OpenWebUI & Ollama
Le modèle OpenWebUI & Ollama propose une interface de discussion IA auto-hébergée préconfigurée avec une intégration directe des modèles linguistiques puissants comme Gemma, Qwen, Llama ou DeepSeek via Ollama . Il inclut une configuration optimisée pour un fonctionnement fluide sans paramétrage supplémentaire.
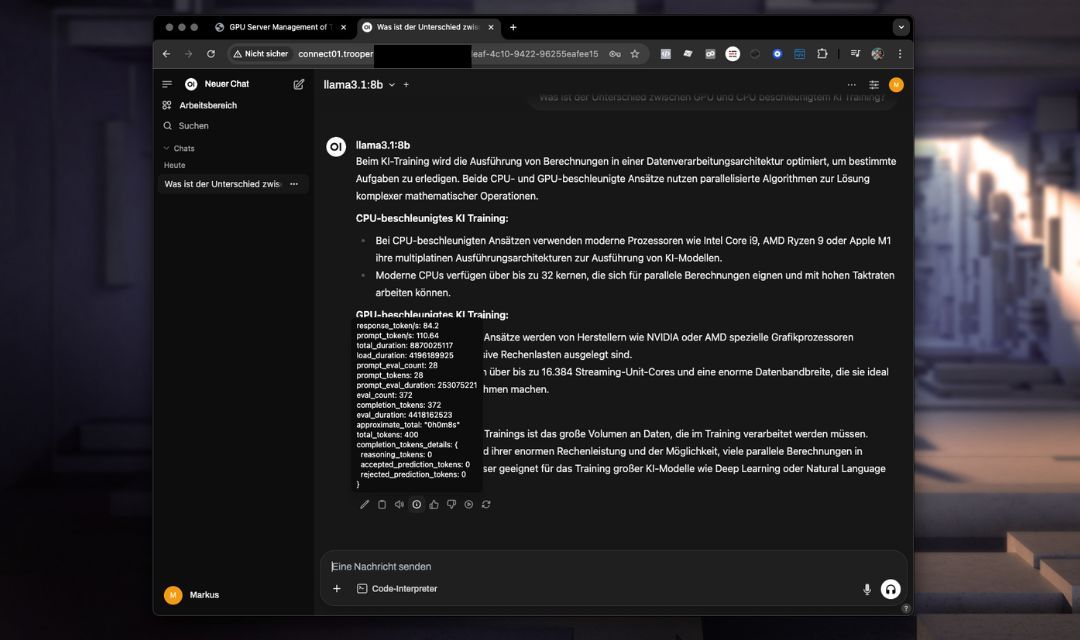
Ce modèle utilise les capacités avancées de l'API d'OpenWebUI, offrant une gestion améliorée des conversations, la persistance du contexte et une intégration rationalisée par rapport à l'API plus simple d'Ollama.
Vous pouvez spécifier la version d’OpenWebUI à installer. La valeur par défaut est notre dernière version testée ; cependant, vous êtes libre de mettre à niveau ou rétrograder selon vos besoins. Indiquez simplement la version souhaitée dans la configuration du modèle après le déploiement du serveur.
Déploiement Entreprise avec OpenWebUI ⚙️🔒
OpenWebUI offre une base solide pour mettre en œuvre des solutions de chat internes sécurisées, évolutives à l'échelle entreprise 📊✨. Son architecture permet aux organisations de développer des flux de travail de communication alimentés par l'IA, adaptés aux exigences métiers.
Déployé dans une infrastructure totalement conforme au RGPD 🛡️🌍, OpenWebUI garantit une protection des données de bout en bout tout en maintenant l'efficacité opérationnelle. La plateforme combine des mesures de sécurité aux normes industrielles avec des options de configuration flexibles, ce qui la rend idéale pour les environnements d'entreprise où confidentialité et respect des réglementations sont des priorités critiques 🎯📋.
Les principaux avantages incluent :
- ✅ Protocoles d’authentification sécurisés
- ✅ Contrôle d'accès basé sur les rôles
- ✅ Capacités de journalisation des audits
- ✅ Intégration avec les écosystèmes informatiques existants
Fonctionnalités et Capacités
- Interface web avancée : Expérience de discussion intuitive accessible directement depuis votre navigateur.
- Capacités API améliorées : gestion optimisée des contextes de conversation et intégration simplifiée avec les applications externes.
- Utilisation optimisée des modèles : Modèles préinstallés prêts à l'emploi.
- Environnement intégré : Environnement entièrement préconfiguré incluant les paramètres de ports et les configurations nécessaires.
