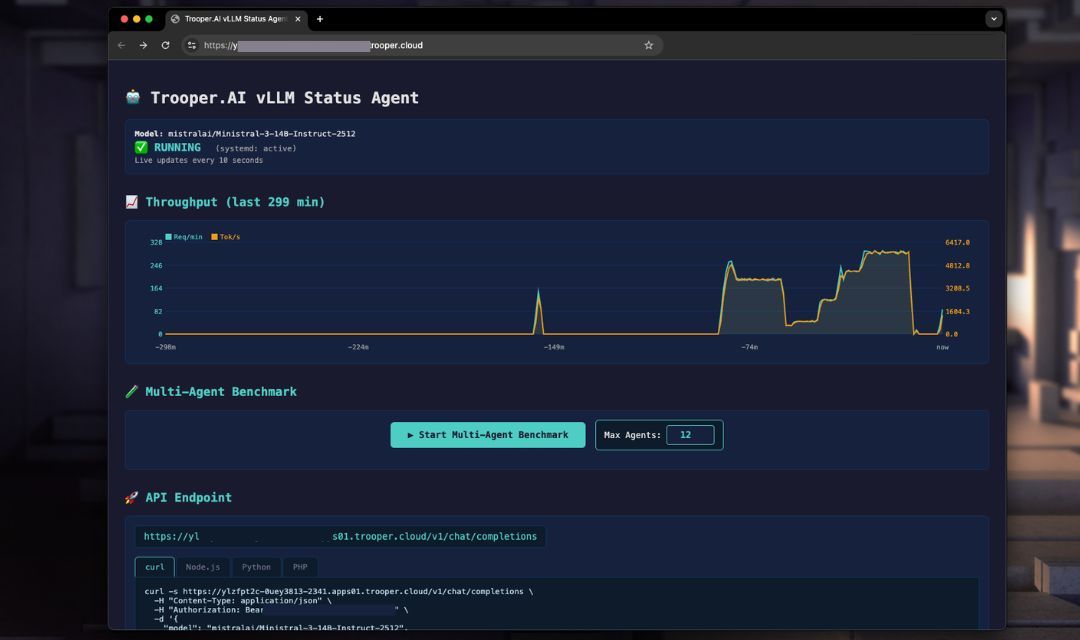
vLLM OpenAI-kompatibel server
Trooper.AI leverer en fuldautomatisk vLLM-implementeringsskabelon, der installerer, konfigurerer og kører en OpenAI-kompatibel inferensserver på din GPU-server ved hjælp af systemd.
Målet:
- Maksimal gennemstrømning
- Automatisk GPU-arkitekturjustering
- OpenAI-kompatibelt API
- Produktionssikre standardindstillinger
- Ingen manuel GPU-tuning påkrævet
Skabelonen udfører automatisk:
- Detekterer GPU-arkitektur og VRAM
- Vælger optimal præcision (FP16 / BF16 / FP8)
- Finjusterer batching og samtidighed
- Installerer vLLM i et virtuelt miljø
- Opretter en vedvarende systemd-tjeneste
- Udsætter OpenAI-kompatible endpoints
- Ydelsestest for at tune parametre
Du har kun kontrol over et lille sæt offentlige parametre.
Forståelse af GPU-antallet: vLLM fungerer med flere GPU'er, men kræver at antallet af GPU'er jævnt skal dele modellen's opmærksomhedshoveder (attention heads). For eksempel kan en model som Gemma med 32 opmærksomhedshoveder bruge 1, 2, 4 eller 8 GPU'er – men ikke 3.
Vigtig sikkerhedsnote om skærmbilleder: De servere, der vises på skærmbillederne, er kun til demonstrationsformål og beskyttes af Trooper.AI Network-Level Firewall, som følger med alle bestillinger af GPU-servere. For detaljerede oplysninger, se 🛡️ Indbygget firewall før din GPU-server.
Indstillinger for vLLM-skabelonen
Denne skabelon deployer en klar-til-brug vLLM-inference-server på din Trooper.AI-instance. Den installerer den nødvendige runtime, konfigurerer API-endpointen og forbereder modellen til OpenAI-kompatibel kommunikation.
