Strojenie Ministral-3 na vLLM
Praktyczny przewodnik po odpowiedziach w postaci zwykłego tekstu i JSON
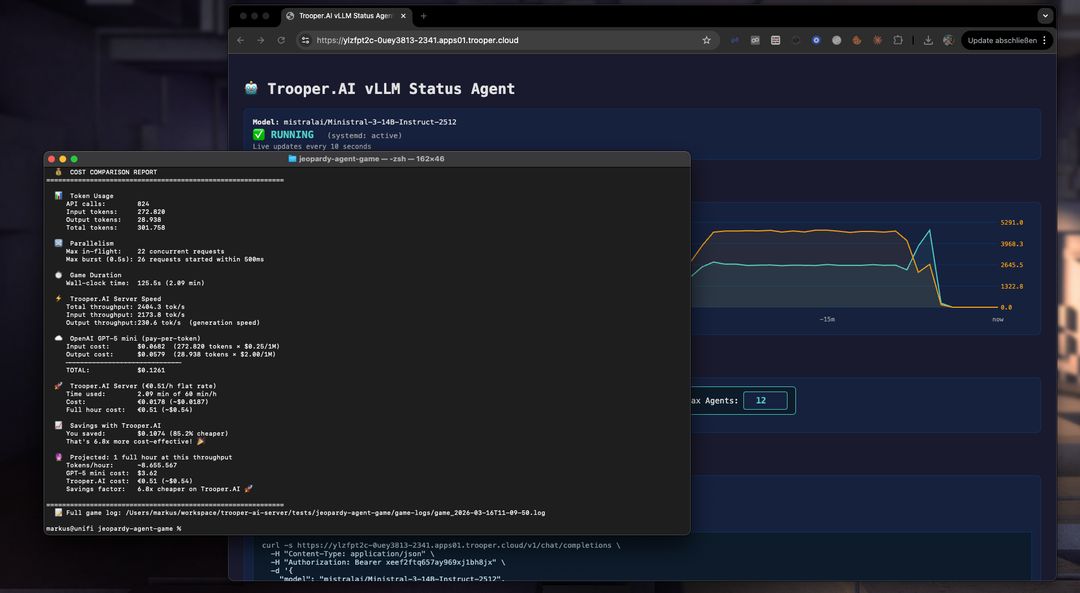
Wnioski z budowy symulacji gry w AI Jeopardy dla 12 graczy napędzanej przez Ministral-3-14B-Instruct-2512.
Praktyczny przewodnik po odpowiedziach w postaci zwykłego tekstu i JSON
Wnioski z budowy symulacji gry w AI Jeopardy dla 12 graczy napędzanej przez Ministral-3-14B-Instruct-2512.
Uruchamianie Ministral-3 na vLLM okazuje się zaskakująco potężne. Model jest szybki, kreatywny i zdolny do generowania wysokiej jakości odpowiedzi nawet przy dużym obciążeniu.
Ale gdy tylko przechodzisz od prostych wiadomości czatowych do strukturyzowanych wyjść, automatyzacji lub użycia programistycznego, sprawy szybko stają się skomplikowane.
Gry w stylu Jeopardy napędzane przez AI z 12 jednoczesnymi graczami i setkami wywołań modeli
Ten przewodnik podsumowuje praktyczne lekcje wyciągnięte z rozwiązywania tych problemów, wraz z konkretnymi wzorcami, które możesz wykorzystać w swoich projektach.
Nasz projekt porównawczy symuluje pełną grę Jeopardy, w której:
Jedna sesja gry może łatwo przekroczyć ponad 800 wywołania API.
To środowisko ujawniło przypadki brzegowe, które rzadko pojawiają się w prostych demonstracjach — czyniąc z niego doskonałe pole testowe dla zrozumienia, jak Ministral zachowuje się pod obciążeniem rzeczywistej produkcji.
Modele Ministral nie używają domyślnej konfiguracji tokenizera z HuggingFace.
Oznacza to, że polecenie uruchomieniowe musi jawnie włączyć format tokenizera Mistrala.
vllm serve mistralai/Ministral-3-14B-Instruct-2512 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral
Jeśli Twoja aplikacja opiera się na wywoływaniu funkcji, dodaj flagi narzędzi:
--enable-auto-tool-choice
--tool-call-parser mistral
Model Ministral nie obsługuje parametru chat_template_kwargs
Jeśli wyślesz żądanie w następujący sposób:
{
"chat_template_kwargs": {
"enable_thinking": false
}
}
vLLM zwraca:
HTTP 400: chat_template is not supported for Mistral tokenizers
Oznacza to, że funkcje takie jak jawny przełącznik trybu "myślenia" (używane w modelach takich jak Qwen lub DeepSeek) są po prostu niedostępne
Na szczęście, rzadko jest to potrzebne, ponieważ Ministral domyślnie generuje zwięzłe odpowiedzi.