- Sécurisé et Personnalisable : Configuration simple pour les identifiants sécurisés et les paramètres spécifiques à l'utilisateur.
Installation
Il suffit d’ajouter le modèle « OpenWebUI & Ollama » à votre serveur GPU Trooper.AI : l’installation se fait entièrement automatiquement. Si vous le souhaitez, il peut également télécharger directement un modèle de langage (LLM) depuis [ollama.com](https://ollama.com). Vous pouvez configurer cela dans la boîte de dialogue Configuration du Modèle.
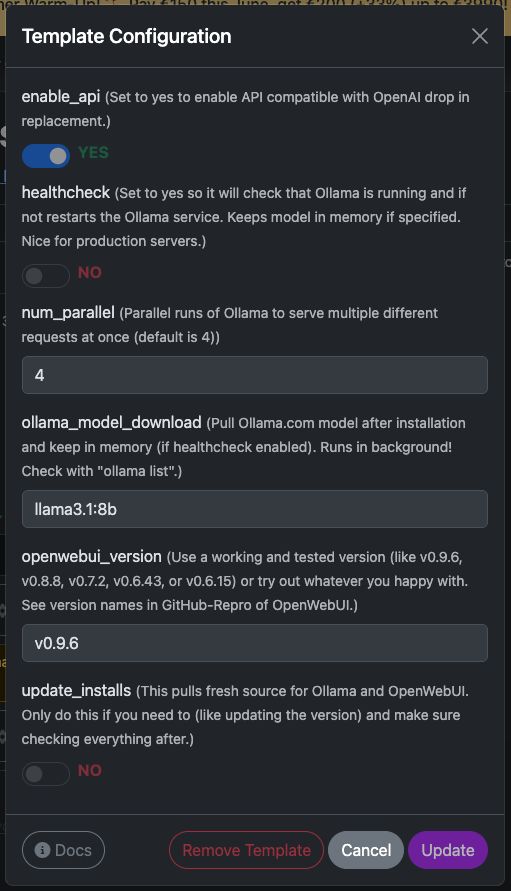
Mais bien sûr, vous pouvez toujours télécharger des modèles via OpenWebUI après l'installation.
Options supplémentaires :
Mises à jour des installations :
Cette option récupère la dernière version de Ollama et d’OpenWebUI. Utilisez-la uniquement si nécessaire, puis vérifiez tout par la suite.
Bien sûr, vous pouvez aussi effectuer une mise à jour manuelle depuis le terminal, mais n’oubliez pas d’installer les dépendances également.
Cette fonction gère tout pour vous – pratique et automatisée !Activer la vérification de santé :
Définissez cette valeur surouipour activer une vérification qui garantit que le service Ollama est en cours d'exécution et répond via son API interne.
Si ce n'est pas le cas, la vérification redémarre automatiquement le service.
Le script se trouve à l'emplacement suivant :/usr/local/bin/ollama-health.sh. Le service peut être contrôlé avec :
sudo service ollama-health stop/démarrer/statut.
Cela est particulièrement utile pour les serveurs de production.
Accéder à OpenWebUI
Après avoir déployé votre instance de serveur Trooper.AI avec le modèle OpenWebUI & Ollama, accédez-y via votre URL sécurisée :
🔒 https://your-secure-hostname.trooper.ai
Ou cliquez sur le numéro de port à côté du modèle OpenWebUI :
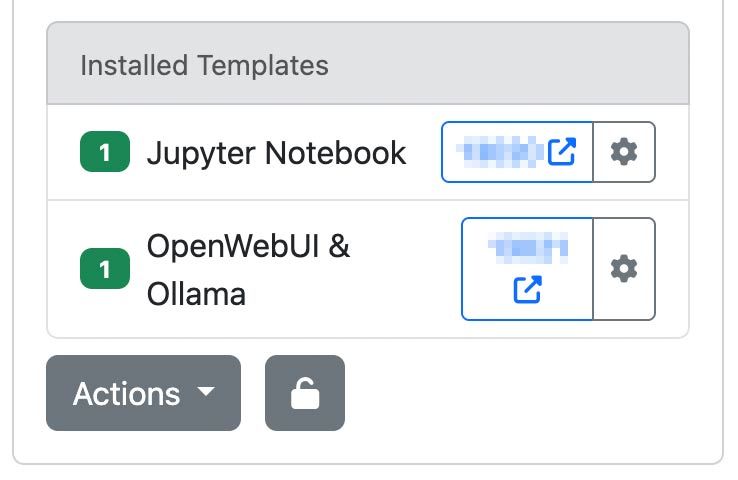
Vous configurerez les identifiants de connexion initiaux lors de votre première connexion. Assurez-vous de conserver ces identifiants en lieu sûr, car ils seront nécessaires pour les accès ultérieurs.
