Beliebiges Docker
Diese Vorlage ermöglicht Ihnen die Bereitstellung sowohl GPU-beschleunigter Docker-Container wie ComfyUI als auch Container ohne GPU-Unterstützung, wie z.B. n8n. Diese Flexibilität ermöglicht eine breite Palette von Anwendungen, von der KI-Bildgenerierung bis hin zu automatisierten Workflows, alles in einer einzigen, überschaubaren Umgebung. Konfigurieren und starten Sie Ihre gewünschten Docker-Container mühelos und nutzen Sie die Leistung und den Komfort dieser vielseitigen Vorlage.
Obwohl Sie Docker-Konfigurationen gerne direkt verwalten möchten, empfehlen wir Ihnen für den Anfangsaufbau, unseren „Any Docker“-Template zu nutzen. Die Konfiguration von Docker mit GPU-Unterstützung kann komplex sein – dieser Template bietet jedoch eine vereinfachte Grundlage zum Erstellen und Bereitstellen Ihrer Container.
🚨 Wichtiger Hinweis zur Verwendung mehrerer Docker-Container!
Um die ordnungsgemäße Funktion beim Ausführen mehrerer Docker-Container auf Ihrem GPU-Server sicherzustellen, ist es wichtig, jedem Container einen eindeutigen Namen und ein eindeutiges Datenverzeichnis zuzuweisen. Verwenden Sie beispielsweise anstelle von „my_docker_container“ einen Namen wie „my_comfyui_container“ und legen Sie das Datenverzeichnis auf einen eindeutigen Pfad fest, wie /home/trooperai/docker_comfyui_dataDieser einfache Schritt ermöglicht den gleichzeitigen Betrieb mehrerer Docker-Container ohne Konflikte.
Beispiel 1: vLLM OpenAI-kompatibler LLM-Server über HF
Dieses Beispiel erklärt schrittweise, wie man eine OpenAI-kompatible vLLM-API mit dem Trooper.AI-Vorlagen-Template für every-docker ausführt.
Es ist so verfasst, dass es auch mit geringen Vorkenntnissen in Docker oder KI nachvollziehbar ist.
Diese Einrichtung nutzt Qwen/Qwen3-4B, was auf allen Trooper.AI-GPU-Servern unterstützt wird und dort ausführbar ist.
Was diese Einrichtung bewirkt
- einen vLLM-Server innerhalb von Docker startet
- Qwen/Qwen3-4B von Hugging Face lädt
- Eine mit OpenAI kompatible HTTP-API
- Funktioniert mit modernen NVIDIA-Treibern (CUDA 13 / Treiberversion 580+)
Warum diese Konfiguration benötigt wird
Bei neueren NVIDIA-Treibern können ältere vLLM-Docker-Images beim Start mit CUDA-Fehlern abstürzen.
Um dies zu vermeiden, verwendet die any-docker-Vorlage:
- vLLM Nightly-Bild
- NVIDIA-Treiberbibliotheken des Hosts
Sie müssen diese Logik nicht ändern – verwenden Sie einfach die untenstehende Konfiguration.
Vorlagenvariablen
Konfiguration und vollständigen Text finden Sie in der Screenshot-Anleitung unten zum Kopieren und Einfügen.