Nedenfor er en kort forklaring af hver konfigurationsmulighed.
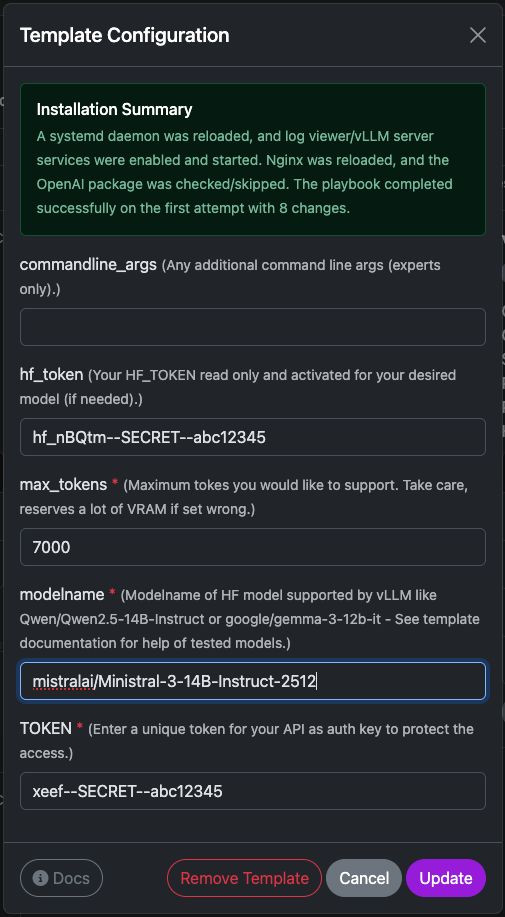
commandline_args
Valgfrie avancerede argument overført direkte til vLLM-serverens opstartskommando
Brug dette, hvis du har brug for at aktivere yderligere funktioner såsom:
- tensor parallelisme
- kvantisering
- værktøjskald
- brugerdefinerede tokenizer-indstillinger
- spekulativ afkodning
Eksempel:
--tensor-parallel-size 2
Lad stå tom, medmindre du præcist ved, hvilke flags du vil bruge.
hf_token
Din Hugging Face adgangstoken
Dette er påkrævet, hvis modellen:
- kræver godkendelse
- kræver autentificering
- et privat repo
For offentlige modeller kan dette felt udelades.
Du kan generere en token her:
https://huggingface.co/settings/tokens
Tokenet bruges kun under modeldownload.
max_tokens
definerer det maksimale kontekstvindue, som serveren skal understøtte.
Dette påvirker direkte VRAM-forbruget.
Typiske værdier:
| Kontekst | Anbefalet |
|---|---|
| små modeller | 4096 |
| mellemstore modeller | 8192 |
| modeller med lang kontekst | 16384+ |
Højere værdier øger hukommelsesforbruget betydeligt. Hvis din server løber tør for VRAM, skal du sænke denne værdi.
modelnavn
Hugging Face-modelidentifikatoren, som vLLM skal indlæse.
Eksempel:
mistralai/Ministral-3-14B-Instruct-2512
Andre kompatible eksempler:
Qwen/Qwen2.5-14B-Instruct
google/gemma-3-12b-it
meta-llama/Meta-Llama-3-8B-Instruct
... and many more
Sørg for, at modellen understøttes af vLLM og passer ind i din GPU-hukommelse.
TOKEN
Dette er din API-autentificeringsnøgle
Alle anmodninger til vLLM-serveren skal inkludere dette token i headeren:
Authorization: Bearer YOUR_TOKEN
Dette beskytter din server mod uautoriseret adgang.
Eksempel på anmodning:
curl https://your-server/v1/chat/completions \
-H "Authorization: Bearer YOUR_TOKEN"
Brug en stærk tilfældig streng.
Modelstørrelse & GPU-krav
Du kan anvende en bred vifte af store sprogmodeller fra HuggingFace i vLLM. Sørg for, at der er tilstrækkelig VRAM til rådighed, da ydeevnen er afhængig af, at der er tilstrækkelig fri GPU VRAM til at rumme modellen og kontekststørrelsen, ganget med antallet af samtidige brugere.