Oficjalna dokumentacja vLLM konsekwentnie używa następującej wartości dla Ministrala-3:
temperature = 0.15
Na pierwszy rzut oka wartość ta wydaje się niezwykle niska. Okazuje się jednak, że jest kluczowa dla zadań wymagających struktury
Korzystając z domyślnych ustawień w stylu OpenAI:
temperature: 0.7
zbyt kreatywne w strukturze
Proste zapytanie takie jak:
{ "expertise": "2-3 topics they know best" }
może zwrócić coś takiego:
{
"expertise": [
{
"category": "Gourmet Pizza Alchemy",
"detail": "Can transform random ingredients into Michelin-star pizza"
},
{
"category": "Sumo Wrestling Physics",
"detail": "Understands body mechanics and center-of-gravity combat"
}
]
}
nie odpowiada to, czego schemat wymaga
W efekcie:
max_tokens przekroczono limity0.15 działa lepiejstrukturalnie dyscyplinowane
temperature: 0.15
Korzyści:
Nawet generowanie kreatywnych tekstów pozostaje silne — model po prostu przestaje improwizować ze strukturą.
Rekomendacja:
Użyj temperature: 0.15 jako domyślnej wartości dla Ministral-3.
Generowanie maszynowo czytelnego JSONu z modeli językowych jest trudniejsze niż się wydaje.
Model Ministral ma tendencję do interpretowania pól schematu semantycznie zamiast strukturalnie, co prowadzi do głęboko zagnieżdżonej odpowiedzi.
Na przykład zapytanie:
Return JSON with these fields.
często generuje rozbudowane struktury.
Przykładowe zapytanie:
{ "expertise": "2-3 topics they know best" }
Typowa odpowiedź:
{
"expertise": [
{
"category": "Ancient Roman Engineering",
"detail": "Knows aqueduct systems in surprising detail"
},
{
"category": "Pizza Dough Chemistry",
"detail": "Obsessed with yeast fermentation dynamics"
}
]
}
To zużywa trzykrotnie więcej tokenów niż oczekiwano
Dwie instrukcje
Respond with ONLY valid JSON.
No markdown, no explanation, no text before or after the JSON.
Keep values as short plain strings — never use nested objects or arrays.
Bezpośrednio obok definicji schematu:
Every value MUST be a short plain string — NO arrays, NO nested objects.
W połączeniu z temperaturą 0.15, daje to spójny i płaski JSON.
Dłuższe wartości niż inne modele, nawet przy ograniczeniach.
Przykładowa obserwacja z naszego benchmarku:
| Model | Liczba tokenów wymagana |
|---|---|
| GPT-4o | ~512 |
| Qwen | ~512 |
| Ministral-3 | ~1024 |
Bezpieczna zasada:
Przewidzij budżet na 1,5–2 razy więcej tokenów dla wyjść w formacie JSON.
Nawet przy idealnych promptach, modele czasem generują nieprawidłowy JSON.
Dobrą strategią jest dodanie warstw bezpiecznego parsowania.
function extractJSON(raw, shape) {
var text = raw.replace(/^```(?:json)?\s*/i, '').replace(/\s*```$/i, '').trim();
if (shape === 'array') {
var m = text.match(/\[[\s\S]*\]/);
if (m) text = m[0];
} else {
var m = text.match(/\{[\s\S]*\}/);
if (m) text = m[0];
}
return text;
}
Śledź otwarte nawiasy i automatycznie je zamykaj:
var stack = [];
var inStr = false, esc = false;
for (var i = 0; i < text.length; i++) {
var ch = text[i];
if (esc) { esc = false; continue; }
if (ch === '\\') { esc = true; continue; }
if (ch === '"') { inStr = !inStr; continue; }
if (inStr) continue;
if (ch === '{') stack.push('}');
else if (ch === '[') stack.push(']');
else if (ch === '}' || ch === ']') stack.pop();
}
text = text.replace(/,\s*$/, '');
while (stack.length > 0)
text += stack.pop();
Jeśli model nadal zwraca zagnieżdżone struktury:
if (Array.isArray(value)) {
flat = value.map(function(item) {
if (typeof item === 'string') return item;
if (typeof item === 'object') return Object.values(item).join(' — ');
return String(item);
}).join(', ');
}
Prosta pętla ponownych prób dramatycznie zwiększa niezawodność.