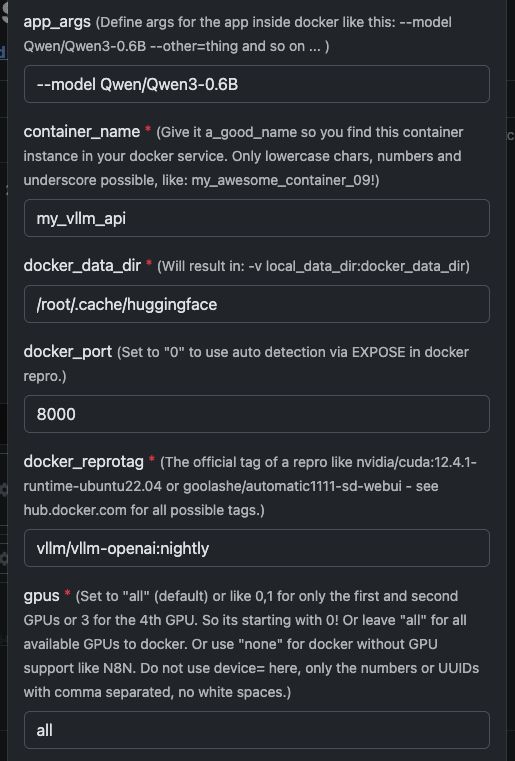
| Variable | Wert | Was es bedeutet |
|---|---|---|
app_args |
--model Qwen/Qwen3-4B |
Definiert, welches Modell vLLM laden soll. |
container_name |
my_vllm_api |
Name des Docker-Containers. |
docker_reprotag |
vllm/vllm-openai:nightly |
vLLM-Image mit Fixes für moderne NVIDIA-Treiber. |
docker_port |
8000 |
Interner Port, der von vLLM verwendet wird. |
gpus |
all |
Stellt alle GPUs für Docker bereit. |
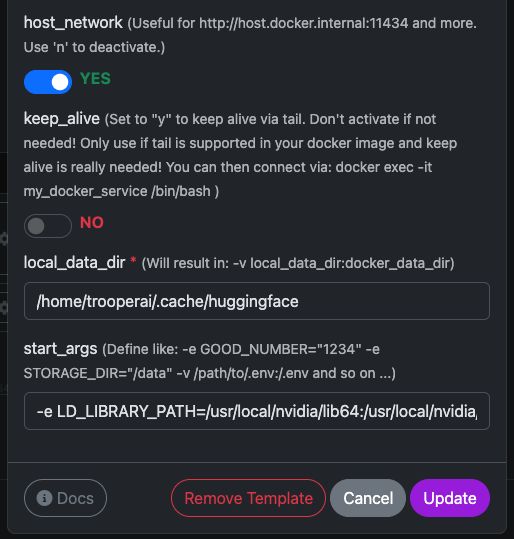
host_network |
YES |
Stellt die API direkt im Host-Netzwerk bereit. |
keep_alive |
NO |
Normaler Container-Lebenszyklus (empfohlen). |
local_data_dir |
/home/trooperai/.cache/huggingface |
Modell-Cache-Verzeichnis auf dem Host. |
docker_data_dir |
/root/.cache/huggingface |
Modell-Cache-Verzeichnis innerhalb des Containers. |
start_args |
-e LD_LIBRARY_PATH=/usr/local/nvidia/lib64:/usr/local/nvidia/lib:/usr/lib/x86_64-linux-gnu --ipc=host --env HF_TOKEN=… |
Erforderliche Korrektur für CUDA + Shared Memory. |
Wichtiger Hinweis LD_LIBRARY_PATH
Diese Einstellung ist verpflichtend bei Systemen mit CUDA 13.
Ohne sie kann es zu Startproblemen von vLLM aufgrund von Inkompatibilitäten der NVIDIA-Treiber kommen.
Löschen Sie dies nicht.
Wie man überprüft, ob es funktioniert
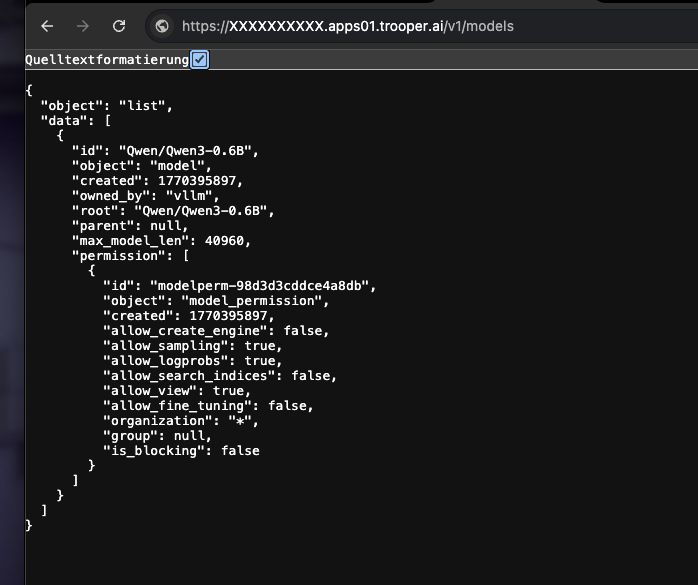
Führen Sie den folgenden Befehl aus:
curl https://XXXXXXXX.apps01.trooper.ai/v1/models
Wenn Sie dies sehen Qwen/Qwen3-4B in der Antwort läuft der Server korrekt.