Trooper.AI vælger automatisk optimal præcision per GPU-arkitektur.
VRAM-beregning: Modellvægte + ~25% KV-cache-buffer.
VRAM kan deles mellem flere GPU'er via Tensor Parallelism (--tensor-parallel-size N).
| Model | Parametre | Præcision | Min. VRAM Total | GPU Konfiguration | GPU'er |
|---|---|---|---|---|---|
| Qwen/Qwen3-4B | 4B | BF16 | ~8 GB | 1× V100 16GB / RTX 4070 Ti Super | 1 |
| Qwen/Qwen3-8B | 8B | BF16 | ~20 GB | 1× RTX 3090 / RTX 4090 (24 GB) | 1 |
| mistralai/Ministral-3-14B-Instruct-2512 | 14B | FP8 | ~29 GB | 1× RTX 4080 Pro 32GB eller 1× A100 40GB | 1 |
| Qwen/Qwen3-32B | 32B | FP8 | ~40 GB | 1× A100 40GB eller 2× RTX 4090 (2×24 GB) | 1–2 |
| meta-llama/Llama-3.1-8B-Instruct | 8B | FP8 | ~20 GB | 1× RTX 3090 / RTX 4090 (24 GB) | 1 |
| meta-llama/Llama-3.1-70B-Instruct | 70B | FP8 | ~90 GB | 1× RTX Pro 6000 Blackwell (96 GB) eller 2× A100 (2×40 GB) | 1–2 |
Mærkat: FP8 benyttes på Ada/Hopper-arkitekturer (RTX 40-serie, A100, H100) for at opnå maksimalt igennemtænkningsevne.
Trooper.AI vælger automatisk den bedst mulige nøjagtighed for din GPU.
Konfigurationer med flere GPU'er udnytter Tensor Parallelism – VRAM skaleres lineært tværs over GPU'erne.
Offentlige parametre
Disse parametre kan indstilles via miljøvariabler før installationen køres.
| Variabel | Beskrivelse |
|---|---|
TOKEN |
API-nøgle til godkendelse |
modelname |
HuggingFace modelsti |
hf_token |
HuggingFace token (for låste modeller) |
commandline_args |
Valgfrie ekstra vLLM CLI-argumenter |
Automatisk benchmarking til at finjustere parametre
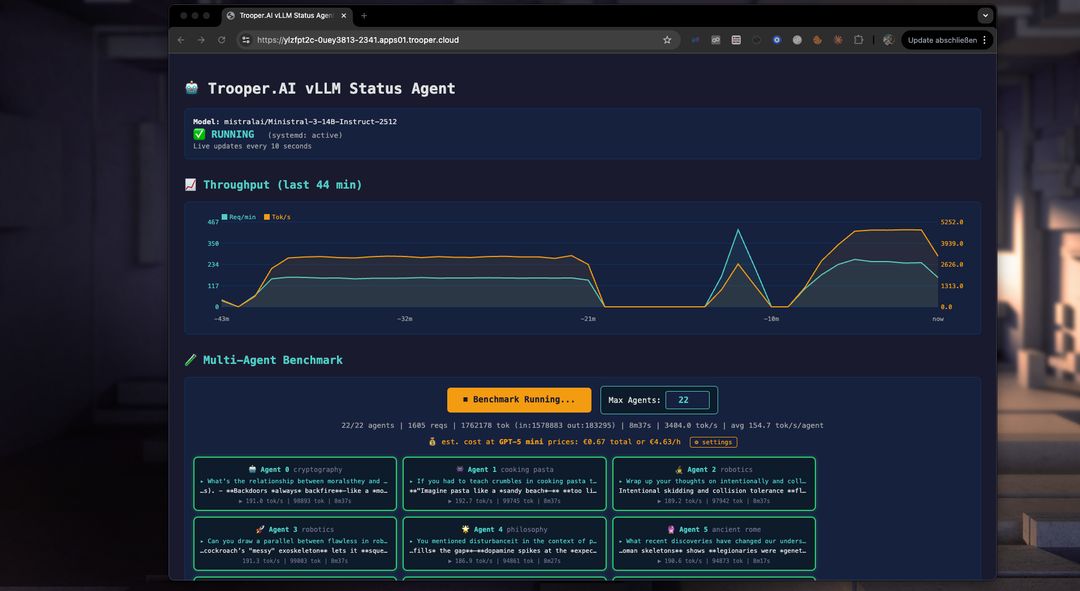
Vores skabelon inkluderer en ydelsesmåling, der hjælper dig med at optimere din GPU-server til multi-agent-brug. Brug den til at teste og sammenligne modeller, GPU-typer og parametre for at maksimere gennemstrømning og samtidige brugere.
