Dowolny Docker
Ten szablon umożliwia wdrażanie zarówno kontenerów Docker z akceleracją GPU, takich jak ComfyUI, jak i kontenerów bez obsługi GPU, takich jak n8n. Ta elastyczność pozwala na szeroki zakres zastosowań, od generowania obrazów AI po zautomatyzowane przepływy pracy, wszystko w jednym, łatwym w zarządzaniu środowisku. Skonfiguruj i uruchom żądane kontenery Docker bez wysiłku, wykorzystując moc i wygodę tego wszechstronnego szablonu.
Choć możesz woleć zarządzać konfiguracjami Docker bezpośrednio, zalecamy skorzystanie z naszego szablonu «Any Docker» do początkowego skonfigurowania. Konfiguracja Docker z obsługą GPU może być skomplikowana, a ten szablon zapewnia uproszczoną podstawę do budowania i deployowania Twoich kontenerów.
🚨 Ważne uwagi dotyczące wielu kontenerów Docker!
Aby zapewnić prawidłowe działanie podczas uruchamiania wielu kontenerów Docker na serwerze GPU, konieczne jest przypisanie każdemu kontenerowi unikalnej nazwy i katalogu danych. Na przykład, zamiast używać „my_docker_container”, określ nazwę taką jak „my_comfyui_container” i ustaw katalog danych na unikalną ścieżkę, taką jak /home/trooperai/docker_comfyui_dataTen prosty krok pozwoli na uruchomienie wielu kontenerów Docker bez konfliktów.
Przykład 1: Serwer LLM kompatybilny z OpenAI via HF
Ten przykład wyjaśnia krok po kroku, jak uruchomić API kompatybilne z OpenAI (vLLM) przy użyciu szablonu any-docker od Trooper.AI. Jest napisany w sposób przystępny także dla osób z niewielką znajomością Docker czy sztucznej inteligencji.
Ta konfiguracja wykorzystuje Qwen/Qwen3-4B, który jest obsługiwany i uruchomialny na wszystkich serwerach GPU z Trooper.AI.
Co robi ta konfiguracja
- Serwer vLLM uruchamiany wewnątrz kontenera Docker
- Ładuje model Qwen/Qwen3-4B z Hugging Face
- API HTTP kompatybilne z OpenAI
- Działa z nowoczesnymi sterownikami NVIDII (CUDA 13 / 580+)
Dlaczego ta konfiguracja jest potrzebna
Na nowszych sterownikach NVIDIA starsze obrazy Docker vLLM mogą się zawieszać z błędami CUDA podczas uruchamiania.
Aby tego uniknąć, szablon any-docker:
- obraz nocny vLLM
- Wymusza ładowanie bibliotek sterowników NVIDIA z gospodarza
Nie musisz modyfikować tej logiki — po prostu użyj konfiguracji poniżej.
Zmienne szablonu
Zobacz tutaj zrzut ekranu, jak skonfigurować oraz pełny tekst do skopiowania i wklejenia poniżej.
