - Openbaar eindpunt → instellen
OPENAI_API_KEY - De sleutel wordt nooit automatisch gegenereerd; u definieert deze zelf
Dit houdt authenticatie eenvoudig en expliciet.
Voorbeeld 2: Qdrant uitvoeren op een GPU-server
Qdrant is een hoogprestatie vector database die similarity search, semantische zoekopdrachten en embeddings op schaal ondersteunt.
Wanneer Qdrant wordt ingezet op een GPU-gestuurde Trooper.AI server, kan deze miljoenen vectoren extreem snel indexeren en doorzoeken – perfect voor RAG-systemen, LLM-geheugen, personalisatie-engines en aanbevelingssystemen.
De volgende handleiding laat zien hoe je Qdrant kunt draaien met behulp van Docker, hoe het eruitziet in het dashboard en hoe je het correct kunt afvragen met gebruikmaking van Node.js
De Qdrant Docker Container uitvoeren
Je kunt eenvoudig de officiële qdrant/qdrant Docker container met de instellingen hieronder.
Deze screenshots tonen een typische configuratie die gebruikt wordt op Trooper.AI GPU servers, inclusief:
- Blootgestelde REST API-poort
- Dashboardtoegang
- Gegevenspersistentie
- Optionele GPU-versnelling (indien ingeschakeld in uw omgeving)
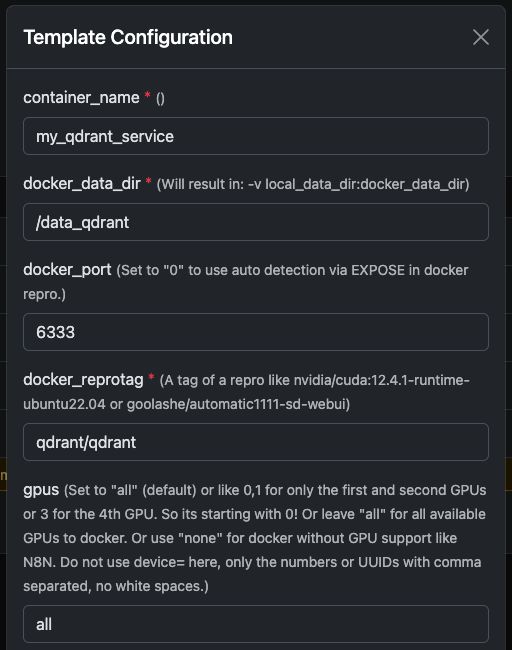
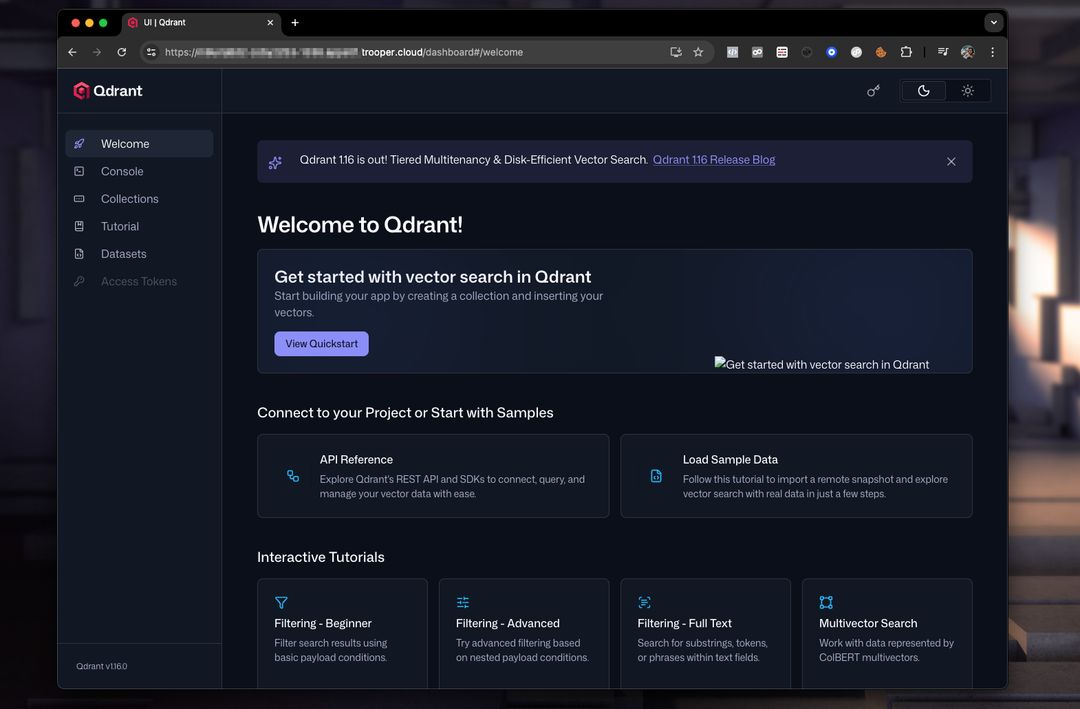
Qdrant Dashboard en de REST API zijn direct beschikbaar nadat deze is gestart.