Hvordan fungerer benchmarken?
Benchmarken starter flere agenter samtidig, der hver interagerer med vLLM-serverens endepunkt om et forskelligt emne. Dette forhindrer caching og tester ydeevnen i virkelige situationer. Du kan se gennemstrømningen for hver agent, den samlede gennemstrømning og sammenligne omkostningerne ved tokeniserede tjenester som GPT-5 mini. Ofte er en vLLM-server fra Trooper.AI 2-4 gange billigere end store token-baserede inferencetjenester, samtidig med at dit LLM-arbejde holdes privat!
Hvad skabelonen gør
-
Detekterer GPU-arkitektur (Volta, Ampere, Ada, Hopper, Blackwell)
-
Detekterer VRAM-størrelse
-
Vælger automatisk optimal præcision:
- FP8 > BF16 > FP16
-
Bruger FP16 KV cache for stabilitet
-
Indstillinger:
- maksimum samtidige sekvenser
- batchstørrelse af tokens
- hukommelsesudnyttelse
-
Installerer vLLM med CUDA
Opretter en systemd-tjeneste:
Kodevllm-server.service-
Starter en vedvarende OpenAI-kompatibel API-server på et sikkert HTTPS-endepunkt.
Ingen manuel finjustering er nødvendig.
API Endepunkter
Base URL:
http://YOUR_SERVER:PORT/v1
Endepunkter:
/v1/models/v1/completions/v1/chat/completions
Autorisationsheader:
Authorization: Bearer YOUR_TOKEN_FROM_CONFIG
Eksempel på Python-klient
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1"
)
resp = client.chat.completions.create(
model="Qwen/Qwen3-14B",
messages=[
{"role": "user", "content": "Hello, what is vLLM?"}
],
max_tokens=200
)
print(resp.choices[0].message.content)
Node.js Klienteksempel
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "YOUR_API_KEY",
baseURL: "https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1"
});
const completion = await client.chat.completions.create({
model: "Qwen/Qwen3-14B",
messages: [
{ role: "user", content: "Hello from Node.js" }
],
max_tokens: 200
});
console.log(completion.choices[0].message.content);
PHP Klient Eksempel
<?php
$ch = curl_init("https://YOUR_SERVER_ENDPOINT.apps.trooper.ai/v1/chat/completions");
$data = [
"model" => "Qwen/Qwen3-14B",
"messages" => [
["role" => "user", "content" => "Hello from PHP"]
],
"max_tokens" => 200
];
curl_setopt_array($ch, [
CURLOPT_POST => true,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_HTTPHEADER => [
"Authorization: Bearer YOUR_API_KEY",
"Content-Type: application/json"
],
CURLOPT_POSTFIELDS => json_encode($data)
]);
$response = curl_exec($ch);