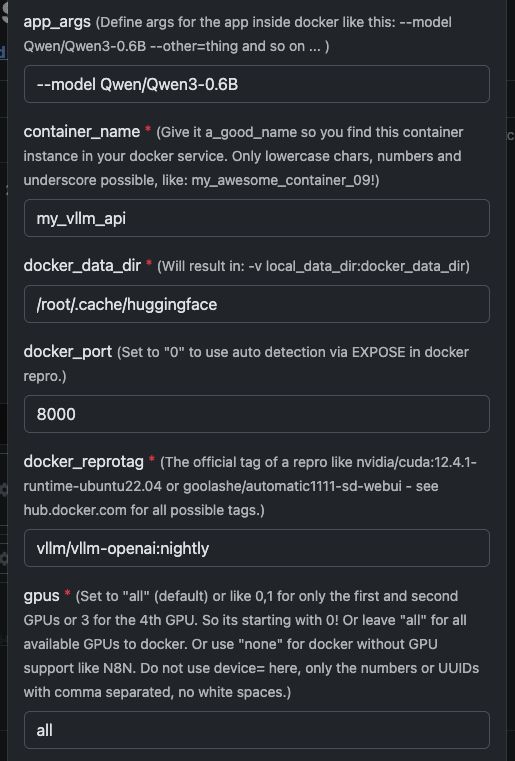
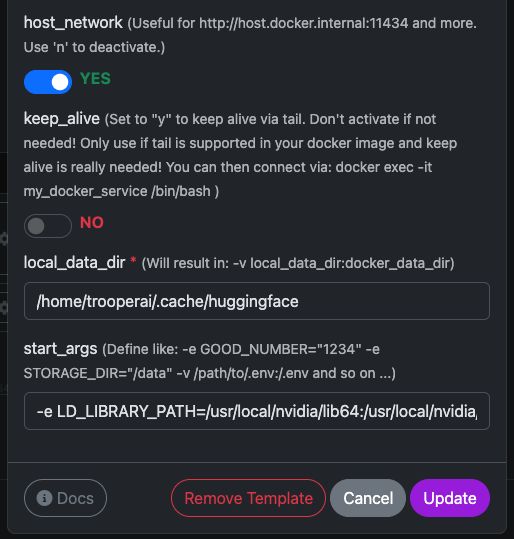
| Zmienna | Wartość | Co to oznacza |
|---|---|---|
app_args |
--model Qwen/Qwen3-4B |
Określa, który model ma załadować vLLM. |
container_name |
my_vllm_api |
Nazwa kontenera Docker. |
docker_reprotag |
vllm/vllm-openai:nightly |
Obraz vLLM z poprawkami dla nowoczesnych sterowników NVIDIA. |
docker_port |
8000 |
Port wewnętrzny używany przez vLLM. |
gpus |
all |
Udostępnia wszystkie GPU dla Dockera. |
host_network |
YES |
Udostępnia API bezpośrednio w sieci hosta. |
keep_alive |
NO |
Normalny cykl życia kontenera (zalecane). |
local_data_dir |
/home/trooperai/.cache/huggingface |
Katalog pamięci podręcznej modelu na hoście. |
docker_data_dir |
/root/.cache/huggingface |
Katalog pamięci podręcznej modelu wewnątrz kontenera. |
start_args |
-e LD_LIBRARY_PATH=/usr/local/nvidia/lib64:/usr/local/nvidia/lib:/usr/lib/x86_64-linux-gnu --ipc=host --env HF_TOKEN=… |
Wymagana poprawka dla CUDA i pamięci współdzielonej. |
Ważna uwaga dotycząca LD_LIBRARY_PATH
Ten ustawienie jest obowiązkowe w systemach z CUDA 13.
Bez niego vLLM może nie uruchomić się ze względu na niezgodność sterowników NVIDIA.
Nie usuwaj tego.
Jak sprawdzić, czy to działa
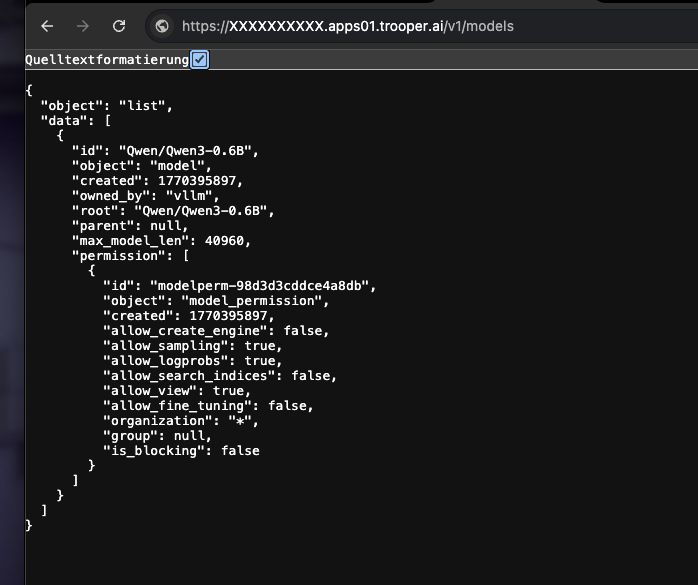
Uruchom następujące polecenie:
curl https://XXXXXXXX.apps01.trooper.ai/v1/models
Jeśli widzisz Qwen/Qwen3-4B w odpowiedzi, serwer działa poprawnie.
