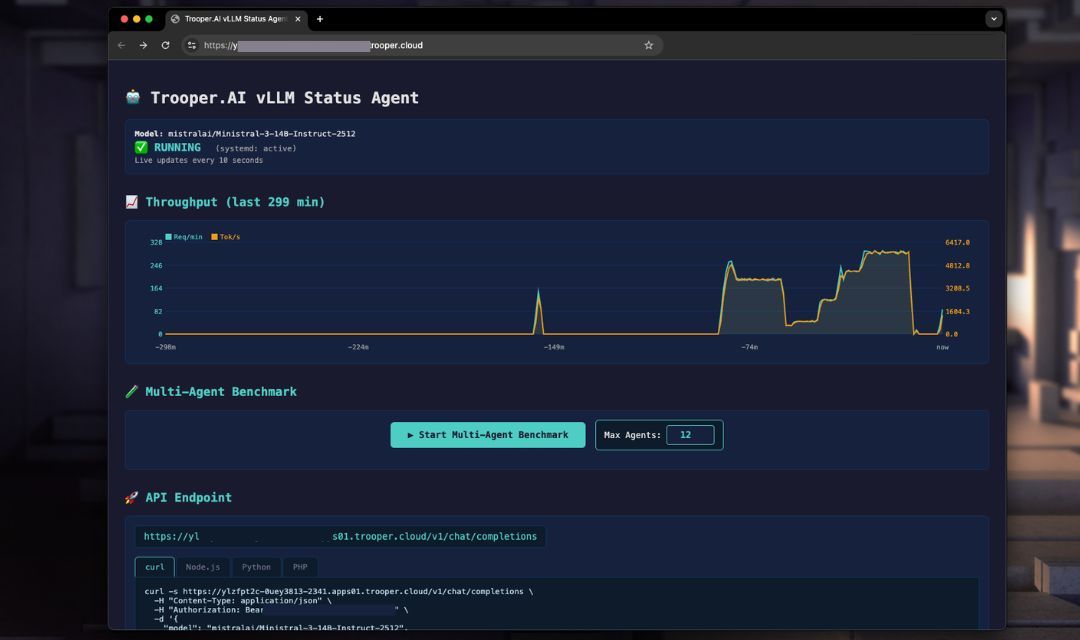
Serwer kompatybilny z vLLM OpenAI
Trooper.AI zapewnia w pełni automatyczny szablon wdrożenia vLLM, który instaluje, konfiguruje i uruchamia serwer wnioskowania kompatybilny z OpenAI na Twoim serwerze GPU przy użyciu systemd.
Cel:
- Maksymalna przepustowość
- Automatyczne dostrajanie architektury GPU
- API kompatybilne z OpenAI
- Bezpieczne ustawienia domyślne
- Wymaga zerowej manualnej konfiguracji GPU
Szablon automatycznie:
- Wykrywa architekturę GPU i VRAM
- Wybiera optymalną precyzję (FP16 / BF16 / FP8)
- Dostosowuje przetwarzanie wsadowe i współbieżność
- Instaluje vLLM w wirtualnym środowisku
- Tworzy trwałą usługę systemd
- Udostępnia punkty końcowe kompatybilne z OpenAI
- Wykorzystaj wyniki testów wydajności, aby dostosować parametry
Kontrolujesz tylko niewielki zestaw parametrów publicznych.
Zrozumienie liczby GPU: vLLM działa z wieloma kartami GPU, ale wymaga, aby liczba tych kart była dzielnikiem liczby głow uwagi w modelu. Na przykład model taki jak Gemma, posiadający 32 głowy uwagi, może wykorzystywać 1, 2, 4 lub 8 GPU – ale nie 3.