Qdrant Dashboard Voorbeeld
Het dashboard stelt u in staat om collecties, vectoren, payloads en indexen te inspecteren.
Een typische dashboard-instelling ziet er als volgt uit:
Vanaf hier kunt u:
- Collecties maken
- Vectoren toevoegen
- Voer voorbeeldzoekopdrachten uit
- Inspecteer metadata
- Prestaties monitoren
Qdrant bevragen vanuit Node.js
Een werkende en gecorrigeerde Node.js voorbeeldgebruik van de Qdrant REST API.
Belangrijke correcties ten opzichte van het originele voorbeeld:
- Qdrant vereist het aanroepen van een endpoint zoals:
/collections/<collection_name>/points/search vectormoet een array zijn, geen[a, b, c]- Moderne Node.js heeft native
fetch, dus geen behoefte aannode-fetch
NODEJS VOORBEELD
// Qdrant Vector Search Example – fully compatible with Qdrant 1.x and 2.x
async function queryQdrant() {
// Replace "my_collection" with your actual collection name
const url = 'https://AUTOMATIC-SECURE-URL.trooper.ai/collections/my_collection/points/search';
const payload = {
vector: [0.1, 0.2, 0.3, 0.4], // Must be an array
limit: 5
};
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
});
if (!response.ok) {
throw new Error(`Qdrant request failed with status: ${response.status}`);
}
const data = await response.json();
console.log('Qdrant Response:', data);
return data;
} catch (error) {
console.error('Error querying Qdrant:', error);
return null;
}
}
queryQdrant();
Geldige Qdrant Zoek Payload
Qdrant verwacht een JSON body zoals dit:
{
"vector": [0.1, 0.2, 0.3, 0.4],
"limit": 5
}
Waar:
- vector → uw embeddings
- limiet → maximaal aantal teruggegeven resultaten
U kunt ook geavanceerde filters toevoegen indien nodig:
{
"vector": [...],
"limit": 5,
"filter": {
"must": [
{ "key": "category", "match": { "value": "news" } }
]
}
}
Opmerkingen voor Trooper.AI Gebruikers
- Vervang
AUTOMATIC-SECURE-URL.trooper.aimet uw toegewezen beveiligde eindpunt - Zorg ervoor dat uw collectie bestaat voordat u de query uitvoert
Voorbeeld: N8N uitvoeren met Any Docker
In dit voorbeeld configureren we Any Docker met uw instellingen voor n8n en persistente gegevensopslag, zodat herstarten mogelijk is zonder dat gegevens verloren gaan. Deze configuratie omvat geen webhooks. Heb je wel webhooks nodig? Ga dan naar de gespecialiseerde voorgeconfigurdeerd sjabloon:
Deze handleiding is uitsluitend bedoeld ter verduidelijking. U kunt elke Docker-container starten die u wilt.