Przykład użycia z curl
curl https://XXXXXXXX.apps01.trooper.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer dummy-key" \
-d '{
"model": "Qwen/Qwen3-4B",
"messages": [
{ "role": "user", "content": "What is Trooper.AI?" }
]
}'
Przykład użycia z Node.js
Proste żądanie
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const result = await client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: "What is Trooper.AI?" }],
});
console.log(result.choices[0].message.content);
Test obciążeniowy współbieżny Node.js (16 równoległych żądań)
Ten przykład wysyła 16 równoległych żądań do API i wyświetla prosty podsumowanie przepustowości.
import OpenAI from "openai";
import crypto from "crypto";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const CONCURRENCY = 16;
function randomPrompt() {
return `Explain this random concept in one sentence: ${crypto.randomUUID()}`;
}
const startTime = Date.now();
const requests = Array.from({ length: CONCURRENCY }, () =>
client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: randomPrompt() }],
})
);
const responses = await Promise.all(requests);
const endTime = Date.now();
const durationSeconds = (endTime - startTime) / 1000;
let totalTokens = 0;
for (const r of responses) {
totalTokens += r.usage.total_tokens;
}
const tokensPerSecond = (totalTokens / durationSeconds).toFixed(2);
console.log(
`${tokensPerSecond} token/s of total ${totalTokens} tokens in ${durationSeconds.toFixed(
2
)} seconds on ${CONCURRENCY} concurrent connections`
);
Ten test jest przydatny do:
- weryfikacja współbieżności
- szacowanie przepustowości
- szybkie testy poprawności działania
Jak uzyskać wsparcie dla serwera GPU vLLM?
W przypadku jakichkolwiek problemów z vLLM skontaktuj się z supportem. Jesteśmy bardzo doświadczeni w korzystaniu z vLLM.
Zobacz nasz dział Benchmarki, aby porównać swoją instalację vLLM z naszymi testami wydajności, skupiając się na wynikach wielowątkowości.
Dodatkowe informacje o autoryzacji vLLM: jak ustawić i używać klucza API
API kompatybilne z OpenAI, ale domyślnie nie wymaga rzeczywistego klucza API
Masz dwie opcje:
Opcja 1: Użyj klucza zastępczego (domyślnie, najłatwiejsze)
Jeśli autoryzacja nie jest wymuszana, możesz użyć dowolnego ciągu znaków jako klucza API.
curl
-H "Authorization: Bearer dummy-key"
Node.js
apiKey: "dummy-key"
Jest to wystarczające dla większości wdrożeń wewnętrznych, prywatnych lub zabezpieczonych sieci.
Opcja 2: Ustaw prawdziwy klucz API (zalecane dla publicznych punktów końcowych)
Możesz wymusić użycie klucza API, ustawiając go jako zmienną środowiskową podczas uruchamiania kontenera.
W szablonie any-docker (start_args):
--env OPENAI_API_KEY=your-secret-key
vLLM będzie wymagał tego klucza w każdym żądaniu.
Przykładowe żądanie curl:
curl https://your-endpoint/v1/models \
-H "Authorization: Bearer your-secret-key"
Przykład w Node.js:
const client = new OpenAI({
apiKey: "your-secret-key",
baseURL: "https://your-endpoint/v1",
});
Jak obracać lub zmieniać klucz
- Aktualizuj
OPENAI_API_KEYw szablonie - Kliknij na „zaktualizuj szablon”
- Stare klucze natychmiast przestają działać
Podsumowanie
- Klucz nie jest wymagany → użyj
dummy-key - Punkt końcowy publiczny → ustaw
OPENAI_API_KEY - Klucz jest nigdy niegenerowany automatycznie; ty go definiujesz
To utrzymuje uwierzytelnianie proste i jednoznaczne.