Cas d'utilisation recommandés
Le modèle OpenWebUI & Ollama est idéal pour :
- Collaboration en équipe via chat IA
- Déploiements d'assistants IA personnels
- Développement et prototypage rapides d'applications d'IA conversationnelle
- Utilisation de l'API et création/connexion d'agents en remplacement de l'API OpenAI
- À des fins éducatives et de recherche
LLM à tester
À notre humble avis, voici quelques modèles pour vous aider à démarrer :
- GPT-OSS : Modèle à poids ouverts d’OpenAI, adapté au raisonnement, aux tâches agentiques et au développement. Fonctionne efficacement sur les instances Explorer, Conqueror (
(16 Go de VRAM) ) et Sparbox ((24 Go de VRAM) ). https://ollama.com/library/gpt-oss:20b - DeepSeek-R1 : Un modèle de raisonnement ouvert hautement performant, comparable à O3 et Gemini 2.5 Pro. Optimisé pour les machines StellarAI dotées de 48 Go de VRAM. https://ollama.com/library/deepseek-r1:70b
- Gemma 3 : Actuellement l’un des modèles les plus performants pour une utilisation sur une seule carte graphique. Alimente
Trooper.AI’s James sur les instances Sparbox. https://ollama.com/library/gemma3:27b
Retrouvez plus de modèles de langage ici : https://ollama.com/search (ceux-ci sont tous compatibles avec OpenWebUI !)
Considérations techniques
Configuration requise
Assurez-vous que l'utilisation de la VRAM de votre modèle ne dépasse pas 85 % de la capacité afin d'éviter une dégradation significative des performances.
- VRAM GPU recommandée : 24 Go
- Stockage : au moins 180 Go d'espace disponible
Environnement préconfiguré
- Ollama et OpenWebUI sont préinstallés et entièrement intégrés.
- Les paramètres de port et toutes les configurations nécessaires sont déjà établis, ne nécessitant aucune configuration manuelle supplémentaire.