Beispiel für die Verwendung von curl
curl https://XXXXXXXX.apps01.trooper.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer dummy-key" \
-d '{
"model": "Qwen/Qwen3-4B",
"messages": [
{ "role": "user", "content": "What is Trooper.AI?" }
]
}'
Beispielhafte Verwendung mit Node.js
Einfache Anfrage
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const result = await client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: "What is Trooper.AI?" }],
});
console.log(result.choices[0].message.content);
Node.js Konkurrenzterst (16 parallele Anfragen)
Dieses Beispiel sendet 16 gleichzeitige Anfragen an die API und gibt eine einfache Durchsatzzusammenfassung aus.
import OpenAI from "openai";
import crypto from "crypto";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const CONCURRENCY = 16;
function randomPrompt() {
return `Explain this random concept in one sentence: ${crypto.randomUUID()}`;
}
const startTime = Date.now();
const requests = Array.from({ length: CONCURRENCY }, () =>
client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: randomPrompt() }],
})
);
const responses = await Promise.all(requests);
const endTime = Date.now();
const durationSeconds = (endTime - startTime) / 1000;
let totalTokens = 0;
for (const r of responses) {
totalTokens += r.usage.total_tokens;
}
const tokensPerSecond = (totalTokens / durationSeconds).toFixed(2);
console.log(
`${tokensPerSecond} token/s of total ${totalTokens} tokens in ${durationSeconds.toFixed(
2
)} seconds on ${CONCURRENCY} concurrent connections`
);
Dieser Test ist nützlich für:
- Überprüfung der Parallelität
- Durchsatzschätzung
- schnelle Leistungstests
Wie erhalte ich Support für den vLLM GPU Server?
Bei jedem Problem mit vLLM wenden Sie sich bitte an unseren Support – wir verfügen über umfangreiche Erfahrung in der Nutzung von vLLM: Kontakt zum Support
Beziehen Sie sich auf unseren Benchmark-Bereich, um Ihre vLLM-Installation mit unseren Leistungstests zu vergleichen – insbesondere unter Fokus auf Ergebnisse bei Multi-Konkurrenz.
Bonus zur vLLM-Authentifizierung: So richten Sie einen API-Schlüssel ein und verwenden ihn
Eine mit OpenAI kompatible API, erfordert jedoch standardmäßig keinen echten API-Schlüssel.
Sie haben zwei Optionen:
Option 1: Verwenden Sie einen Dummy-Schlüssel (Standard, am einfachsten)
Falls keine Authentifizierung beliebig als API-Schlüssel verwendet werden kann.
curl
-H "Authorization: Bearer dummy-key"
Node.js
apiKey: "dummy-key"
Dies ist ausreichend für die meisten internen, privaten oder abgesicherten Netzwerkbereitstellungen.
Option 2: Einen echten API-Schlüssel festlegen (empfohlen für öffentliche Endpunkte)
Sie können einen API-Schlüssel erzwingen, indem Sie ihn als Umgebungsvariable beim Starten des Containers festlegen.
Im any-docker-Template unter (Startargumente):
--env OPENAI_API_KEY=your-secret-key
vLLM wird dann diesen Schlüssel in jeder Anfrage verlangen.
Beispiel cURL-Anfrage:
curl https://your-endpoint/v1/models \
-H "Authorization: Bearer your-secret-key"
Beispiel Node.js:
const client = new OpenAI({
apiKey: "your-secret-key",
baseURL: "https://your-endpoint/v1",
});
Wie rotiert oder ändert man den Schlüssel?
- Aktualisieren
OPENAI_API_KEYin der Vorlage - Klicken Sie auf „Vorlage aktualisieren“
- Alte Schlüssel werden sofort deaktiviert.
Zusammenfassung
- Kein Schlüssel erforderlich → verwenden
dummy-key - Öffentlicher Endpunkt → setzen
OPENAI_API_KEY - Der Schlüssel wird niemals automatisch generiert; Sie definieren ihn selbst.
Dies hält die Authentifizierung einfach und explizit.
Beispiel 2: Ausführen von Qdrant auf einem GPU-Server
Qdrant ist eine hochperformante Vektordatenbank, die Ähnlichkeitssuche, semantische Suche und Skalierung von Embeddings unterstützt.
Wenn auf einem GPU-beschleunigten Trooper.AI-Server bereitgestellt, kann Qdrant Millionen von Vektoren extrem schnell indizieren und durchsuchen – perfekt für RAG-Systeme, LLM-Speicher, Personalisierungs-Engines und Empfehlungssysteme.