Przykład 2: Uruchamianie Qdrant na serwerze GPU
Qdrant to wysokowydajna baza danych wektorowa, która obsługuje wyszukiwanie podobieństwa, wyszukiwanie semantyczne i osadzanie w dużej skali.
Wdrożony na serwerze Trooper.AI z GPU, Qdrant może indeksować i wyszukiwać miliony wektorów niezwykle szybko — idealnie nadaje się do systemów RAG, pamięci LLM, silników personalizacji i systemów rekomendacji.
Poniższy przewodnik pokazuje jak uruchomić Qdrant za pomocą Docker, jak wygląda w panelu sterowania oraz jak poprawnie zapytać go przy użyciu Node.js
Uruchamianie kontenera Docker Qdrant
Możesz łatwo uruchomić oficjalny qdrant/qdrant Kontener Dockera z ustawieniami przedstawionymi poniżej.
Te zrzuty ekranu pokazują typową konfigurację używaną na serwerach GPU Trooper.AI, w tym:
- Udostępniony port REST API
- Dostęp do panelu sterowania
- Trwałość danych
- Opcjonalne przyspieszenie GPU (jeśli włączone w Twoim środowisku)
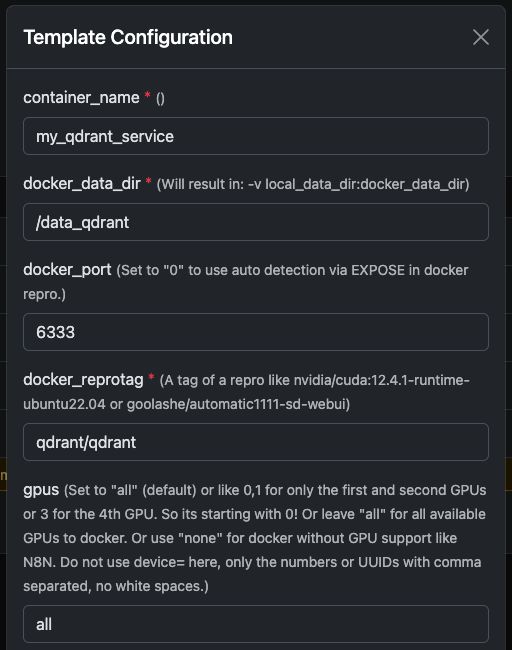
Panel administracyjny Qdrant oraz API REST będą natychmiast dostępne po uruchomieniu.
Podgląd panelu Qdrant
Panel umożliwia przeglądanie kolekcji, wektorów, ładunków i indeksów.
Typowa konfiguracja panelu wygląda następująco:
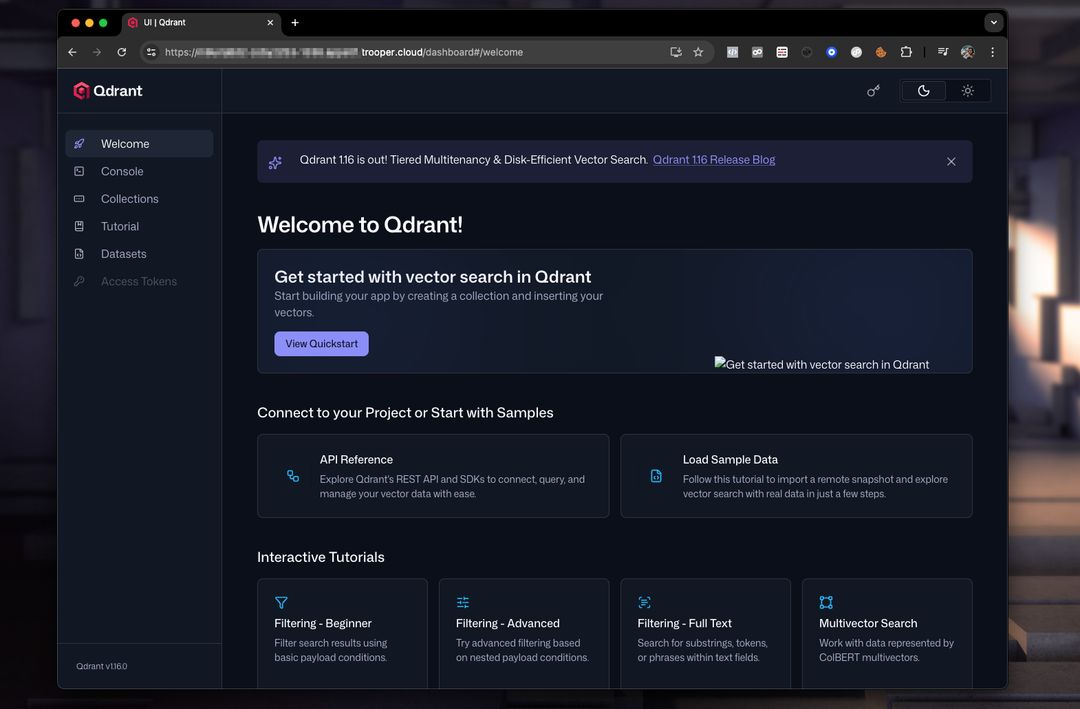
Stąd możesz:
- Utwórz kolekcje
- Dodaj wektory
- Uruchom przykładowe wyszukiwania
- Sprawdź metadane
- Monitorowanie wydajności
Pytania do Qdrant z Node.js
Poniżej znajduje się sprawdzony i poprawny przykład w Node.js korzystający z Qdrant REST API.
Ważne poprawki w stosunku do oryginalnego przykładu:
- Qdrant wymaga wywołania punktu końcowego takiego jak:
/collections/<collection_name>/points/search wektormusi być tablicą, a nie(a, b, c)- Nowoczesny Node.js posiada natywne
fetchwięc nie ma potrzebynode-fetch