curl_close($ch);
echo $response;
Streaming Eksempel
Python Streaming
resp = client.chat.completions.create(
model="Qwen/Qwen3-14B",
messages=[{"role":"user","content":"Explain transformers"}],
stream=True
)
for chunk in resp:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Node.js Streaming
const stream = await client.chat.completions.create({
model: "Qwen/Qwen3-14B",
messages: [{ role: "user", content: "Explain transformers" }],
stream: true
});
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0].delta?.content || "");
}
Anvendelseseksempler
Trooper.AI vLLM-servere er designet til:
- SaaS AI-backends
- Chatbots
- Kodeassistenter
- RAG-systemer
- Flerbruger-inferensservere
- Høj gennemstrømning batch-inferens
- GPU-udlejningsmiljøer
Ydeevnefilosofi
Trooper.AI anvender:
- Automatisk arkitekturjustering
- Automatisk præcisionsvalg
- VRAM-bevidst batching
- Stabil KV cache konfiguration
Dette undgår:
- Forkert GPU-konfiguration
- Præcisionsnedbrud
- VRAM-fragmentering
- Kontekstuel ustabilitet
Omkostningssammenligning: Ministral-3 på Trooper.AI vs GPT-5 mini
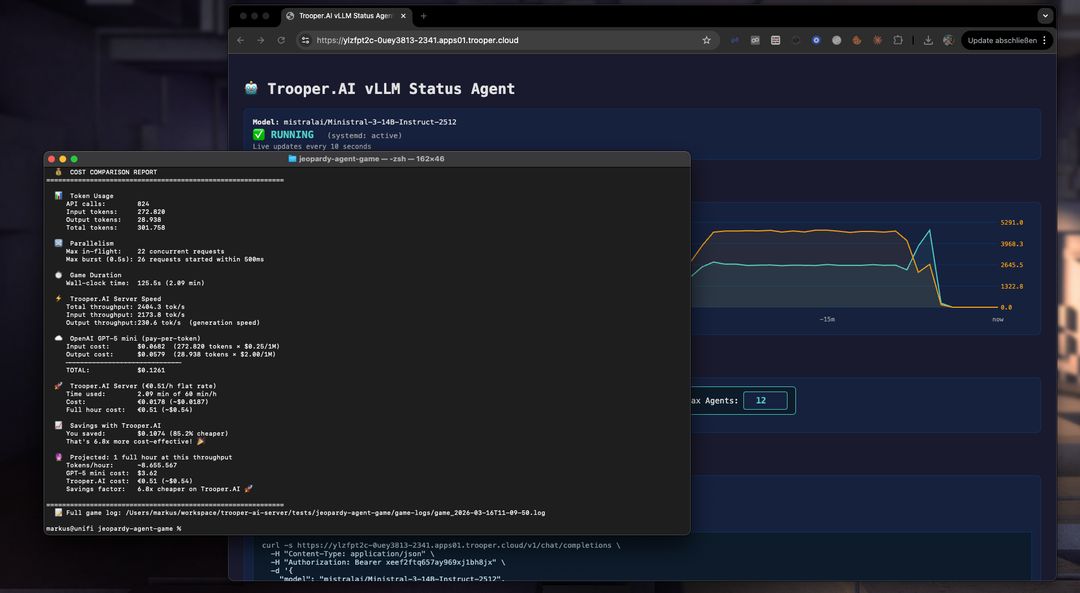
For at give en grov idé om økonomien ved selv-hosting, projekterer den følgende sammenligning omkostningerne ved at køre Ministral-3-14B-Instruct-2512 på en Trooper.AI GPU-server i forhold til at bruge GPT-5 mini API til den samme arbejdsbelastning.
Estimatet er baseret på den faktiske benchmark-kørsel beskrevet i denne artikel og ekstrapoleret til en times kontinuerlig inferensgennemstrømning.
Timelig omkostning ved målt gennemløb
| Platform | Timeløn |
|---|---|
| GPT-5 mini API | ~$3.12 |
| Ministral-3-14B på en Trooper.AI GPU-server | €0.51 (~$0.54) |
Sådan blev dette beregnet
Denne vurdering er baseret på den reelle benchmark-kørsel i denne artikel ved brug af Ministral-3-14B-Instruct-2512 på en Trooper.AI GPU-server
| Måling | Værdi |
|---|---|
| Samlet antal behandlede tokens | 307,028 |
| Kørselstid | 153 sekunder |
| Gennemstrømning | ~2006 tokens/sek |
| Projekterede tokens/time | ~7,22M tokens |
Token-blanding i benchmarken:
| Token type | Tokens |
|---|---|
| Indgangstokens | 275,186 |
| Output tokens | 31,842 |
Skaler denne forhold til ~7,22 mio. tokens/time og anvender priserne fra GPT-5 mini:
- 0,25 € / 1M input tokens
- 2,00 € / 1M output tokens
resulterer i en estimeret pris på ca.