- Les répertoires d'installation et les variables d'environnement sont prédéfinis pour une utilisation immédiate.
Persistance des données
Toutes vos interactions de chat, les configurations des modèles et les paramètres utilisateur sont stockés en toute sécurité sur votre serveur.
Connexion via une API compatible OpenAI
OpenWebUI fournit une interface API compatible OpenAI, permettant une intégration transparente avec les outils et les applications qui prennent en charge le format OpenAI. Cela permet aux développeurs d'interagir avec des modèles auto-hébergés comme llama3 comme s'ils communiquaient avec l'API OpenAI officielle, ce qui est idéal pour intégrer l'IA conversationnelle dans vos services, scripts ou flux d'automatisation.
Premiers pas : Préparation
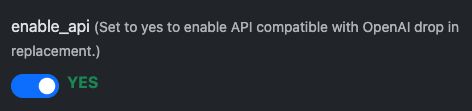
L'API est activée par défaut, mais vérifiez dans la configuration du modèle :
Après cela, activez la création de clés API pour tous les utilisateurs :
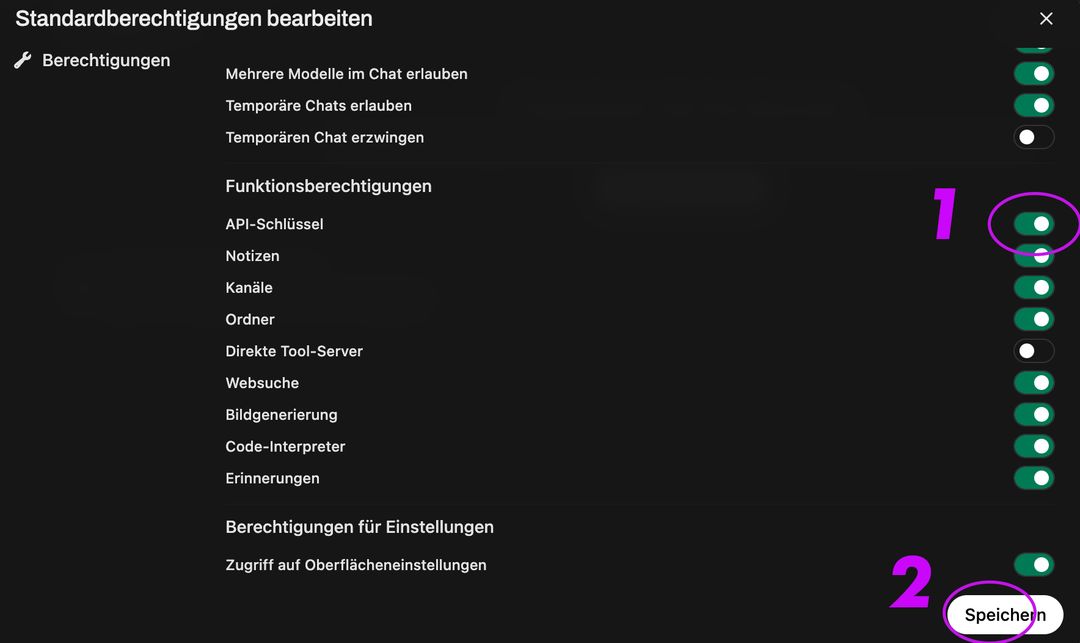
Ensuite, allez dans Groupe et Groupe par défaut, activez la création de clé API, cliquez sur enregistrer :
Cela activera le point de terminaison :
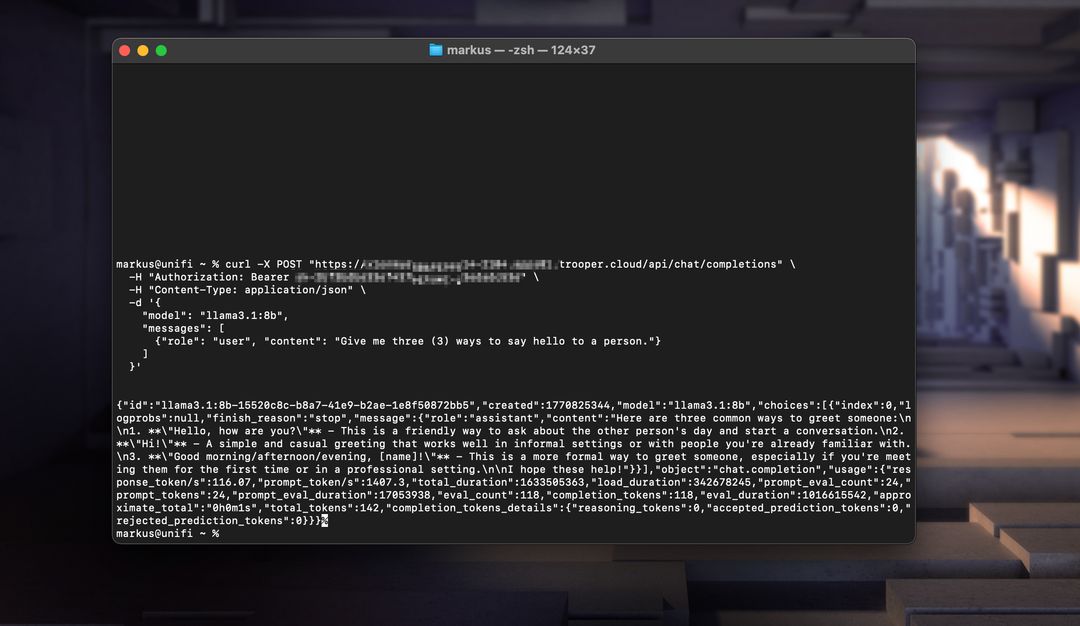
Voici deux exemples fonctionnels : un utilisant Node.js et l'autre utilisant curl.
Exemple Node.js
const axios = require('axios');
const response = await axios.post('https://your-secure-hostname.trooper.ai/api/chat/completions', {
model: 'llama3',
messages: [{ role: 'user', content: 'Hello, how are you?' }],
}, {
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer YOUR_API_KEY'
}
});
console.log(response.data);
Assurez-vous que les appels d'API utilisent
/api/...plutôt que/v1/...car c'est le format requis pour OpenWebUI.