PRZYKŁAD NODEJS
// Qdrant Vector Search Example – fully compatible with Qdrant 1.x and 2.x
async function queryQdrant() {
// Replace "my_collection" with your actual collection name
const url = 'https://AUTOMATIC-SECURE-URL.trooper.ai/collections/my_collection/points/search';
const payload = {
vector: [0.1, 0.2, 0.3, 0.4], // Must be an array
limit: 5
};
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
});
if (!response.ok) {
throw new Error(`Qdrant request failed with status: ${response.status}`);
}
const data = await response.json();
console.log('Qdrant Response:', data);
return data;
} catch (error) {
console.error('Error querying Qdrant:', error);
return null;
}
}
queryQdrant();
Poprawny ładunek zapytania do Qdrant
Qdrant oczekuje treści JSON w następującym formacie:
{
"vector": [0.1, 0.2, 0.3, 0.4],
"limit": 5
}
Gdzie:
- wektor → twoje wbudowanie
- limit → maksymalna liczba zwróconych wyników
Możesz również dodać zaawansowane filtry, jeśli zajdzie potrzeba:
{
"vector": [...],
"limit": 5,
"filter": {
"must": [
{ "key": "category", "match": { "value": "news" } }
]
}
}
Uwagi dla użytkowników Trooper.AI
- Zastąp
AUTOMATIC-SECURE-URL.trooper.aiz Twoim przydzielonym bezpiecznym punktem końcowym - Upewnij się, że Twoja kolekcja istnieje przed wysłaniem zapytania.
Przykład: Uruchamianie N8N z Any Docker
W tym przykładzie skonfigurujemy Any Docker z Twoją konfiguracją dla n8n oraz trwałym przechowywaniem danych, aby restarty były możliwe bez utraty danych. Ta konfiguracja nie zawiera webhooków. Jeśli potrzebujesz webhooków, przejdź do dedykowanego wstępnie skonfigurowanego szablonu: n8n
Ten przewodnik służy wyłącznie do wyjaśnienia. Możesz uruchomić dowolny kontener dockerowy, który chcesz.