Ministral-3-serveren på Trooper.AI kører derimod til en fast pris på €0.51/time (~$0.54), uanset mængden af tokens, hvilket muliggør behandling af millioner af tokens pr. time til forudsigelig omkostning
Langvarig Arbejdsbelastningsprojektion
ved fuld drift i en time
| Måling | Værdi |
|---|---|
| Tokens per time | ~7,221,543 |
| GPT-5 mini pris | $3.12 |
| Trooper.AI serveromkostning | €0.51 (~$0.54) |
Timeløn
Kører du den samme arbejdsbelastning i en time, vil det stadig være:
≈ 5,8 gange billigere på Trooper.AI
Når selv-hosting bliver meget billigere
Selv-hosting af LLM'er har tendens til at vinde økonomisk når:
- arbejdsbelastninger med mange små henvendelser
- parallelinference er påkrævet
- milliarder af tokens om timen
- kontinuerligt
Typiske eksempler inkluderer:
- AI-spilssimuleringer
- agent systemer
- automatiseringspipelines
- chat-applikationer med mange brugere
Opsummering
I denne benchmark:
| Måling | Resultat |
|---|---|
| Model | Ministral-3-14B |
| Serveromkostninger | €0.51/hour |
| Behandlede tokens | 307k |
| Kørselstid | 153 sekunder |
| Omkostningsreduktion | 82.8% |
| Omkostningsfordel | 5,8 gange billigere end GPT-5 mini |
Ministral-3 på Trooper.AI GPU-servere kan dramatisk reducere omkostningerne ved inferens i højkapacitetsarbejdsbelastninger samtidig med at man fjerner API-hastighedsbegrænsninger.
Hvorfor du har brug for vLLM-skabelonen
Trooper.AI vLLM skabelonen giver dig:
- OpenAI-kompatibelt API
- Automatisk GPU-optimering
- Produktionssikre standardindstillinger
- Minimal konfiguration
- Maksimal gennemstrømning