Exemple cURL
curl https://your-secure-hostname.trooper.ai/api/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "llama3",
"messages": [
{ "role": "user", "content": "Hello, how are you?" }
]
}'
Remplacez VOTRE_CLE_API par le jeton réel généré dans l’interface OpenWebUI sous Utilisateur → Paramètres → Compte → Clés API. Ne pas accéder au tableau de bord administrateur : l’accès à l’API est spécifique à chaque utilisateur ! Voir ici :
Après cela, allez ici :
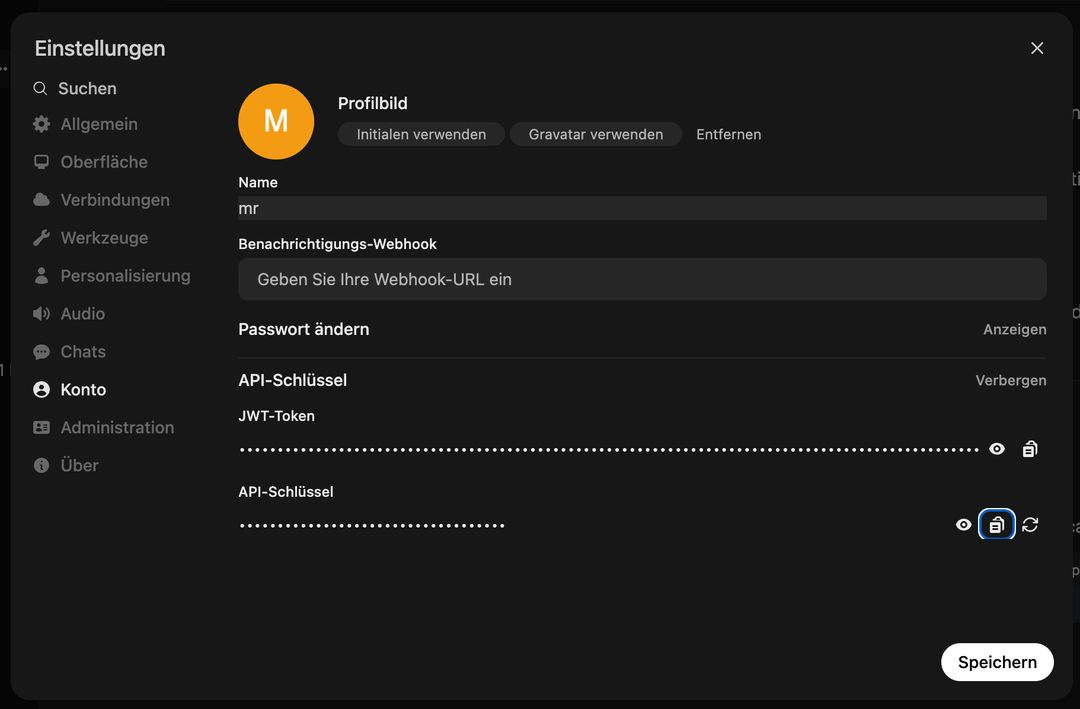
Vous pouvez utiliser cette API avec des outils tels que LangChain, N8N, FlowWise, NodeJS-OpenAI, LlamaIndex, ou tout code base supportant la spécification de l'API OpenAI.
Mise à jour d’OpenWebUI
Vous pouvez simplement changer la version de votre OpenWebUI. Attention, les rétrogradations peuvent endommager votre base de données ! Montez toujours en version ou contactez le support.
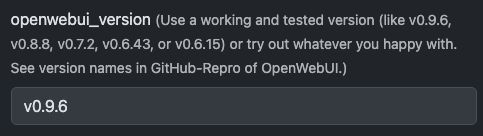
Consultez toutes les versions sur GitHub ici : https://github.com/open-webui/open-webui/releases
Si vous ne souhaitez pas effectuer la mise à jour via le système de modèles, vous pouvez exécuter à tout moment les commandes suivantes pour mettre à jour à la fois OpenWebUI et Ollama :
# Update OpenWebUI:
# 1. Zum OpenWebUI-Verzeichnis wechseln
cd /home/trooperai/openwebui
# 2. Repository aktualisieren
git pull
# 3. Frontend-Abhängigkeiten installieren und neu bauen
npm install
npm run build
# 4. Backend: Python-Venv aktivieren
cd backend
source venv/bin/activate
# 5. Pip aktualisieren & Abhängigkeiten neu installieren
pip install --upgrade pip
pip install -r requirements.txt -U
# 6. OpenWebUI systemd-Dienst neu starten
sudo systemctl restart openwebui.service
# (optional) Update Ollama:
curl -fsSL https://ollama.com/install.sh | sh
sudo systemctl restart ollama.service
Désactiver OpenWebUI
Si vous souhaitez économiser de la VRAM, vous pouvez désactiver OpenWebUI comme suit :
sudo systemctl disable --now openwebui.service
Pour réactiver OpenWebUI, exécutez cette commande dans le terminal :
sudo systemctl enable --now openwebui.service
Support et documentation complémentaires
Pour obtenir de l’aide à l’installation, à la configuration ou au dépannage, veuillez contacter directement l’assistance Trooper.AI :
- Email : [email protected]
- WhatsApp : +49 6126 9289991
Ressources supplémentaires et guides de configuration avancés :