Ważne informacje bezpieczeństwa dotyczące zrzutów ekranu: Serwery pokazane na zdjęciach służą wyłącznie celom demonstracyjnym i są chronione przez sieciowy firewall firmy Trooper.AI, który jest włączony w standardzie we wszystkich zamówieniach serwerów GPU. Szczegółowe informacje znajdziesz pod adresem 🛡️ Trooper.AI dostosowywalny sieciowy firewall
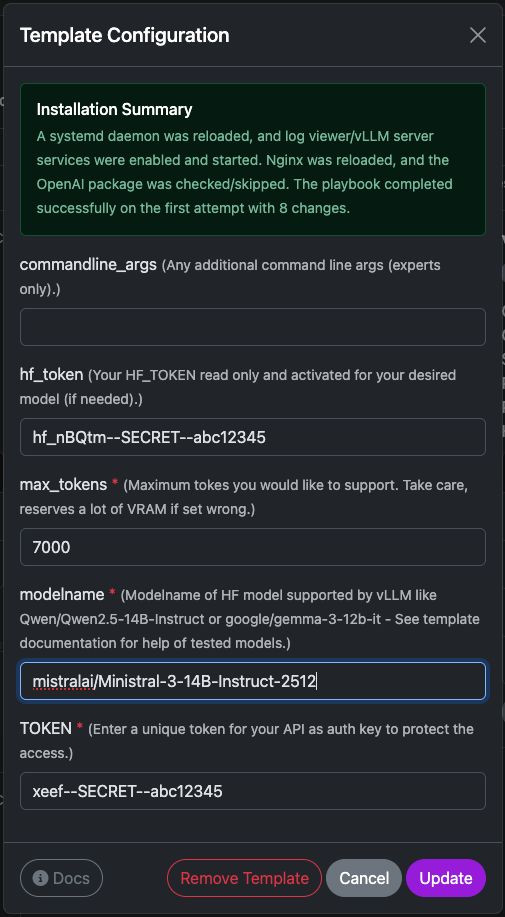
Ustawienia szablonu vLLM
Ten szablon wdraża gotowy do użycia serwer inferencji vLLM na Twojej instancji Trooper.AI. Instaluje wymagane środowisko wykonawcze, konfiguruje punkt końcowy API i przygotowuje model do obsługi żądań kompatybilnych z OpenAI.
Poniżej znajduje się krótkie wyjaśnienie każdej opcji konfiguracyjnej.
commandline_args
Opcjonalne zaawansowane argumenty przekazywane bezpośrednio do polecenia uruchomieniowego serwera vLLM
Użyj tego, jeśli chcesz włączyć dodatkowe funkcje, takie jak:
- równoległość tensorów
- kwantyzacja
- wywoływanie narzędzi
- niestandardowe ustawienia tokenizera
- dekodowanie spekulacyjne
Przykład:
--tensor-parallel-size 2
Pozostaw puste, chyba że dokładnie wiesz, które flagi chcesz użyć.
hf_token
Token dostępu do Hugging Face
Jest to wymagane, jeśli model:
- ograniczony dostępem
- wymaga uwierzytelnienia
- lub jest pobierany z prywatnego repozytorium
W przypadku modeli publicznych to pole można pozostawić puste.
Możesz wygenerować token tutaj:
https://huggingface.co/settings/tokens
Token jest używany tylko podczas pobierania modelu.
max_tokens
maksymalne okno kontekstowe, jakie serwer powinien obsługiwać.
To bezpośrednio wpływa na zużycie pamięci VRAM.
Typowe wartości:
| Kontekst | Zalecane |
|---|---|
| małe modele | 4096 |
| modele średnie | 8192 |
| modele z długim kontekstem | 16384+ |
Wyższe wartości znacznie zwiększają zużycie pamięci. Jeśli na serwerze zabraknie VRAM, zmniejsz tę wartość.
nazwa_modelu
Identyfikator modelu z Hugging Face, który powinien załadować vLLM.
Przykład:
mistralai/Ministral-3-14B-Instruct-2512
Inne kompatybilne przykłady:
Qwen/Qwen2.5-14B-Instruct
google/gemma-3-12b-it
meta-llama/Meta-Llama-3-8B-Instruct
... and many more
Upewnij się, że model jest obsługiwany przez vLLM i mieści się w pamięci Twojej karty GPU.