Die folgende Anleitung zeigt Ihnen wie man Qdrant über Docker ausführt, wie es im Dashboard aussieht sowie wie man es korrekt mit Node.js abfragt.
Den Qdrant Docker Container ausführen
Sie können das offizielle problemlos ausführen qdrant/qdrant Docker-Container mit den unten gezeigten Einstellungen.
Diese Screenshots zeigen eine typische Konfiguration, die auf Trooper.AI GPU-Servern verwendet wird, einschließlich:
- Exponierter REST API Port
- Dashboard-Zugriff
- Datenpersistenz
- Optionale GPU-Beschleunigung (falls in Ihrer Umgebung aktiviert)
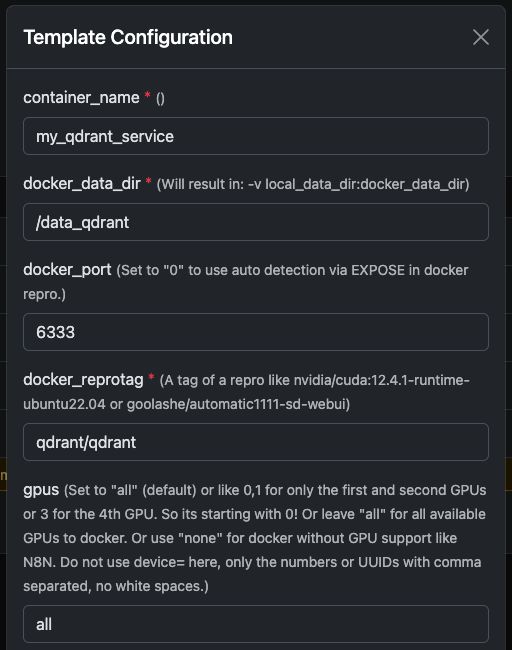
Qdrant-Dashboard und der REST-API stehen Ihnen nach dem Start sofort zur Verfügung.
Qdrant Dashboard Vorschau
Das Dashboard ermöglicht Ihnen die Überprüfung von Collections, Vektoren, Payloads und Indizes.
Eine typische Dashboard-Konfiguration sieht wie folgt aus:
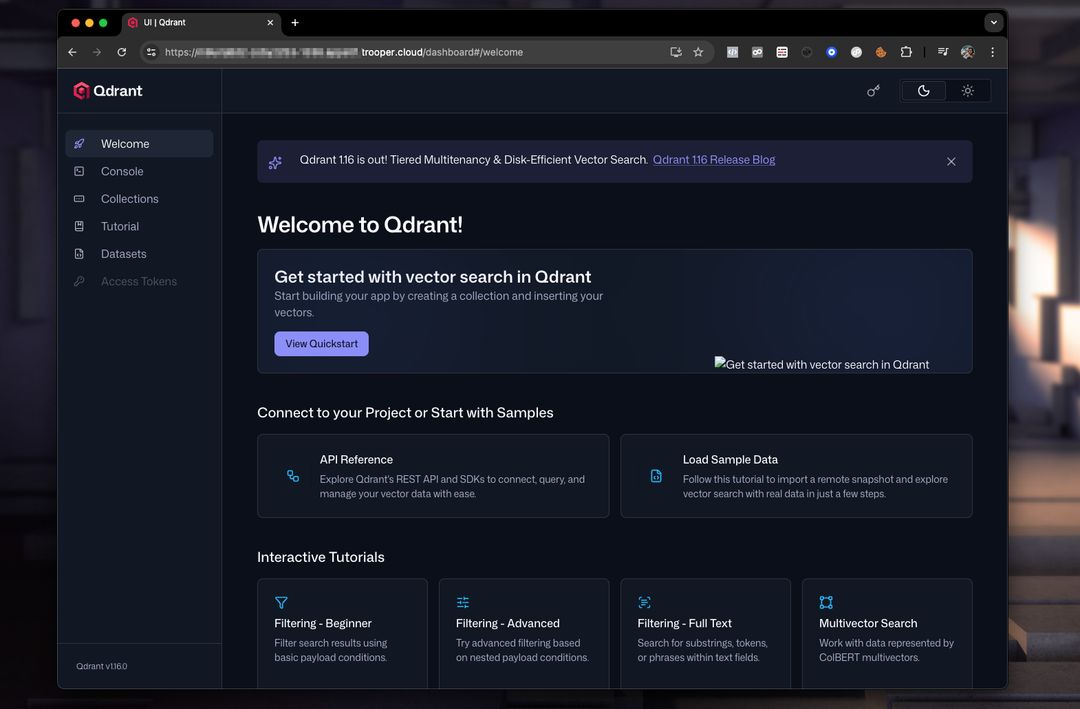
Von hier aus können Sie:
- Sammlungen erstellen
- Vektoren hinzufügen
- Beispielrecherchen ausführen
- Metadaten prüfen
- Leistung überwachen
Abfragen von Qdrant aus Node.js
Funktionsfähiges und korrigiertes Node.js-Beispiel zur Nutzung der Qdrant REST-API.
