Tout Docker
Ce modèle vous permet de déployer à la fois des conteneurs Docker accélérés par GPU, comme ComfyUI, et des conteneurs sans prise en charge du GPU, tels que n8n. Cette flexibilité permet une large gamme d'applications, allant de la génération d'images par IA aux flux de travail automatisés, le tout dans un environnement unique et gérable. Configurez et exécutez vos conteneurs Docker souhaités sans effort, en tirant parti de la puissance et de la commodité de ce modèle polyvalent.
Bien que vous puissiez préférer gérer directement les configurations Docker, nous recommandons d'utiliser notre modèle « Any Docker » pour la configuration initiale. La configuration de Docker avec un support GPU peut être complexe, et ce modèle offre une base simplifiée pour construire et déployer vos conteneurs.
⚠️ Considération importante pour les conteneurs Docker multiples !
Pour garantir le bon fonctionnement lors de l’exécution de plusieurs conteneurs Docker sur votre serveur GPU, il est essentiel d’attribuer à chaque conteneur un nom et un répertoire de données uniques. Par exemple, au lieu d’utiliser « my_docker_container », spécifiez un nom tel que « my_comfyui_container » et définissez le répertoire de données sur un chemin unique tel que /home/trooperai/docker_comfyui_dataCette simple étape permettra à plusieurs conteneurs Docker de s'exécuter sans conflit.
Exemple 1 : Serveur LLM compatible OpenAI vLLM via HF
Cet exemple explique pas à pas comment exécuter une API compatible vLLM/OpenAI en utilisant le modèle de template any-docker de Trooper.AI.
Il est rédigé pour être compréhensible même avec des connaissances minimales en Docker ou en IA.
Cette configuration utilise Qwen/Qwen3-4B, qui est compatible et exécutable sur tous les serveurs GPU de Trooper.AI.
Ce que cette configuration permet de faire
- Démarre un serveur vLLM à l'intérieur de Docker
- Charge le modèle Qwen/Qwen3-4B depuis Hugging Face
- API HTTP compatible avec OpenAI
- Fonctionne avec les pilotes NVIDIA modernes (CUDA 13 / 580+)