TOKEN
To jest Twój klucz autoryzacji API.
Wszystkie żądania do serwera vLLM muszą zawierać ten token w nagłówku:
Authorization: Bearer YOUR_TOKEN
To chroni Twój serwer przed nieautoryzowanym dostępem.
Przykładowe zapytanie:
curl https://your-server/v1/chat/completions \
-H "Authorization: Bearer YOUR_TOKEN"
Użyj silnego losowego ciągu znaków.
Rozmiar modelu i wymagania dotyczące GPU
Możesz wykorzystać szeroki zakres dużych modeli językowych z HuggingFace w ramach vLLM. Upewnij się, że dostępna jest wystarczająca ilość VRAM, ponieważ wydajność zależy od posiadania wystarczającej ilości wolnej pamięci GPU VRAM, aby pomieścić rozmiar modelu i kontekstu, pomnożony przez liczbę współbieżnych użytkowników.
Trooper.AI automatycznie wybiera optymalną precyzję dla danej architektury GPU.
Obliczenia zużycia VRAM: Wagi modelu + ~25% bufora KV-Cache.
Pamięć VRAM może być dzielona między wiele GPU za pomocą tensorowego równoległego przetwarzania (--tensor-parallel-size N).
| Model | Parametry | Precyzja | Min. Całkowita pamięć VRAM | Konfiguracja GPU | GPU |
|---|---|---|---|---|---|
| Qwen/Qwen3-4B | 4B | BF16 | ~8 GB | 1× V100 16GB / RTX 4070 Ti Super | 1 |
| Qwen/Qwen3-8B | 8B | BF16 | ~20 GB | 1× RTX 3090 / RTX 4090 (24 GB) | 1 |
| mistralai/Ministral-3-14B-Instruct-2512 | 14B | FP8 | ~29 GB | 1× RTX 4080 Pro 32GB lub 1× A100 40GB | 1 |
| Qwen/Qwen3-32B | 32B | FP8 | ~40 GB | 1× A100 40GB lub 2× RTX 4090 (2×24 GB) | 1–2 |
| meta-llama/Llama-3.1-8B-Instruct | 8B | FP8 | ~20 GB | 1× RTX 3090 / RTX 4090 (24 GB) | 1 |
| meta-llama/Llama-3.1-70B-Instruct | 70B | FP8 | ~90 GB | 1× RTX Pro 6000 Blackwell (96 GB) lub 2× A100 (2×40 GB) | 1–2 |
Uwaga: FP8 jest używane na architekturach Ada/Hopper (RTX 40-serii, A100, H100) w celu osiągnięcia maksymalnego przepływu danych.
Trooper.AI automatycznie dobiera optymalną precyzję dla Twojego GPU.
W konfiguracjach multi-GPU stosowany jest Tensor Parallelism — pamięć VRAM skaluje się liniowo pomiędzy GPU.
Parametry publiczne
Te parametry można ustawić za pomocą zmiennych środowiskowych przed uruchomieniem instalatora.