Bekijk de screenshots van de configuratie hieronder:
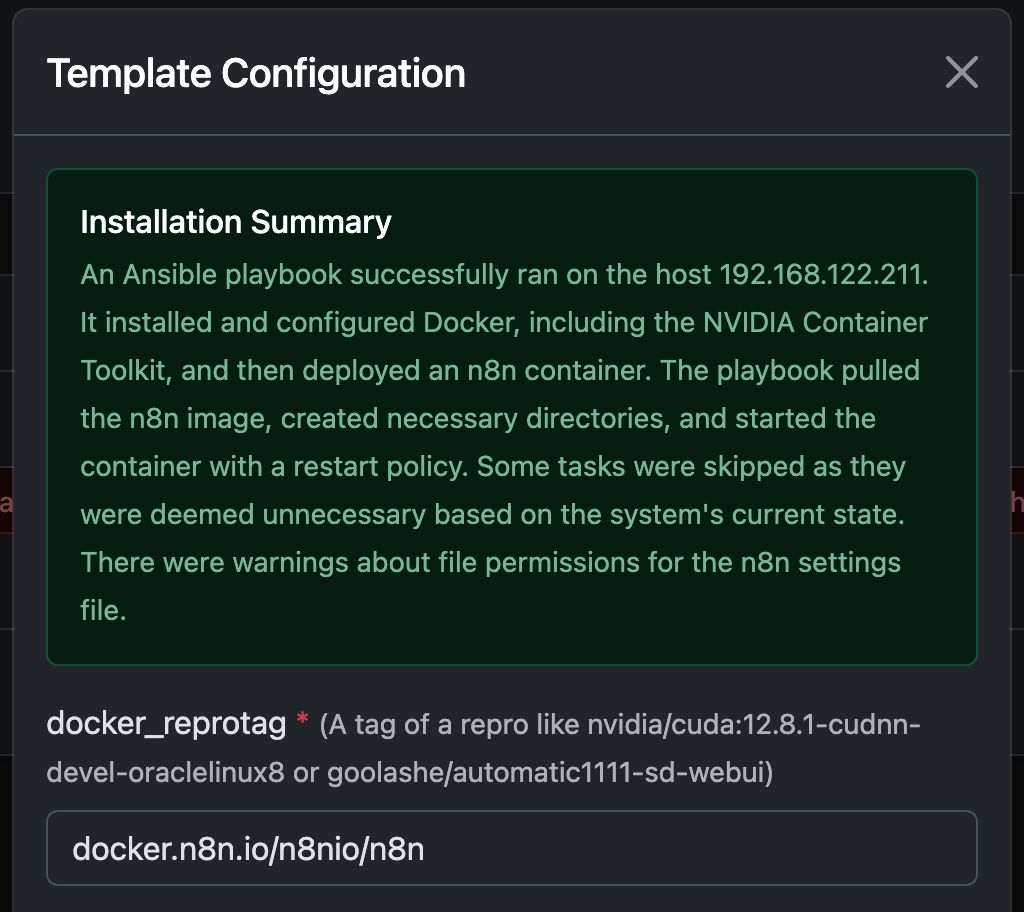
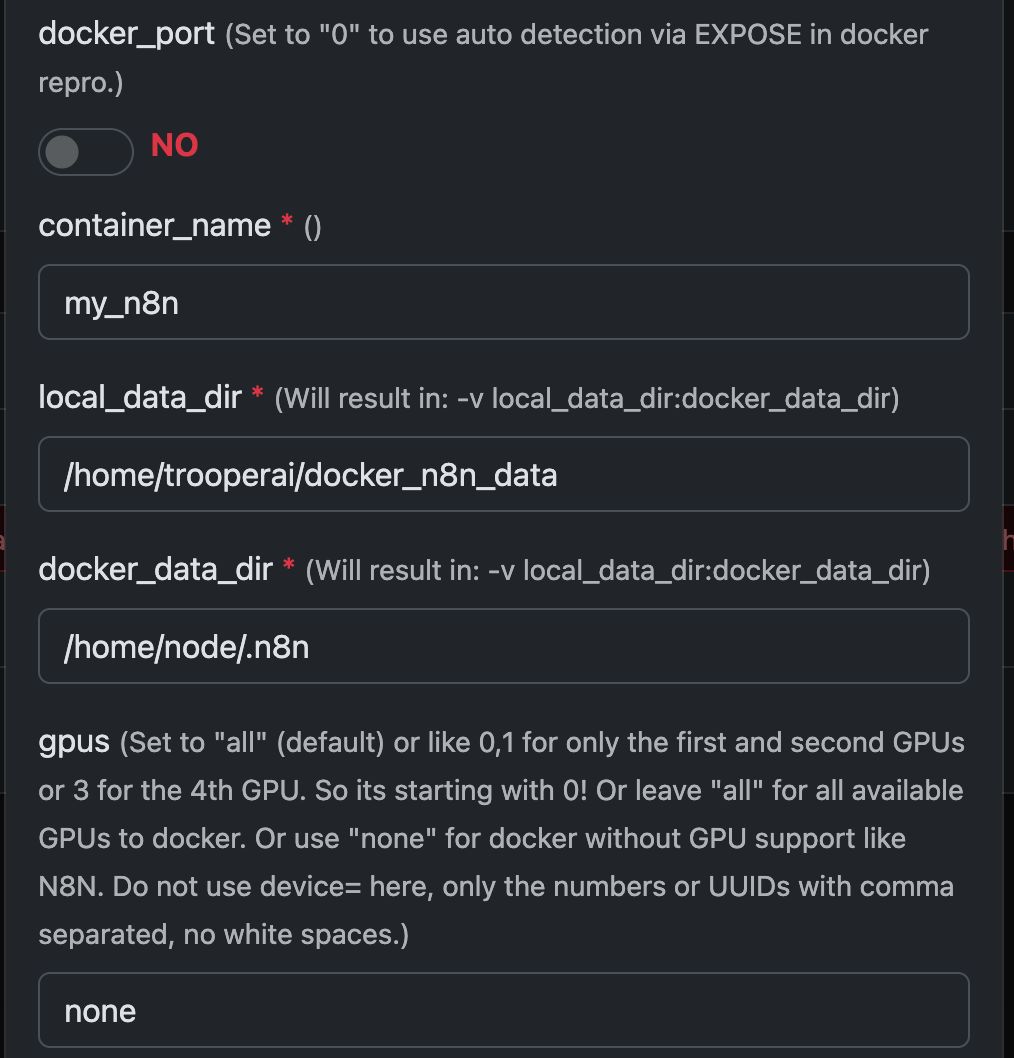
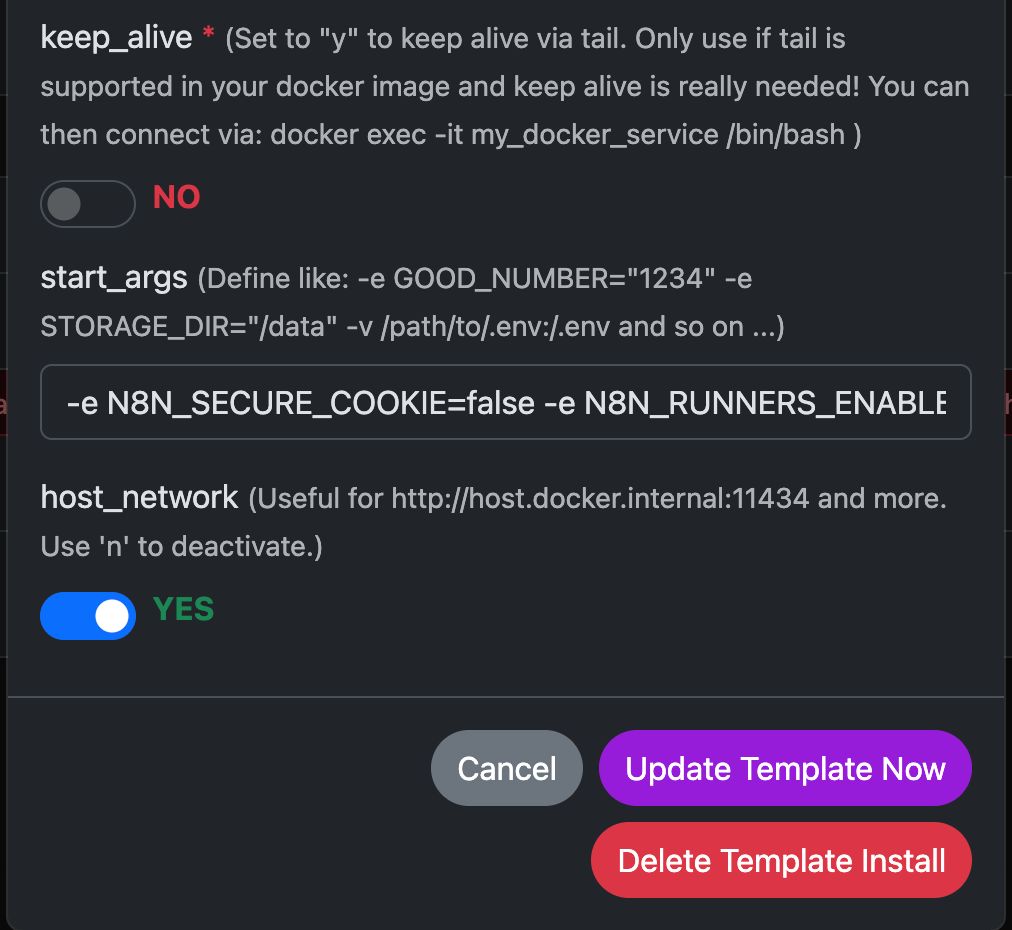
Het Docker Commando ‘Under The Hood’
Deze template automatiseert de volledige setup van een GPU-geactiveerde Docker container, inclusief de installatie van alle benodigde Ubuntu pakketten en afhankelijkheden voor NVIDIA GPU ondersteuning. Dit vereenvoudigt het proces, met name voor gebruikers die gewend zijn aan Docker deployments voor webservers, welke vaak een complexere configuratie vereisen.