Du vælger kun modellen og API-nøglen.
Alt andet er optimeret automatisk.
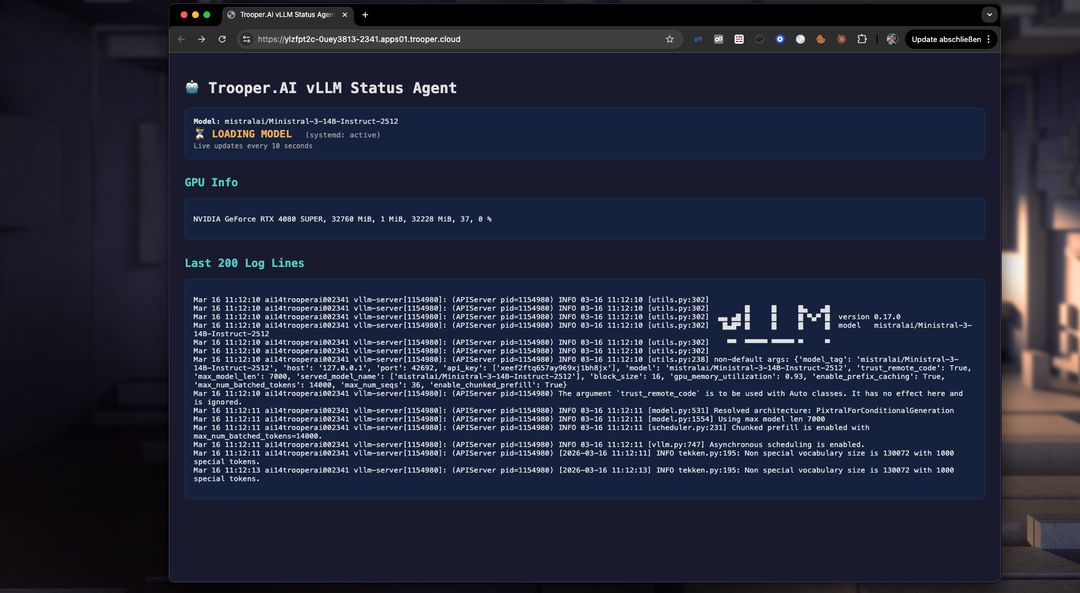
Fejlfinding
Med dashboardet kan du nemt identificere problemer ved opstart og løse dem. Ikke nok VRAM? Opgrader til en højere Blib på få minutter via dashboardet. Eller optimer VRAM-forbruget ved at reducere token-vinduesstørrelsen. Tjek logfilerne nemt i realtid med dashboardet:
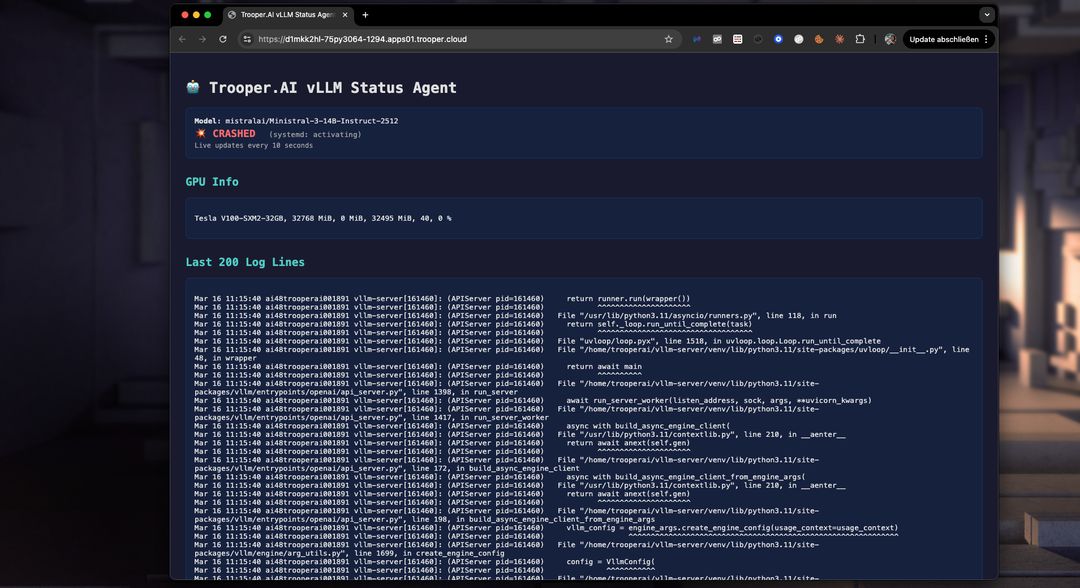
Nemotron 3 Nano med Tokenværdi
Til NVIDIA Nemotron 3 Nano har du mindst brug for vLLM-version 0.18.1 (natversion pr. 2025-03-30). Du kan konfigurere parseren og tokensgrænsen, så du kan bruge thinking_token_budget. Læs mere her: https://docs.vllm.ai/en/latest/features/reasoning_outputs/#online-serving.
Vær opmærksom på, at dette vil nedsætte throughput med ca. -30%!
Ændr `command_line_args` til noget som dette:
--async-scheduling
--reasoning-parser-plugin /home/trooperai/vllm-server/nano_v3_reasoning_parser.py
--reasoning-parser nano_v3
--reasoning-config '{"think_start_str": "<think>", "think_end_str": " - I have to give the solution based on the thinking directly now:</think>"}'
Hent parser fra:
wget -O - https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16/resolve/main/nano_v3_reasoning_parser.py
Alternativt kan du bruge `nemotron_3_parser` og sætte den til ON. Dette vil gøre det her for dig. Sørg også for at aktivere nightly developer build!
Derved får du mere kontrol over reasoning-funktionen i Nemotron 3 Nano.
Support
Kontakt Trooper.AI support for avanceret tuning, multi-GPU eller brugerdefinerede presets.