Zobacz zrzuty ekranu konfiguracji poniżej:
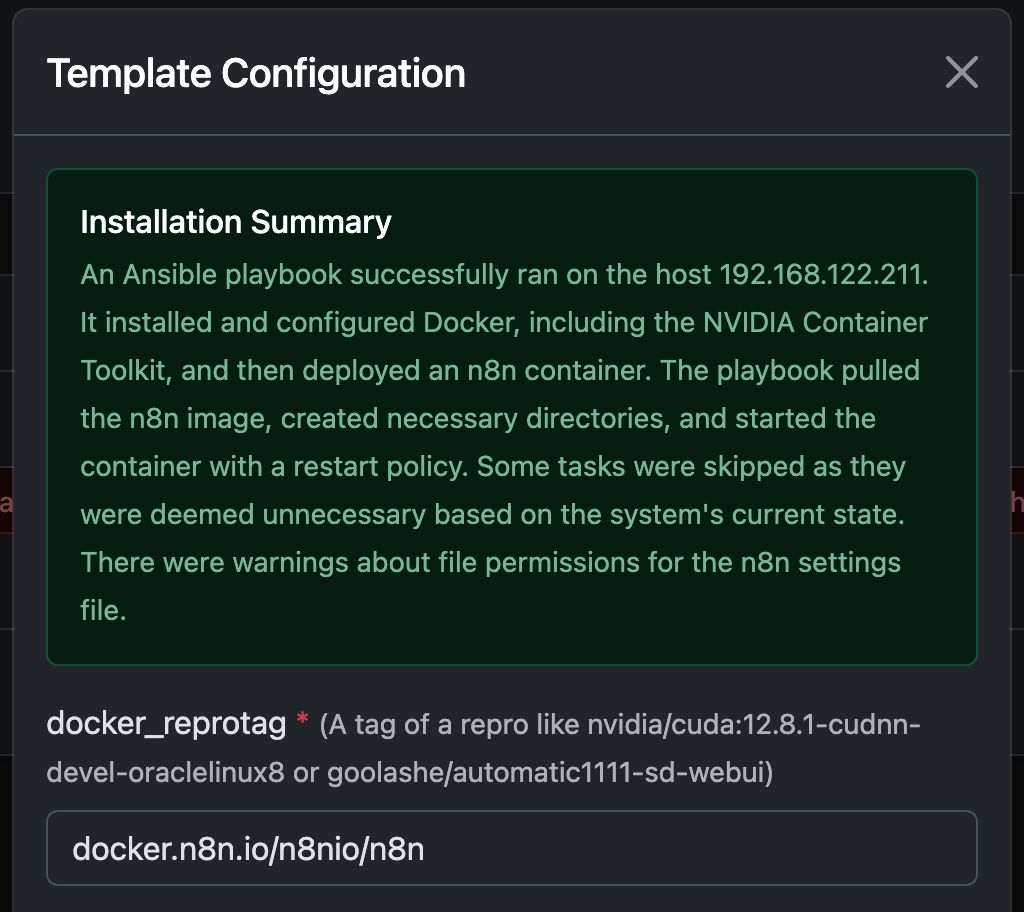
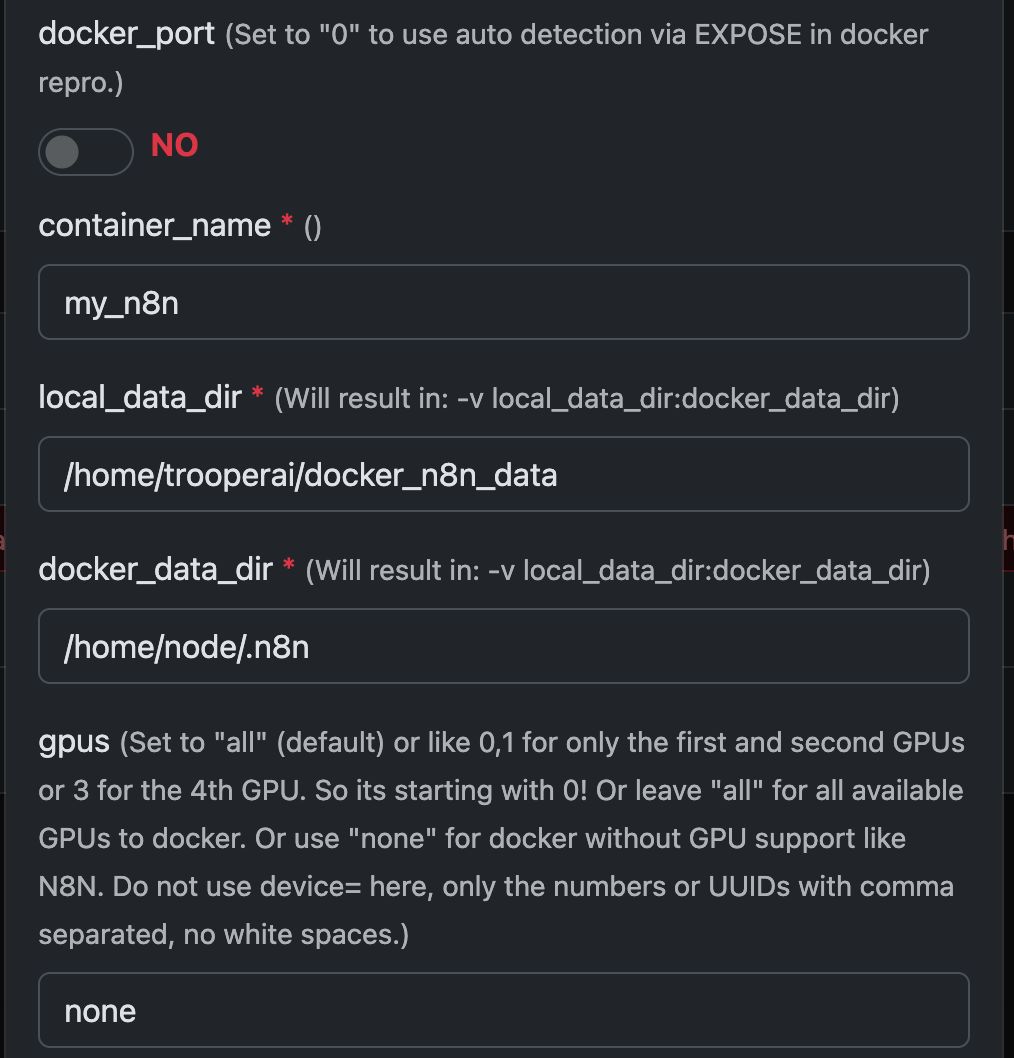
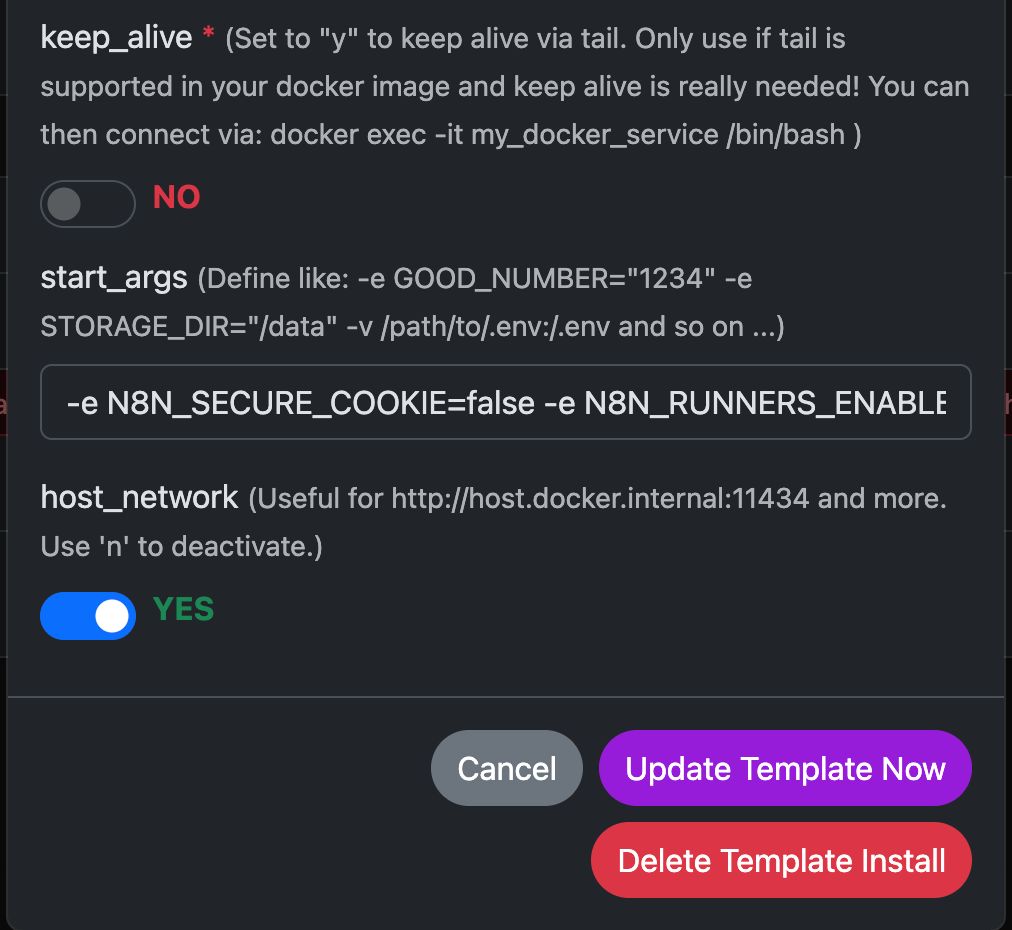
Polecenie Docker ‘Pod maską’
Szablon ten automatyzuje kompletne ustawienie kontenera Docker z obsługą GPU, w tym instalację wszystkich niezbędnych pakietów Ubuntu i zależności dla obsługi NVIDIA GPU. Upraszcza to proces, szczególnie dla użytkowników przyzwyczajonych do wdrożonych Docker dla serwerów internetowych, które często wymagają bardziej złożonej konfiguracji.
Poniższy docker run polecenie jest generowane automatycznie przez szablon w celu uruchomienia wybranego kontenera GPU. Zawiera ono wszystkie niezbędne ustawienia dla optymalnej wydajności i kompatybilności z serwerem Trooper.AI.