Het volgende docker run De command wordt automatisch gegenereerd door de template om uw gekozen GPU-container te lanceren. Het omvat alle vereiste instellingen voor optimale prestaties en compatibiliteit met uw Trooper.AI server.
Deze opdracht dient als een illustratief voorbeeld om ontwikkelaars inzicht te geven in de onderliggende processen:
docker run -d \
--name ${CONTAINER_NAME} \
--restart always \
--gpus ${GPUS} \
--add-host=host.docker.internal:host-gateway \
-p ${PUBLIC_PORT}:${DOCKER_PORT} \
-v ${LOCAL_DATA_DIR}:/home/node/.n8n \
-e N8N_SECURE_COOKIE=false \
-e N8N_RUNNERS_ENABLED=true \
-e N8N_HOST=${N8N_HOST} \
-e WEBHOOK_URL=${WEBHOOK_URL} \
docker.n8n.io/n8nio/n8n \
tail -f /dev/null
Gebruik dit commando niet handmatig als u geen Docker-expert bent! Vertrouw gewoon op de template.
Wat maakt N8N mogelijk op de private GPU-server?
n8n ontgrendelt de mogelijkheid om complexe workflows rechtstreeks op je Trooper.AI GPU-server uit te voeren. Dit betekent dat je taken zoals beeld-/videoverwerking, gegevensanalyse, interacties met LLMs en meer kunt automatiseren – waarbij je gebruikmaakt van de rekenkracht van de GPU voor versnelde prestaties.
Concreet kunt u workflows uitvoeren voor:
- Afbeelding/video-manipulatie: Automatiseer het aanpassen van afmetingen, watermarkeren, objectdetectie en andere visuele taken.
- Gegevensverwerking: Extrahteren, transformeren en laden van gegevens uit verschillende bronnen.
- LLM-integratie: Verbinding maken met en interageren met grote taalmodellen voor taken zoals tekstgeneratie, vertaling en sentimentele analyse.
- Webautomatisering: Automatiseer taken over verschillende websites en API's.
- Aangepaste workflows: Bouw en deploy elke geautomatiseerde proces die perfect aansluit bij jouw behoeften.
Houd er rekening mee dat u AI-tools zoals ComfyUI en Ollama moet installeren om ze te integreren in uw N8N-workflows op de server lokaal. U heeft ook voldoende GPU VRAM nodig om alle modellen van stroom te voorzien. Geef die GPU's niet aan de docker die N8N uitvoert.
Wat is Docker in relatie tot een GPU-server?
Op een Trooper.AI GPU-server stelt Docker u in staat om applicaties met hun afhankelijkheden te verpakken in gestandaardiseerde eenheden die containers worden genoemd. Dit is bijzonder krachtig voor GPU-versnelde workloads, omdat het consistentie over verschillende omgevingen waarborgt en de implementatie vereenvoudigt. In plaats van afhankelijkheden rechtstreeks op het hostbesturingssysteem te installeren, bevatten Docker-containers alles wat een applicatie nodig heeft om te draaien – inclusief bibliotheken, systeemtools, runtime en instellingen.
Voor GPU-toepassingen maakt Docker het mogelijk om de GPU-bronnen van de server efficiënt te benutten. Door gebruik te maken van de NVIDIA Container Toolkit, kunnen containers toegang krijgen tot de GPU's van de host, waardoor versnelde berekeningen mogelijk worden voor taken zoals machine learning, deep learning inference en data-analyse. Deze isolatie verbetert ook de beveiliging en het resourcebeheer, waardoor meerdere applicaties de GPU kunnen delen zonder elkaar te verstoren. Het implementeren en schalen van GPU-gebaseerde applicaties wordt aanzienlijk eenvoudiger met Docker op een Trooper.AI server.
Meer Docker om te draaien
Je kunt gemakkelijk meerdere Docker containers draaien en hulp vragen via: Ondersteuning contacten