Wichtige Korrekturen des ursprünglichen Beispiels:
- Qdrant erfordert das Aufrufen eines Endpunkts wie:
/collections/<collection_name>/points/search Vektormuss ein(e) Array sein, nicht[a, b, c]- Modernes Node.js verfügt über eine native Funktionalität.
fetch, daher ist node-fetch nicht erforderlichnode-fetch
NODEJS BEISPIEL
// Qdrant Vector Search Example – fully compatible with Qdrant 1.x and 2.x
async function queryQdrant() {
// Replace "my_collection" with your actual collection name
const url = 'https://AUTOMATIC-SECURE-URL.trooper.ai/collections/my_collection/points/search';
const payload = {
vector: [0.1, 0.2, 0.3, 0.4], // Must be an array
limit: 5
};
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
});
if (!response.ok) {
throw new Error(`Qdrant request failed with status: ${response.status}`);
}
const data = await response.json();
console.log('Qdrant Response:', data);
return data;
} catch (error) {
console.error('Error querying Qdrant:', error);
return null;
}
}
queryQdrant();
Gültige Qdrant-Suchnutzlast
Qdrant erwartet einen JSON-Body wie diesen:
{
"vector": [0.1, 0.2, 0.3, 0.4],
"limit": 5
}
Wo:
- Vektor → Ihr Embedding
- limit → maximale Anzahl der zurückgegebenen Ergebnisse
Sie können bei Bedarf auch erweiterte Filter hinzufügen:
{
"vector": [...],
"limit": 5,
"filter": {
"must": [
{ "key": "category", "match": { "value": "news" } }
]
}
}
Hinweise für Trooper.AI-Nutzer
- Ersetzen
AUTOMATIC-SECURE-URL.trooper.aimit Ihrem zugewiesenen sicheren Endpunkt - Stellen Sie sicher, dass Ihre Collection existiert, bevor Sie eine Abfrage durchführen.
Beispiel: Ausführen von N8N mit Any Docker