| Zmienna | Opis |
|---|---|
TOKEN |
Klucz API do uwierzytelniania |
modelname |
Ścieżka do modelu HuggingFace |
hf_token |
Token HuggingFace (dla modeli z ograniczonym dostępem) |
commandline_args |
Opcjonalne dodatkowe argumenty CLI vLLM |
Automatyczne testy porównawcze do dostrajania parametrów
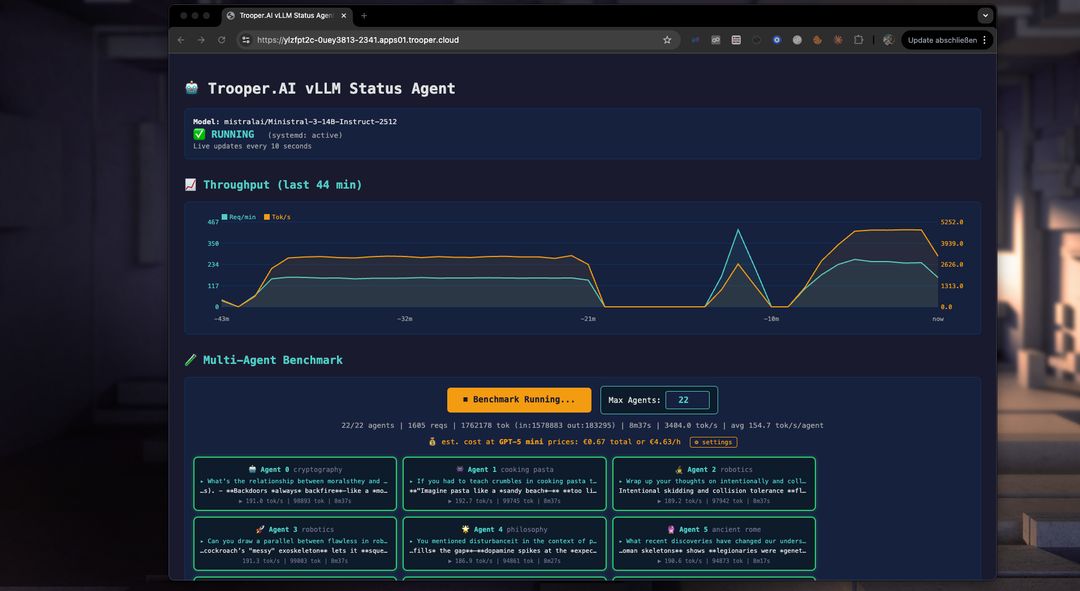
Nasza konfiguracja zawiera test wydajności, który pomoże zoptymalizować serwer GPU do pracy z wieloma agentami. Użyj go, aby testować i porównywać modele, typy GPU oraz parametry w celu maksymalizacji przepustowości i liczby współbieżnych użytkowników.
Jak działa ten benchmark?
Test porównawczy uruchamia wielu agentów jednocześnie, z których każdy wchodzi w interakcję z punktem końcowym serwera vLLM na inny temat. Zapobiega to buforowaniu i testuje wydajność w realnych warunkach. Możesz zobaczyć przepustowość każdego agenta, całkowitą przepustowość oraz porównać koszty usług tokenowych, takich jak GPT-5 mini. Często serwer vLLM od Trooper.AI jest 2-4 razy tańszy niż duże usługi wnioskowania oparte na tokenach, jednocześnie zachowując prywatność Twojej pracy z LLM!
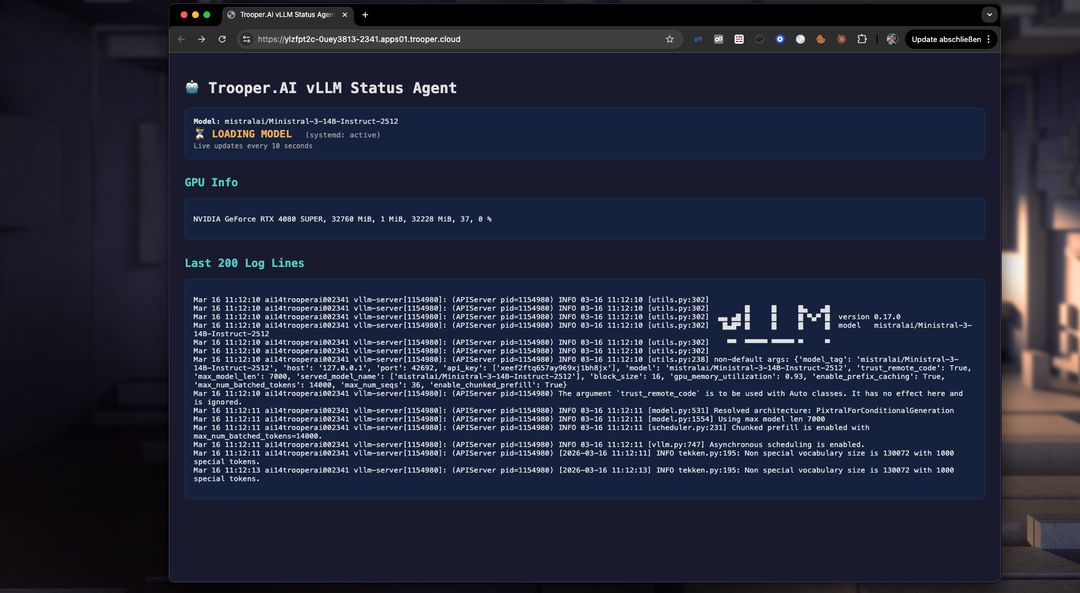
Co robi szablon
-
Wykrywa architekturę GPU (Volta, Ampere, Ada, Hopper, Blackwell)
-
Wykrywa rozmiar VRAM
-
Automatycznie wybiera optymalną precyzję:
- FP8 > BF16 > FP16
-
Używa pamięci podręcznej KV FP16 dla stabilności
-
Strojenie:
- maksymalna liczba współbieżnych sekwencji
- rozmiar wsadu tokenów
- wykorzystanie pamięci
-
Instaluje vLLM z CUDA
Tworzy usługę systemd:
Kodvllm-server.service-
Uruchamia trwały serwer API kompatybilny z OpenAI na bezpiecznym połączeniu HTTPS.
Nie jest wymagana ręczna konfiguracja.
Punkty końcowe API
Adres URL bazowy:
http://YOUR_SERVER:PORT/v1
Punkty końcowe:
/v1/models/v1/completions/v1/chat/completions
Nagłówek uwierzytelniania:
Authorization: Bearer YOUR_TOKEN_FROM_CONFIG
Przykład klienta Python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1"
)
resp = client.chat.completions.create(
model="Qwen/Qwen3-14B",
messages=[
{"role": "user", "content": "Hello, what is vLLM?"}
],
max_tokens=200
)
print(resp.choices[0].message.content)
Przykład klienta Node.js
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "YOUR_API_KEY",
baseURL: "https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1"
});
const completion = await client.chat.completions.create({
model: "Qwen/Qwen3-14B",
messages: [
{ role: "user", content: "Hello from Node.js" }
],
max_tokens: 200
});
console.log(completion.choices[0].message.content);
Przykład klienta PHP
<?php
$ch = curl_init("https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1/chat/completions");
$data = [
"model" => "Qwen/Qwen3-14B",
"messages" => [
["role" => "user", "content" => "Hello from PHP"]
],
"max_tokens" => 200
];
curl_setopt_array($ch, [
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_HTTPHEADER => [
"Authorization: Bearer YOUR_API_KEY",
"Content-Type: application/json"
],
CURLOPT_POSTFIELDS => json_encode($data)
]);
$response = curl_exec($ch);
curl_close($ch);
echo $response;
Przykład strumieniowania
Strumieniowanie Python
resp = client.chat.completions.create(
model="Qwen/Qwen3-14B",
messages=[{"role":"user","content":"Explain transformers"}],
stream=True
)
for chunk in resp:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Strumieniowanie Node.js
const stream = await client.chat.completions.create({
model: "Qwen/Qwen3-14B",
messages: [{ role: "user", content: "Explain transformers" }],
stream: true
});
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0].delta?.content || "");
}
Przykłady użycia
Serwery Trooper.AI vLLM są zaprojektowane do:
- Zaplecze AI SaaS
- Chatboty
- Asystenci kodowania
- systemy RAG
- Serwery inferencji dla wielu użytkowników
- Wydajne przetwarzanie wsadowe
- Środowiska wynajmu GPU
Filozofia wydajności
Trooper.AI wykorzystuje:
- Automatyczne dostrajanie architektury
- Automatyczny wybór precyzji
- Partiami uwzględniającymi VRAM
- Stabilna konfiguracja pamięci podręcznej KV
To pozwala uniknąć:
- Nieprawidłowa konfiguracja GPU
- Awaria precyzji
- Fragmentacja VRAM
- Nestabilność kontekstu
Porównanie kosztów: Ministral-3 na Trooper.AI vs GPT-5 mini
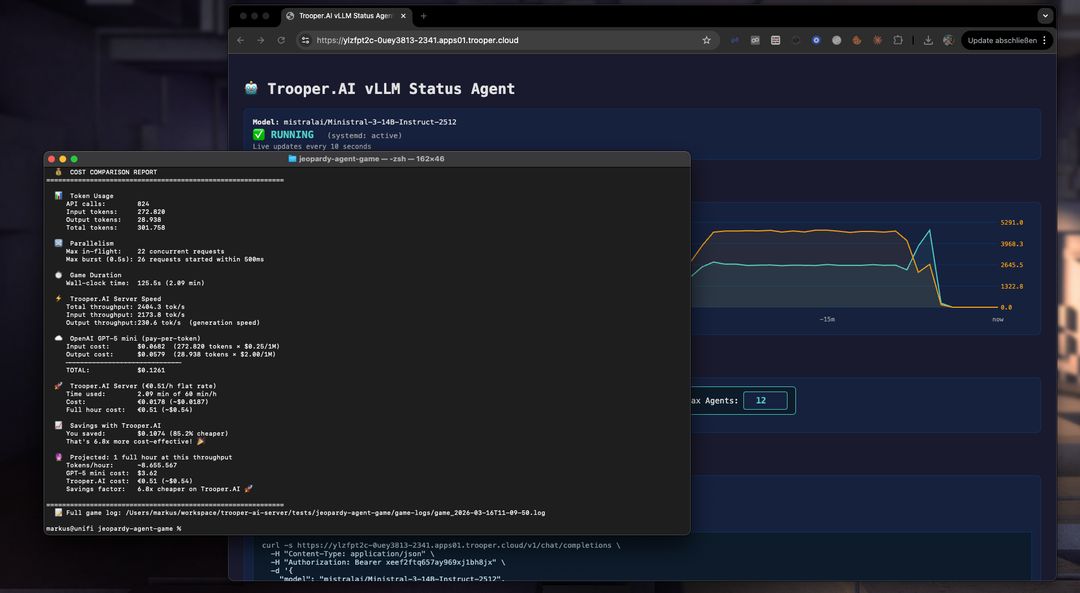
Aby dać ogólne pojęcie o ekonomice samodzielnego hostingu, poniższe porównanie szacuje koszt uruchomienia Ministral-3-14B-Instruct-2512 na serwerze GPU Trooper.AI w porównaniu z użyciem API GPT-5 mini dla tego samego obciążenia.
Szacunek opiera się na rzeczywistym przebiegu testów opisanym w tym artykule i ekstrapolowany na jedną godzinę ciągłej przepustowości wnioskowania.
Godzinowy koszt przy zmierzonym przepustowości
| Platforma | Koszt godzinowy |
|---|---|
| GPT-5 mini API | ~$3.12 |
| Ministral-3-14B na serwerze GPU Trooper.AI | €0.51 (~$0.54) |
Jak to zostało obliczone
Ta ocena opiera się na realnym teście wydajności przeprowadzonym w tym artykule przy użyciu modelu Ministral-3-14B-Instruct-2512 na serwerze GPU firmy Trooper.AI
| Wskaźnik | Wartość |
|---|---|
| Przetworzone tokeny | 307,028 |
| Czas działania | 153 sekundy |
| Przepustowość | ~2006 tokenów/sek. |
| Przewidywana liczba tokenów na godzinę | ~7,22M tokenów |
Mieszanka tokenów w teście porównawczym:
| Typ tokenu | Tokeny |
|---|---|
| Tokeny wejściowe | 275,186 |
| Tokeny wyjściowe | 31,842 |
Skalowanie tego stosunku do ~7,22 mln tokenów/godzinę oraz zastosowanie cenowania GPT-5 mini:
- 0,25 USD / 1M tokenów wejściowych
- 2,00 USD / 1M tokenów wyjściowych
wynosi szacunkowo ok. 3,12 USD na godzinę przy takim samym obciążeniu.
Serwer Ministral-3 na platformie Trooper.AI działa z stałą stawką €0.51/godz. (~$0.54), niezależnie od objętości tokenów, co umożliwia przetwarzanie milionów tokenów na godzinę przy przewidywalnych kosztach
Projekcja długotrwałego obciążenia
Na podstawie obserwowanej przepustowości możemy oszacować koszt uruchomienia systemu na pełną godzinę.
| Wskaźnik | Wartość |
|---|---|
| Tokenów na godzinę | ~7,221,543 |
| Koszt GPT-5 mini | $3.12 |
| Koszt serwera Trooper.AI | €0.51 (~$0.54) |
Oszczędności godzinowe
Uruchomienie tego samego obciążenia przez godzinę nadal byłoby:
ok. 5,8 razy tańsze na Trooper.AI
Kiedy samodzielny hosting staje się znacznie tańszy
Samodzielne hostowanie LLM jest bardziej opłacalne, gdy:
- obciążenia zawierają wiele małych żądań
- równoległe wnioskowanie jest wymagane
- miliony tokenów na godzinę
- ciągłe
Typowe przykłady obejmują:
- Symulacje gier AI
- systemy agentów
- potoki automatyzacji
- aplikacje czatowe z wieloma użytkownikami
Podsumowanie
W tym teście porównawczym:
| Wskaźnik | Wynik |
|---|---|
| Model | Ministral-3-14B |
| Koszt serwera | €0.51/hour |
| Przetworzone tokeny | 307k |
| Czas działania | 153 sekundy |
| Redukcja kosztów | 82.8% |
| Przewaga kosztowa | 5,8 razy tańsze niż GPT-5 mini |
Dla obciążeń o wysokim natężeniu przepływu danych, uruchamianie modeli takich jak Ministral-3 na serwerach GPU firmy Trooper.AI może dramatycznie obniżyć koszty wnioskowania (inference), jednocześnie eliminując limity częstotliwości API.
Dlaczego potrzebujesz szablonu vLLM
Szablon vLLM Trooper.AI zapewnia:
- API kompatybilne z OpenAI
- Automatyczna optymalizacja GPU
- Bezpieczne ustawienia domyślne
- Minimalna konfiguracja
- Maksymalna przepustowość
Wybranie modelu i klucza API to wszystko, co musisz zrobić.
Wszystko inne jest automatycznie zoptymalizowane.
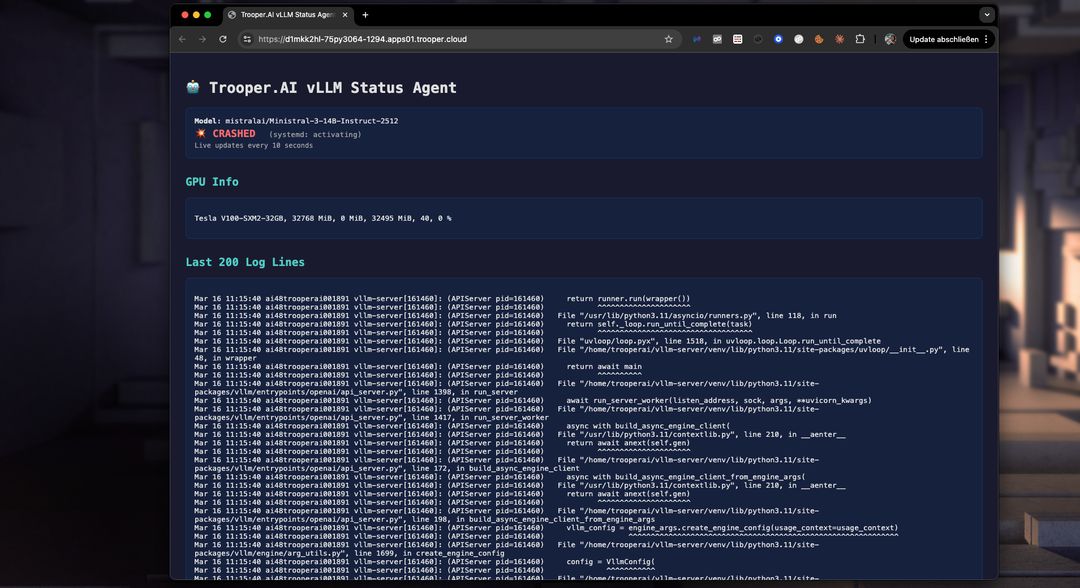
Rozwiązywanie problemów
Za pomocą panelu sterowania możesz łatwo wykryć problemy podczas uruchamiania i je naprawić. Za mało VRAM? Przejdź na wyższy Blib w kilka minut za pomocą panelu sterowania. Możesz także naprawić zużycie VRAM, zmniejszając rozmiar okna tokenów. Łatwo sprawdzaj logi w czasie rzeczywistym za pomocą panelu sterowania:
Ministral 3
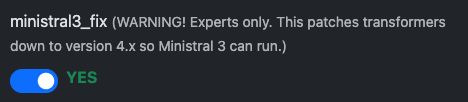
Aby używać Ministrala 3, zazwyczaj potrzeba wersji Transformers 4.x, co można łatwo wymusić przy pomocy opcji "Ministral 3 Fix" w ustawieniach szablonu. Należy jednak pamiętać, że vLLM to narzędzie dla specjalistów – konieczna jest znajomość optymalizacji i rozwiązywania problemów, choć staramy się wspierać w miarę możliwości.
Włącz najpierw opcję Ministral 3 Fix:
Drugie, użyj tych parametrów, aby uzyskać jak najwięcej funkcji z modelu:
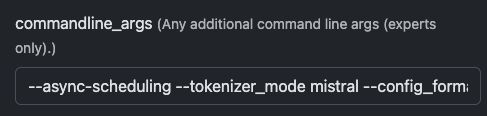
--async-scheduling --tokenizer_mode mistral --config_format mistral --load_format mistral --enable-auto-tool-choice --tool-call-parser mistral --limit-mm-per-prompt='{"image":{"count":4,"width":768,"height":768}}'
To uruchomi Ministral 3 na Twoim serwerze – jeśli pozostałe parametry dopasowane są do wielkości Twojej pamięci wideo (VRAM).
Nemotron 3 Nano z budżetem tokenów
Dla NVIDIA Nemotron 3 Nano wymagana jest co najmniej wersja vLLM 0.18.1 (wersja nocna z dnia 2025-03-30). Możesz skonfigurować parsowanie i limit tokenów, aby używać thinking_token_budget. Dowiedz się więcej tutaj: https://docs.vllm.ai/en/latest/features/reasoning_outputs/#online-serving.
Uwaga: może to obniżyć przepustowość o około -30%!
Zmodyfikuj argumenty wiersza polecenia na coś takiego:
--async-scheduling
--reasoning-parser-plugin /home/trooperai/vllm-server/nano_v3_reasoning_parser.py
--reasoning-parser nano_v3
--reasoning-config '{"think_start_str": "<think>", "think_end_str": " - I have to give the solution based on the thinking directly now:</think>"}'
Pobierz parsera z:
wget -O - https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16/resolve/main/nano_v3_reasoning_parser.py
Alternatywnie możesz włączyć opcję nemotron_3_parser (ustawić na ON). To zrobi to za Ciebie. Pamiętaj również o aktywacji wersji rozwojowej (nightly)!
Tak uzyskujesz większą kontrolę nad funkcją rozumowania modelu Nemotron 3 Nano.
Wsparcie
W celu zaawansowanej konfiguracji, multi-GPU lub niestandardowych ustawień, skontaktuj się z pomocą techniczną Trooper.AI.