Pourquoi cette configuration est nécessaire
Sur les pilotes NVIDIA plus récents, les anciennes images Docker vLLM peuvent se planter avec des erreurs CUDA au démarrage.
Pour éviter cela, le modèle any-docker :
- Utilise l'image vLLM nuitly
- Charge les bibliothèques de pilotes NVIDIA de l'hôte
Vous n'avez pas besoin de modifier cette logique – utilisez simplement la configuration ci-dessous.
Variables de modèle
Voir ici la capture d'écran pour savoir comment configurer et le texte complet ci-dessous pour copier et coller.
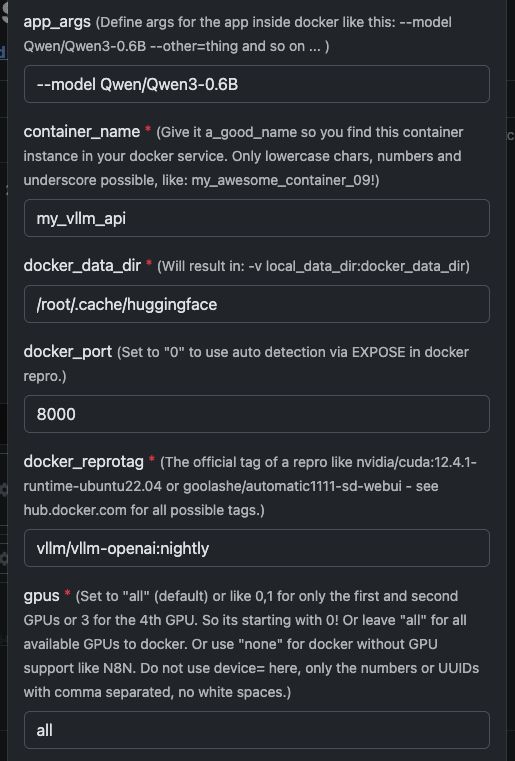
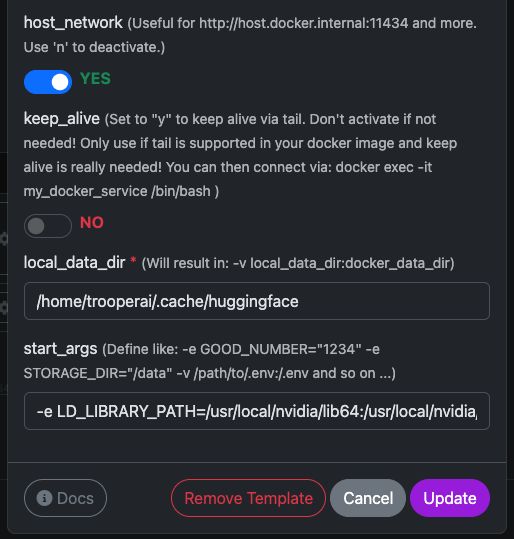
| Variable | Valeur | Ce que cela signifie |
|---|---|---|
app_args |
--model Qwen/Qwen3-4B |
Définit quel modèle vLLM doit charger. |
container_name |
my_vllm_api |
Nom du conteneur Docker. |
docker_reprotag |
vllm/vllm-openai:nightly |
Image vLLM avec des corrections pour les pilotes NVIDIA modernes. |
docker_port |
8000 |
Port interne utilisé par vLLM. |
gpus |
all |
Rend tous les GPU disponibles pour Docker. |
host_network |
YES |
Expose l'API directement sur le réseau hôte. |
keep_alive |
NO |
Cycle de vie normal du conteneur (recommandé). |
local_data_dir |
/home/trooperai/.cache/huggingface |
Répertoire du cache du modèle sur l'hôte. |
docker_data_dir |
/root/.cache/huggingface |
Répertoire de cache du modèle à l'intérieur du conteneur. |
start_args |
-e LD_LIBRARY_PATH=/usr/local/nvidia/lib64:/usr/local/nvidia/lib:/usr/lib/x86_64-linux-gnu --ipc=host --env HF_TOKEN=… |
Correction requise pour CUDA + mémoire partagée. |
Remarque importante LD_LIBRARY_PATH
Cette configuration est obligatoire sur les systèmes avec CUDA 13.
Sans elle, vLLM peut échouer au démarrage en raison d'incompatibilités entre le pilote et NVIDIA.
Ne supprimez pas cette ligne.
Comment vérifier si cela fonctionne
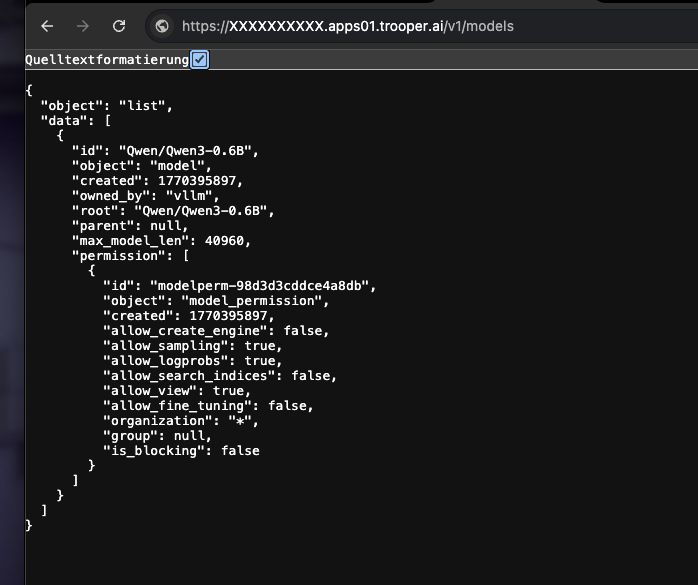
Exécutez la commande suivante :
curl https://XXXXXXXX.apps01.trooper.ai/v1/models
Si vous voyez Qwen/Qwen3-4B dans la réponse, le serveur fonctionne correctement.