In diesem Beispiel konfigurieren wir Any Docker mit Ihrer Konfiguration für n8n sowie persistenter Datenspeicherung, sodass Neustarts möglich sind – ohne Datenverlust. Diese Konfiguration enthält keine Webhooks. Falls Sie Webhooks benötigen, verwenden Sie bitte das vorgefertigte Template unter: n8n
Diese Anleitung dient nur zur Erklärung. Sie können jeden Docker-Container starten, den Sie möchten.
Konfigurationsabbildungen finden Sie unten:
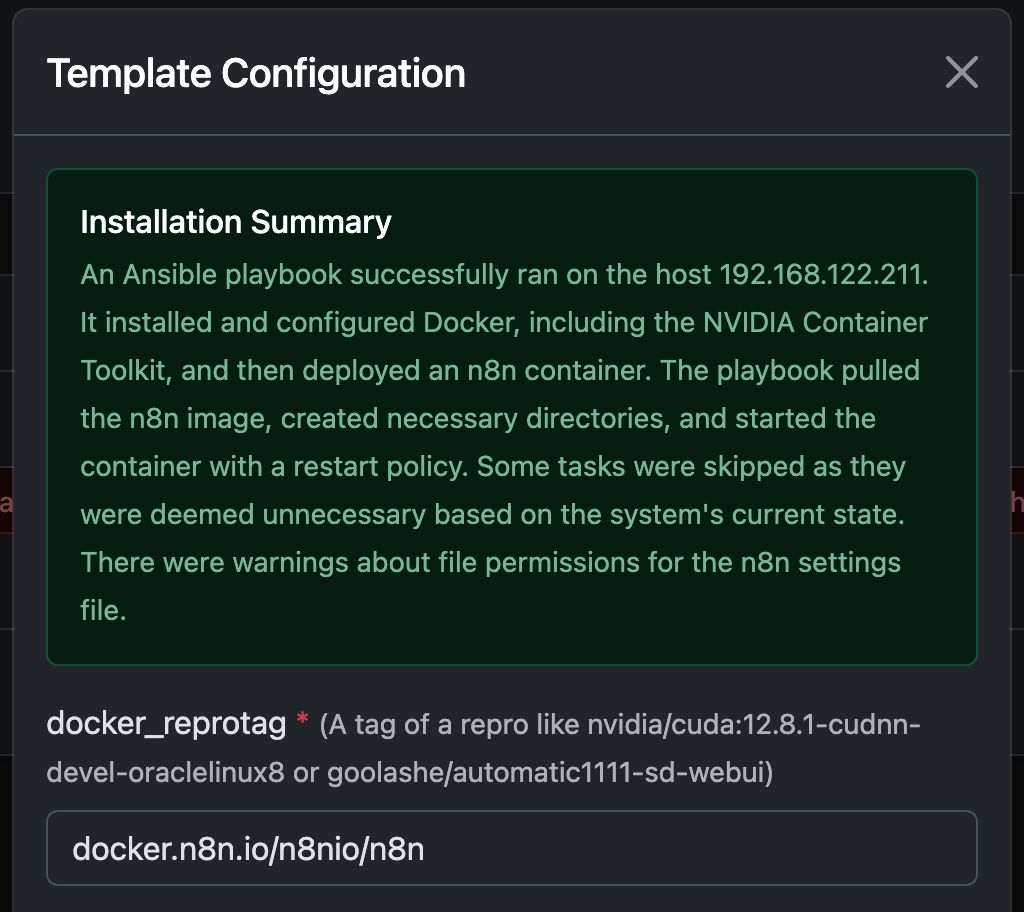
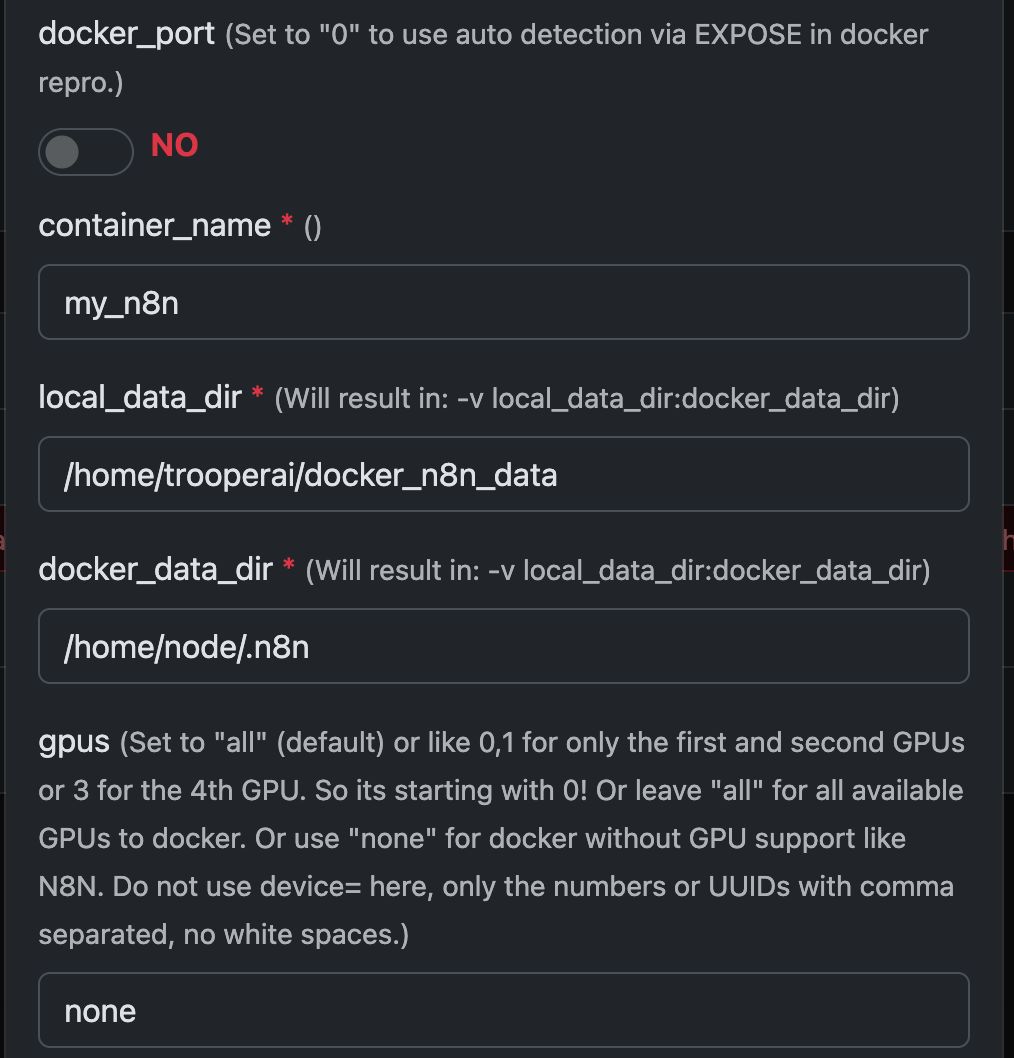
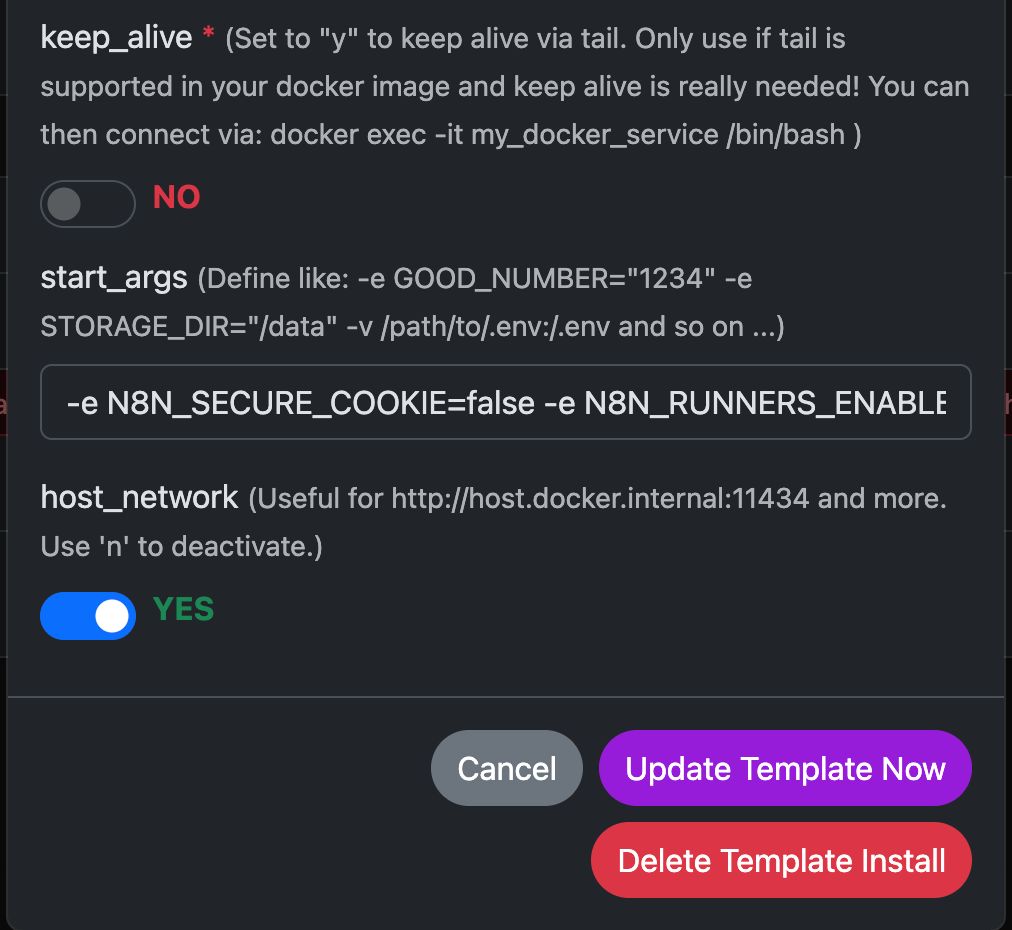
Der Docker-Befehl ‘Unter der Haube’
Diese Vorlage automatisiert die vollständige Einrichtung eines GPU-fähigen Docker-Containers, einschließlich der Installation aller erforderlichen Ubuntu-Pakete und Abhängigkeiten für die NVIDIA-GPU-Unterstützung. Dies vereinfacht den Prozess, insbesondere für Benutzer, die mit Docker-Bereitstellungen für Webserver vertraut sind, welche oft eine komplexere Konfiguration erfordern.