Ministral zachowuje się spójnie przy niskiej temperaturze, powtórzenia zazwyczaj kończą się powodzeniem.
Zalecane:
2–3 retry attempts
Ministral uwielbia formatowanie.
Nawet jeśli poprosisz o zwykły tekst, to ma tendencję do generowania:
Wbudowany systemowy komunikat zachęcający do bogatego formatowania w stylu Markdown
Wiele potoków opiera się na prostych sprawdzeniach ciągów znaków.
Przykład:
verdict.toUpperCase().startsWith('CORRECT')
Jeśli model zwróci:
**CORRECT**
Sprawdzenie się nie powiodło.
Najbezpieczniejszym podejściem jest unormowanie wszystkich wyników przed ich przetwarzaniem.
function stripMarkdown(text) {
if (!text) return text;
var s = text.replace(/\*\*([^*]+)\*\*/g, '$1');
s = s.replace(/__([^_]+)__/g, '$1');
s = s.replace(/\*([^*]+)\*/g, '$1');
s = s.replace(/^#{1,6}\s+/gm, '');
s = s.replace(/`([^`]+)`/g, '$1');
s = s.replace(/^```[a-z]*\s*$/gm, '');
return s.trim();
}
Zastosuj to do każdej odpowiedzi modelu, nie tylko dla Ministral.
Pozwala to uniknąć rozgałęzień specyficznych dla modelu i utrzymuje spójność potoków.
Jeśli Twój system obsługuje wiele rodzin modeli (Mistral, Qwen, DeepSeek, Llama itd.), najbardziej utrzymywalnym podejściem jest scentralizowanie zachowania modeli w jednym miejscu.
Przykład:
function buildModelProfile(modelName) {
var lower = modelName.toLowerCase();
var isMistral = lower.includes('mistral') || lower.includes('ministral');
return {
family: isMistral ? 'Mistral' : 'Generic',
jsonSystemInstruction: isMistral
? 'Respond with ONLY valid JSON. No markdown. Keep values as short plain strings.'
: 'You output only valid JSON. No markdown fences, no explanation.',
jsonSchemaHint: isMistral
? ' Every value MUST be a short plain string — NO arrays, NO nested objects.'
: '',
jsonTemperature: isMistral ? 0.15 : 0.7,
defaultTemperature: isMistral ? 0.15 : 0.7,
plainTextInstruction: ' Do not use markdown formatting.'
};
}
To pozwala na zachowanie reszty Twojego systemu niezależnego od modelu.
Dodawanie nowego modelu później staje się trywialne.
| Ustawienie | Zalecana wartość | Powód |
|---|---|---|
| tokenizer_mode | mistral | Wymagane dla poprawnego tokenizera |
| config_format | mistral | Wymagane |
| load_format | mistral | Wymagane |
| chat_template_kwargs | Nie wysyłaj | Nieobsługiwane |
| temperatura | 0.15 | Zapobiega halucynacjom strukturalnym |
| Instrukcja JSON | Jawne wartości płaskie | Unikaj zagnieżdżonych obiektów |
| max_tokens | 1,5–2× typowy | Model jest rozwlekły |
| Usuwanie formatowania Markdown | Zawsze | Zapobiegaj błędom formatowania |
| Ponowne próby JSON | 2–3 próby | Niezawodna regeneracja |
Ministral-3 działa wyjątkowo dobrze po odpowiednim dostrojeniu.
Kiedy już:
model staje się wyjątkowo przewidywalny i gotowy do wdrożenia
W naszym teście porównawczym Jeopardy, ta konfiguracja obsługiwała:
Wszystko uruchomione lokalnie na infrastrukturze GPU Trooper.AI.
Wypróbuj pełny szablon wdrożenia vLLM tutaj: Serwer kompatybilny z OpenAI dla vLLM
Wypożycz swój własny serwer GPU już dziś i zacznij tworzyć niesamowite aplikacje AI! Serwery GPU Trooper.AI są zbudowane z wyselekcjonowanego, wysokiej klasy sprzętu z ostatnich lat, zaprojektowane, aby zapewnić Ci najlepszą wydajność, bezpieczeństwo i niezawodność dla wszystkich Twoich potrzeb związanych ze sztuczną inteligencją.
Lokalizacja w UE · Wysoka prywatność · Świetna wydajność · Najlepsze wsparcie