Exemple d'utilisation avec curl
curl https://XXXXXXXX.apps01.trooper.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer dummy-key" \
-d '{
"model": "Qwen/Qwen3-4B",
"messages": [
{ "role": "user", "content": "What is Trooper.AI?" }
]
}'
Exemple d'utilisation avec Node.js
Requête simple
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const result = await client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: "What is Trooper.AI?" }],
});
console.log(result.choices[0].message.content);
Test de charge concurrent Node.js (16 requêtes parallèles)
Cet exemple envoie 16 requêtes simultanées à l'API et affiche un résumé simple du débit.
import OpenAI from "openai";
import crypto from "crypto";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const CONCURRENCY = 16;
function randomPrompt() {
return `Explain this random concept in one sentence: ${crypto.randomUUID()}`;
}
const startTime = Date.now();
const requests = Array.from({ length: CONCURRENCY }, () =>
client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: randomPrompt() }],
})
);
const responses = await Promise.all(requests);
const endTime = Date.now();
const durationSeconds = (endTime - startTime) / 1000;
let totalTokens = 0;
for (const r of responses) {
totalTokens += r.usage.total_tokens;
}
const tokensPerSecond = (totalTokens / durationSeconds).toFixed(2);
console.log(
`${tokensPerSecond} token/s of total ${totalTokens} tokens in ${durationSeconds.toFixed(
2
)} seconds on ${CONCURRENCY} concurrent connections`
);
Ce test est utile pour :
- vérification de la concurrence
- estimation du débit
- vérifications rapides de la conformité des performances
Comment obtenir de l'assistance pour le serveur GPU vLLM ?
Consultez notre section Benchmark pour comparer votre installation de vLLM avec nos tests de performances, en vous concentrant sur les résultats en multi-concurrence.
Bonus concernant l'authentification vLLM : comment définir et utiliser une clé API
Une API compatible avec OpenAI, mais ne nécessite pas une clé API réelle par défaut
Vous avez deux options :
Option 1 : Utiliser une clé factice (par défaut, le plus simple)
Si l’authentification est non imposée, vous pouvez utiliser n’importe quelle chaîne de caractères comme clé API.
curl
-H "Authorization: Bearer dummy-key"
Node.js
apiKey: "dummy-key"
Cela suffit pour la plupart des déploiements internes, privés ou sur des réseaux sécurisés.
Option 2 : Définir une vraie clé API (recommandé pour les points de terminaison publics)
Vous pouvez appliquer une clé API en la définissant comme variable d’environnement lors du démarrage du conteneur.
Dans le modèle any-docker (arguments de démarrage) :
--env OPENAI_API_KEY=your-secret-key
vLLM exigera alors cette clé dans chaque demande.
Exemple de requête cURL :
curl https://your-endpoint/v1/models \
-H "Authorization: Bearer your-secret-key"
Exemple avec Node.js :
const client = new OpenAI({
apiKey: "your-secret-key",
baseURL: "https://your-endpoint/v1",
});
Comment faire pivoter ou modifier la clé
- Mise à jour
OPENAI_API_KEYdans le modèle - Cliquez sur « mettre à jour le modèle »
- Les anciennes clés cessent de fonctionner immédiatement
Résumé
- Aucune clé nécessaire → utilisez
dummy-key - Point de terminaison public → définir
OPENAI_API_KEY - La clé est jamais générée automatiquement ; vous la définissez
Ceci maintient l'authentification simple et explicite.
Exemple 2 : Exécution de Qdrant sur un serveur GPU
Qdrant est une base de données vectorielle haute performance qui prend en charge la recherche de similarité, la recherche sémantique et les embeddings à grande échelle.
Déployé sur un serveur Trooper.AI équipé d'un GPU, Qdrant peut indexer et rechercher des millions de vecteurs extrêmement rapidement — idéal pour les systèmes RAG, la mémoire des LLM, les moteurs de personnalisation et les systèmes de recommandation.
Le guide suivant montre comment exécuter Qdrant via Docker, à quoi ressemble son interface d'administration et comment l'interroger correctement en utilisant Node.js
Exécution du conteneur Docker Qdrant
Vous pouvez facilement exécuter l’image officielle qdrant/qdrant Conteneur Docker avec les paramètres indiqués ci-dessous.
Ces captures d'écran montrent une configuration typique utilisée sur les serveurs GPU Trooper.AI, notamment :
- Port REST API exposé
- Accès au tableau de bord
- Persistance des données
- Accélération GPU optionnelle (si activée dans votre environnement)
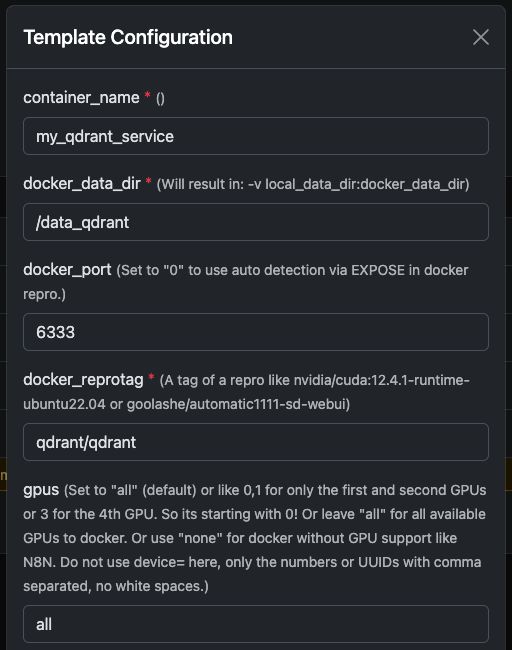
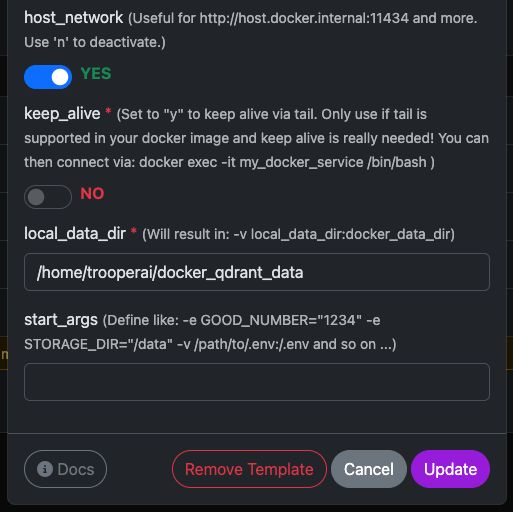
Une fois lancé, vous aurez un accès immédiat à la fois au Tableau de bord Qdrant et à l'API REST.
Aperçu du tableau de bord Qdrant
Le tableau de bord vous permet d’inspecter les collections, les vecteurs, les charges utiles et les index.
Une configuration de tableau de bord typique ressemble à ceci :
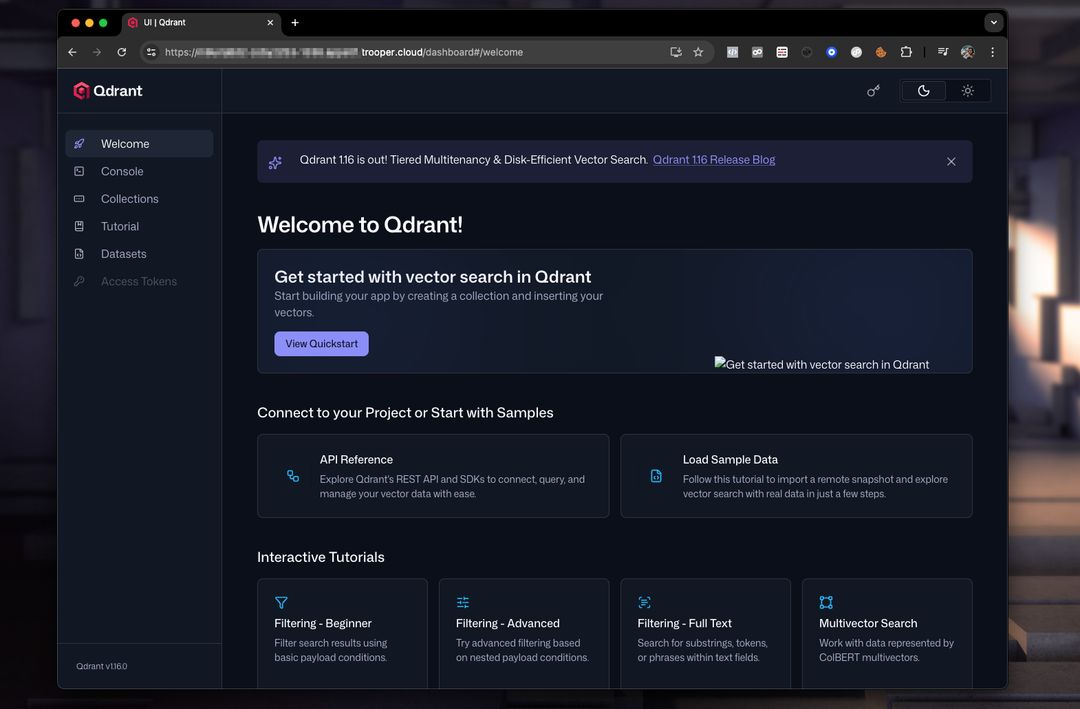
À partir d'ici, vous pouvez :
- Créer des collections
- Ajouter des vecteurs
- Effectuer des recherches d'exemple
- Inspecter les métadonnées
- Surveiller les performances
Interrogation de Qdrant depuis Node.js
Voici un exemple fonctionnel et corrigé en Node.js utilisant l'API REST de Qdrant.
Corrections importantes par rapport à l'exemple original :
- Qdrant nécessite d'appeler une endpoint comme :
/collections/<collection_name>/points/search vecteurdoit être un tableau, et non[a, b, c]- Node.js moderne dispose de fonctionnalités natives
fetch, donc pas besoin denode-fetch
EXEMPLE NODEJS
// Qdrant Vector Search Example – fully compatible with Qdrant 1.x and 2.x
async function queryQdrant() {
// Replace "my_collection" with your actual collection name
const url = 'https://AUTOMATIC-SECURE-URL.trooper.ai/collections/my_collection/points/search';
const payload = {
vector: [0.1, 0.2, 0.3, 0.4], // Must be an array
limit: 5
};
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
});
if (!response.ok) {
throw new Error(`Qdrant request failed with status: ${response.status}`);
}
const data = await response.json();
console.log('Qdrant Response:', data);
return data;
} catch (error) {
console.error('Error querying Qdrant:', error);
return null;
}
}
queryQdrant();
Charge utile de recherche Qdrant valide
Qdrant s'attend à un corps JSON comme ceci :
{
"vector": [0.1, 0.2, 0.3, 0.4],
"limit": 5
}
Où :
- vecteur → votre embedding
- limit → nombre maximal de résultats retournés
Vous pouvez également ajouter des filtres avancés si nécessaire :
{
"vector": [...],
"limit": 5,
"filter": {
"must": [
{ "key": "category", "match": { "value": "news" } }
]
}
}
Notes pour les utilisateurs de Trooper.AI
- Remplacez
AUTOMATIC-SECURE-URL.trooper.aiavec votre point de terminaison sécurisé alloué - Assurez-vous que votre collection existe avant d'effectuer une requête.
Exemple : Exécuter N8N avec Any Docker
Dans cet exemple, configurons Any Docker avec votre configuration pour n8n et un stockage de données persistant afin que les redémarrages soient possibles sans perte des données. Cette configuration ne comprend pas les webhooks. Si vous avez besoin de webhooks, consultez le modèle préconfiguré dédié : n8n
Ce guide est fourni à titre explicatif uniquement. Vous pouvez démarrer n'importe quel conteneur Docker que vous souhaitez.
Veuillez consulter les captures d’écran de la configuration ci-dessous :
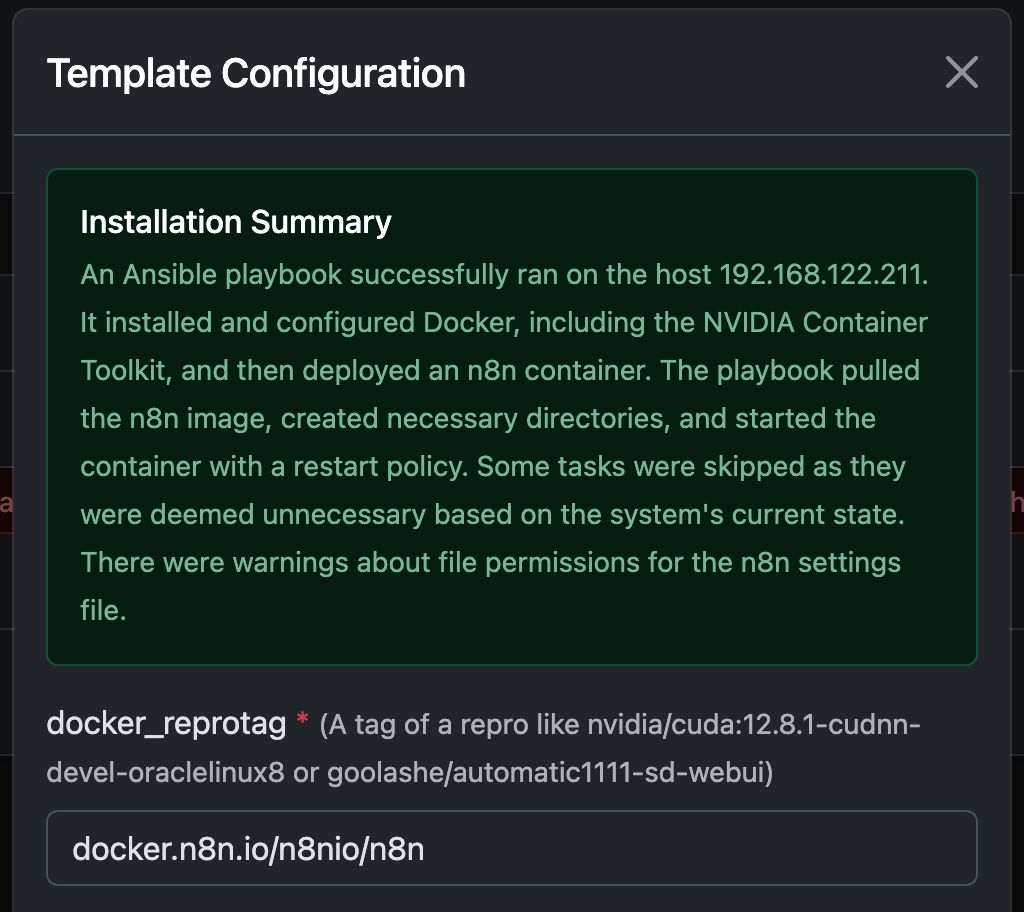
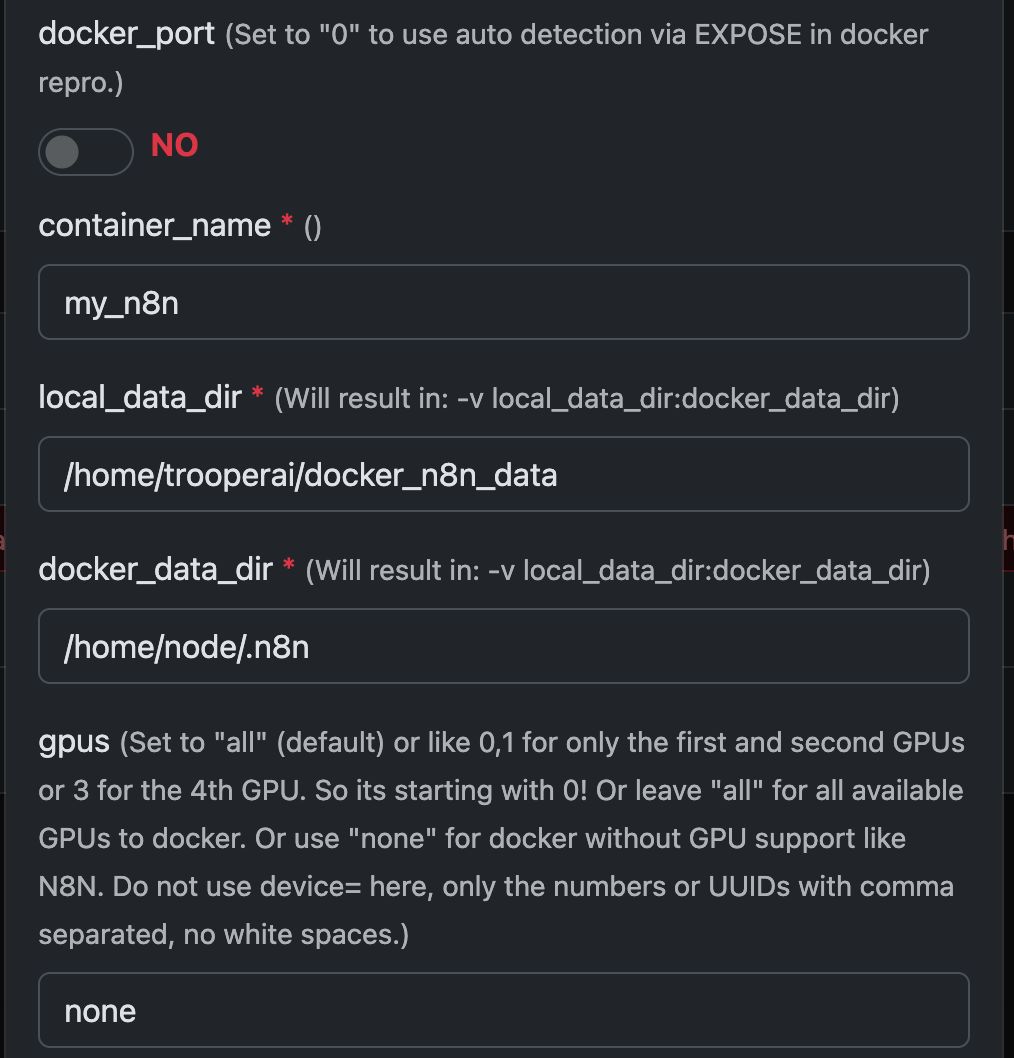
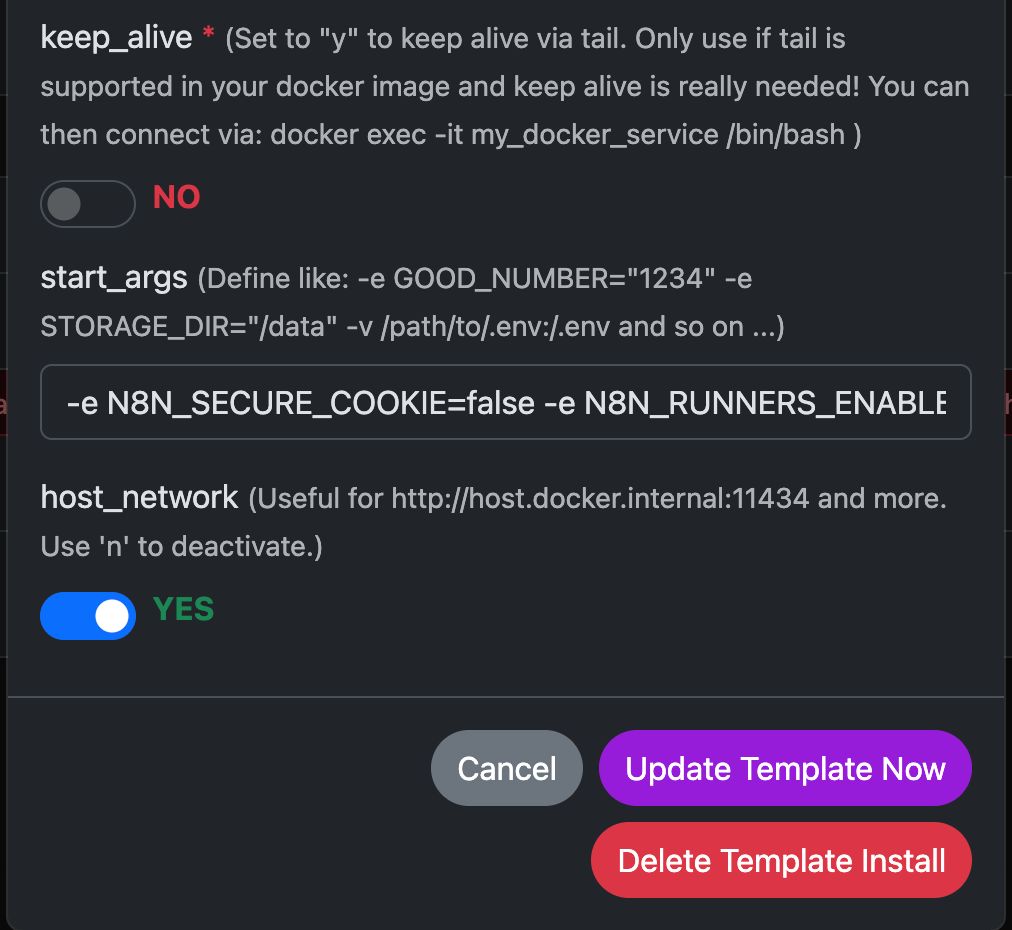
La commande Docker « Sous le capot »
Ce modèle automatise la configuration complète d'un conteneur Docker compatible GPU, y compris l'installation de tous les paquets Ubuntu et des dépendances nécessaires pour le support NVIDIA GPU. Cela simplifie le processus, en particulier pour les utilisateurs habitués aux déploiements Docker pour les serveurs web, qui nécessitent souvent une configuration plus complexe.
Ce qui suit docker run La commande est générée automatiquement par le modèle pour lancer votre conteneur GPU choisi. Elle encapsule tous les paramètres nécessaires pour des performances optimales et la compatibilité avec votre serveur Trooper.AI.
Cette commande sert d'exemple illustratif pour donner aux développeurs un aperçu des processus sous-jacents :
docker run -d \
--name ${CONTAINER_NAME} \
--restart always \
--gpus ${GPUS} \
--add-host=host.docker.internal:host-gateway \
-p ${PUBLIC_PORT}:${DOCKER_PORT} \
-v ${LOCAL_DATA_DIR}:/home/node/.n8n \
-e N8N_SECURE_COOKIE=false \
-e N8N_RUNNERS_ENABLED=true \
-e N8N_HOST=${N8N_HOST} \
-e WEBHOOK_URL=${WEBHOOK_URL} \
docker.n8n.io/n8nio/n8n \
tail -f /dev/null
N'utilisez pas cette commande manuellement si vous n'êtes pas un expert Docker ! Faites simplement confiance au modèle.
Que permet N8N sur le serveur GPU privé ?
n8n déverrouille le potentiel d'exécuter des flux de travail complexes directement sur votre serveur GPU Trooper.AI. Cela signifie que vous pouvez automatiser des tâches impliquant le traitement d'images/vidéos, l'analyse de données, les interactions avec des modèles de langage (LLM), et bien plus encore – en exploitant la puissance du GPU pour une performance accélérée.
Plus précisément, vous pouvez exécuter des workflows pour :
- Manipulation d’images/vidéos : Automatiser le redimensionnement, l’ajout de filigrane (watermarking), la détection d’objets et autres tâches visuelles.
- Traitement des données : Extraction, transformation et chargement de données depuis diverses sources.
- Intégration des LLMs : Se connecter et interagir avec les modèles de langage pour des tâches comme la génération de texte, la traduction et l'analyse des sentiments.
- Automatisation web : Automatiser des tâches sur différents sites et API.
- Flux de travail personnalisés : Concevoir et déployer tout processus automatisé adapté à vos besoins.
Gardez à l’esprit que vous devrez installer des outils d’IA tels que ComfyUI et Ollama pour les intégrer à vos flux de travail N8N sur le serveur localement. Vous aurez également besoin de suffisamment de VRAM GPU pour alimenter tous les modèles. Ne donnez pas ces GPU au conteneur Docker exécutant N8N.
Qu'est-ce que Docker en termes de serveur GPU ?
Sur un serveur GPU Trooper.AI, Docker vous permet de conditionner vos applications avec leurs dépendances dans des unités standardisées appelées conteneurs. Ceci est particulièrement puissant pour les charges de travail accélérées par GPU car cela assure la cohérence entre les différents environnements et simplifie le déploiement. Au lieu d'installer les dépendances directement sur le système d'exploitation hôte, les conteneurs Docker incluent tout ce dont une application a besoin pour fonctionner – y compris les bibliothèques, les outils système, l'environnement d'exécution et les paramètres.
Pour les applications GPU, Docker vous permet d'utiliser efficacement les ressources GPU du serveur. En utilisant NVIDIA Container Toolkit, les conteneurs peuvent accéder aux GPU de l'hôte, permettant ainsi un calcul accéléré pour des tâches telles que l'apprentissage automatique, l'inférence en apprentissage profond et l'analyse de données. Cet isolement améliore également la sécurité et la gestion des ressources, permettant à plusieurs applications de partager le GPU sans s'interférer les unes avec les autres. Le déploiement et la mise à l'échelle des applications basées sur le GPU deviennent beaucoup plus faciles avec Docker sur un serveur Trooper.AI.
Plus de Docker à exécuter
Vous pouvez facilement exécuter plusieurs conteneurs Docker et demander de l'aide via : Contacts d'assistance