Das Folgende docker run Der Befehl wird automatisch vom Template generiert, um Ihren ausgewählten GPU-Container zu starten. Er enthält alle erforderlichen Einstellungen für optimale Leistung und Kompatibilität mit Ihrem Trooper.AI Server.
Dieser Befehl dient als illustratives Beispiel, um Entwicklern Einblick in die zugrunde liegenden Prozesse zu geben:
docker run -d \
--name ${CONTAINER_NAME} \
--restart always \
--gpus ${GPUS} \
--add-host=host.docker.internal:host-gateway \
-p ${PUBLIC_PORT}:${DOCKER_PORT} \
-v ${LOCAL_DATA_DIR}:/home/node/.n8n \
-e N8N_SECURE_COOKIE=false \
-e N8N_RUNNERS_ENABLED=true \
-e N8N_HOST=${N8N_HOST} \
-e WEBHOOK_URL=${WEBHOOK_URL} \
docker.n8n.io/n8nio/n8n \
tail -f /dev/null
Verwenden Sie diesen Befehl nicht manuell, wenn Sie kein Docker-Experte sind! Vertrauen Sie stattdessen der Vorlage.
Was ermöglicht N8N auf dem privaten GPU-Server?
n8n entfesselt das Potenzial, komplexe Workflows direkt auf Ihrem Trooper.AI-GPU-Server auszuführen. Das bedeutet, dass Sie Aufgaben wie Bild-/Videoverarbeitung, Datenanalyse, Interaktionen mit LLMs (Large Language Models) und mehr automatisieren können – und dabei die Leistung der GPU für beschleunigte Ergebnisse nutzen.
Konkret können Sie Workflows für Folgendes ausführen:
- Bild-/Videobearbeitung: Automatisieren von Größenanpassungen, Watermarkierung, Objekterkennung sowie weiteren visuellen Aufgaben.
- Datenverarbeitung: Daten aus verschiedenen Quellen extrahieren, transformieren und laden.
- LLM-Integration: Verbindung zu und Interaktion mit großen Sprachmodellen (Large Language Models) für Aufgaben wie Texterzeugung, Übersetzung und Sentimentanalyse.
- Web-Automatisierung: Automatisieren Sie Aufgaben über verschiedene Websites und APIs hinweg.
- Individuelle Workflows: Erstellen und bereitstellen Sie jeden automatisierten Prozess nach Ihren Bedürfnissen.
Beachten Sie, dass Sie KI-Tools wie ComfyUI und Ollama installieren müssen, um diese in Ihre N8N-Workflows auf dem Server zu integrieren. Sie benötigen außerdem ausreichend GPU-VRAM, um alle Modelle mit Strom zu versorgen. Weisen Sie die GPUs nicht dem Docker-Container zu, der N8N ausführt.
Was ist Docker im Zusammenhang mit einem GPU-Server?
Auf einem Trooper.AI GPU-Server ermöglicht Docker das Verpacken von Anwendungen mit ihren Abhängigkeiten in standardisierte Einheiten, sogenannte Container. Dies ist besonders leistungsstark für GPU-beschleunigte Workloads, da es Konsistenz über verschiedene Umgebungen hinweg gewährleistet und die Bereitstellung vereinfacht. Anstatt Abhängigkeiten direkt auf dem Host-Betriebssystem zu installieren, enthalten Docker-Container alles, was eine Anwendung zum Ausführen benötigt – einschließlich Bibliotheken, Systemtools, Laufzeitumgebung und Einstellungen.
Für GPU-Anwendungen ermöglicht Docker Ihnen die effiziente Nutzung der GPU-Ressourcen des Servers. Durch die Verwendung des NVIDIA Container Toolkits können Container auf die GPUs des Hosts zugreifen, was beschleunigtes Computing für Aufgaben wie Machine Learning, Deep Learning Inference und Datenanalyse ermöglicht. Diese Isolation verbessert auch die Sicherheit und das Ressourcenmanagement, sodass mehrere Anwendungen die GPU gemeinsam nutzen können, ohne sich gegenseitig zu beeinträchtigen. Das Deployment und die Skalierung von GPU-basierten Anwendungen werden mit Docker auf einem Trooper.AI Server deutlich einfacher.
Mehr Docker ausführen
Sie können problemlos mehrere Docker-Container ausführen und bei Fragen Unterstützung erhalten über: