Finjustering af Ministral-3 på vLLM
En Praktisk Guide til Almindelig Tekst og JSON-Svar
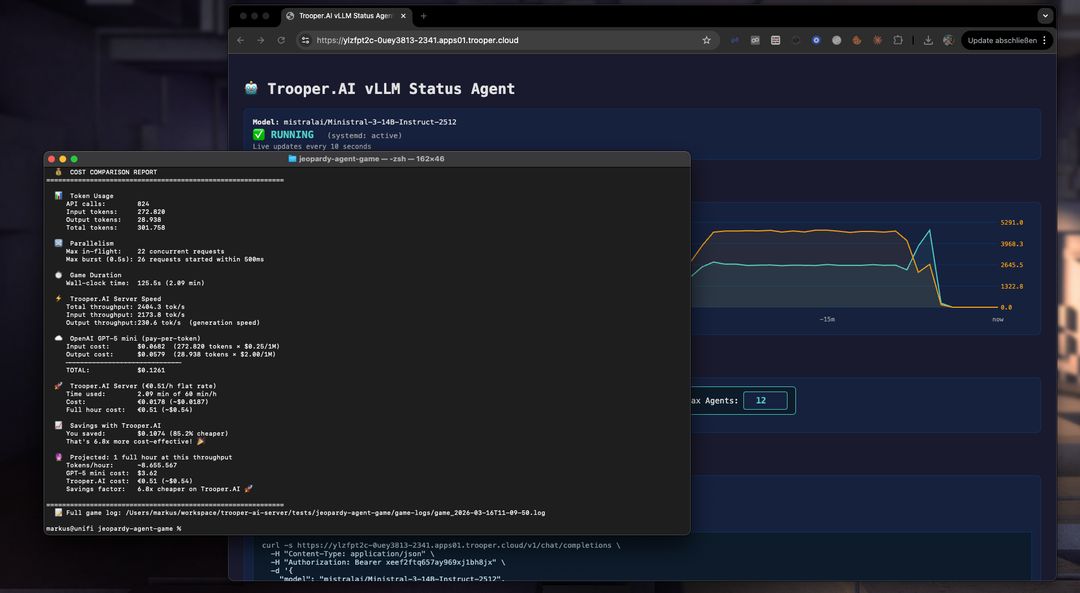
Lærdomme fra opbygningen af en AI-Jepardy-simulation med 12 spillere drevet af Ministral-3-14B-Instruct-2512.
En Praktisk Guide til Almindelig Tekst og JSON-Svar
Lærdomme fra opbygningen af en AI-Jepardy-simulation med 12 spillere drevet af Ministral-3-14B-Instruct-2512.
Ministral-3 på vLLM er overraskende kraftfuldt. Modellen er hurtig, kreativ og i stand til at producere højkvalitetsresponser selv ved tung belastning.
Når man bevæger sig fra enkle chattoprompt til strukturerede udgaver, automatisering eller programmeringsmæssig brug, bliver det hurtigt kompliceret.
Udviklingen af et
Denne vejledning opsummerer de praktiske erfaringer vi har gjort os under løsningen af disse udfordringer, sammen med konkrete mønstre du kan genbruge i dine egne projekter.
Vores benchmark-projekt simulerer et fuldt Jeopardy-spil, hvor:
Et enkelt spilforløb kan nemt overstige 800 API-opkald
Denne miljø afslørede grænseflader, der sjældent opstår i enkle demonstrationsmiljøer – hvilket gør det til et fremragende testgrundlag for at forstå, hvordan Ministral klare sig under reelle produktionsbelastninger
Ministral-modeller bruger ikke den standardiserede HuggingFace-tokenisatorkonfiguration
Det kræver, at opsætningen af kommandolinjen eksplicit aktiverer Mistral-tokenisatorformatet
vllm serve mistralai/Ministral-3-14B-Instruct-2512 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral
Hvis din applikation afhænger af funktionstildeling, skal du tilføje følgende værktøjsflags:
--enable-auto-tool-choice
--tool-call-parser mistral
Ministral understøtter ikke chat_template_kwargs, som nogle andre modeller gør.
Hvis du sender en anmodning som denne:
{
"chat_template_kwargs": {
"enable_thinking": false
}
}
vLLM returnerer:
HTTP 400: chat_template is not supported for Mistral tokenizers
Det betyder, at funktioner som eksplicit slåning af «tænkemodus» til/fra (brugt med modeller som Qwen eller DeepSeek) blot ikke er tilgængelige
Heldigvis er dette sjældent nødvendigt, da Ministral allerede producerer koncise output som standard.
Den officielle vLLM-dokumentation bruger konsekvent følgende værdi med Ministral-3:
temperature = 0.15
På første øjekast virker det ekstremt lavt. Dog viser det sig at være afgørende for strukturerede opgaver
Ved brug af OpenAI-standardindstillingen:
temperature: 0.7
modellen bliver for kreativ med strukturen
En simpel forespørgsel som:
{ "expertise": "2-3 topics they know best" }
kan returnere noget i stil med:
{
"expertise": [
{
"category": "Gourmet Pizza Alchemy",
"detail": "Can transform random ingredients into Michelin-star pizza"
},
{
"category": "Sumo Wrestling Physics",
"detail": "Understands body mechanics and center-of-gravity combat"
}
]
}
Det er ikke det skemaet spurgte om, selvom det teknisk set er gyldig JSON.
Resultatet:
max_tokens grænserne er overskredet0.15 fungerer bedrestrukturelt disciplineret
temperature: 0.15
Fordele:
Selv kreativ tekstgenerering forbliver stærk — modellen holder simpelthen op med at improvisere med strukturen.
Anbefaling:
Brug temperatur: 0.15 som standard for Ministral-3.
Maskinlæselig JSON at producere fra store sprogmodeller er sværere end det lyder.
Ministral har en tendens til at tolke skemas felter semantisk i stedet for strukturelt, hvilket fører til dybt indlejrede svar.
En prompt som:
Return JSON with these fields.
producerer ofte verbøse strukturer.
Eksempel på anmodning:
{ "expertise": "2-3 topics they know best" }
Typisk svar:
{
"expertise": [
{
"category": "Ancient Roman Engineering",
"detail": "Knows aqueduct systems in surprising detail"
},
{
"category": "Pizza Dough Chemistry",
"detail": "Obsessed with yeast fermentation dynamics"
}
]
}
Dette bruger tre gange så mange tokens som forventet
to instruktioner
Respond with ONLY valid JSON.
No markdown, no explanation, no text before or after the JSON.
Keep values as short plain strings — never use nested objects or arrays.
Lige ved siden af skema definitionen:
Every value MUST be a short plain string — NO arrays, NO nested objects.
temperatur 0.15, dette producerer forudsigeligt fladt JSON
Ministral producerer ofte længere værdier end andre modeller, selv når det er begrænset.
Eksempel på observation fra vores benchmark:
| Model | Nødvendige tokens |
|---|---|
| GPT-4o | ~512 |
| Qwen | ~512 |
| Ministral-3 | ~1024 |
En sikker regel:
Budgetér 1,5–2 gange så mange tokens til JSON-outputs.
Selv med perfekte prompter genererer modeller af og til misdannet JSON.
robuste afkodningslag
function extractJSON(raw, shape) {
var text = raw.replace(/^```(?:json)?\s*/i, '').replace(/\s*```$/i, '').trim();
if (shape === 'array') {
var m = text.match(/\[[\s\S]*\]/);
if (m) text = m[0];
} else {
var m = text.match(/\{[\s\S]*\}/);
if (m) text = m[0];
}
return text;
}
Spor åbne parenteser og luk dem automatisk:
var stack = [];
var inStr = false, esc = false;
for (var i = 0; i < text.length; i++) {
var ch = text[i];
if (esc) { esc = false; continue; }
if (ch === '\\') { esc = true; continue; }
if (ch === '"') { inStr = !inStr; continue; }
if (inStr) continue;
if (ch === '{') stack.push('}');
else if (ch === '[') stack.push(']');
else if (ch === '}' || ch === ']') stack.pop();
}
text = text.replace(/,\s*$/, '');
while (stack.length > 0)
text += stack.pop();
Hvis modellen stadig returnerer indlejrede strukturer:
if (Array.isArray(value)) {
flat = value.map(function(item) {
if (typeof item === 'string') return item;
if (typeof item === 'object') return Object.values(item).join(' — ');
return String(item);
}).join(', ');
}
En simpel retry-løkke øger pålideligheden dramatisk.
Ministral opfører sig konsistent ved lav temperatur, så gentagelser lykkes normalt.
Anbefalet:
2–3 retry attempts
Ministral elsker formatering.
Selv når du beder om klar tekst, har den tendens til at producere:
Dette sker fordi modellen leveres med en indbygget systemprompt, der opmuntrer til rig markdowntilformatering
Mange pipelines er afhængige af simple strengtjek.
Eksempel:
verdict.toUpperCase().startsWith('CORRECT')
Men hvis modellen returnerer:
**CORRECT**
kontrollen mislykkes.
Den sikreste tilgang er at normalisere alle output før behandling.
function stripMarkdown(text) {
if (!text) return text;
var s = text.replace(/\*\*([^*]+)\*\*/g, '$1');
s = s.replace(/__([^_]+)__/g, '$1');
s = s.replace(/\*([^*]+)\*/g, '$1');
s = s.replace(/^#{1,6}\s+/gm, '');
s = s.replace(/`([^`]+)`/g, '$1');
s = s.replace(/^```[a-z]*\s*$/gm, '');
return s.trim();
}
Anvend dette på alle modellsvar, ikke kun til Ministral.
Det undgår modelspecifik forgrening og holder pipelines konsistente.
Hvis dit system understøtter flere modellfamilier (Mistral, Qwen, DeepSeek, Llama osv.), er den mest vedligeholdelige løsning at centralisere modeladfærd på ét sted.
Eksempel:
function buildModelProfile(modelName) {
var lower = modelName.toLowerCase();
var isMistral = lower.includes('mistral') || lower.includes('ministral');
return {
family: isMistral ? 'Mistral' : 'Generic',
jsonSystemInstruction: isMistral
? 'Respond with ONLY valid JSON. No markdown. Keep values as short plain strings.'
: 'You output only valid JSON. No markdown fences, no explanation.',
jsonSchemaHint: isMistral
? ' Every value MUST be a short plain string — NO arrays, NO nested objects.'
: '',
jsonTemperature: isMistral ? 0.15 : 0.7,
defaultTemperature: isMistral ? 0.15 : 0.7,
plainTextInstruction: ' Do not use markdown formatting.'
};
}
Dette tillader resten af dit system at blive model-uafhængig.
Det bliver trivielt at tilføje en ny model senere.
| Indstilling | Anbefalet værdi | Årsag |
|---|---|---|
| tokenizer_mode | mistral | Påkrævet for korrekt tokenizer |
| config_format | mistral | Påkrævet |
| load_format | mistral | Påkrævet |
| chat_template_kwargs | Send ikke | Ikke understøttet |
| temperatur | 0.15 | Forhindrer strukturel hallucination |
| JSON-instruktion | Eksplicitte flade værdier | Undgå indlejrede objekter |
| max_tokens | 1,5–2× typisk | Modellen er ordrig |
| Fjernelse af Markdown | Altid | Forhindre formateringsfejl |
| JSON-genforsøg | 2–3 forsøg | Pålidelig gendannelse |
Ministral-3 yder ekstremt godt, når det er korrekt indstillet.
Når du:
meget forudsigeligt og klar til produktionsbrug
I vores Jeopardy-benchmark understøttede denne opsætning:
Alt kører lokalt på Trooper.AI's GPU-infrastruktur
Prøv den fulde vLLM-deployeringsskabelon her: vLLM OpenAI-Kompatibel Server
Lej din egen GPU-server i dag og begynd at bygge fantastiske AI-applikationer! Trooper.AI GPU-servere er bygget af udelukkende opcyklet high-end teknologi fra de seneste år, designet til at give dig den bedste ydeevne, sikkerhed og pålidelighed til alle dine AI-behov.
EU-placering · Høj privatlivsbeskyttelse · Fantastisk ydeevne · Bedste support