Polecenie to służy jako przykład ilustracyjny, aby zapewnić programistom wgląd w podstawowe procesy:
docker run -d \
--name ${CONTAINER_NAME} \
--restart always \
--gpus ${GPUS} \
--add-host=host.docker.internal:host-gateway \
-p ${PUBLIC_PORT}:${DOCKER_PORT} \
-v ${LOCAL_DATA_DIR}:/home/node/.n8n \
-e N8N_SECURE_COOKIE=false \
-e N8N_RUNNERS_ENABLED=true \
-e N8N_HOST=${N8N_HOST} \
-e WEBHOOK_URL=${WEBHOOK_URL} \
docker.n8n.io/n8nio/n8n \
tail -f /dev/null
Nie używaj tego polecenia ręcznie, jeśli nie jesteś ekspertem od Dockera! Po prostu zaufaj szablonowi.
Co umożliwia N8N na prywatnym serwerze GPU?
n8n umożliwia uruchamianie skomplikowanych procesów (workflowów) bezpośrednio na Twoim serwerze GPU z Trooper.AI. Oznacza to możliwość automatyzacji zadań związanych z przetwarzaniem obrazów/wideo, analizą danych, interakcjami z modelami językowymi (LLM), oraz wielu innych – wykorzystując moc GPU dla przyspieszonego wykonania.
Konkretnie możesz uruchamiać przepływ pracy dla:
- Manipulacja obrazów/wideo: Automatyzuj skalowanie, naniesienie znaku wodnego (watermarkingu), wykrywanie obiektów oraz inne zadania wizualne.
- Przetwarzanie danych: Ekstrahowanie, transformacja i ładowanie danych z różnych źródeł.
- Integracja z modelami językowymi (LLM): Połączenie i interakcja z dużymi modelami językowymi w celu wykonywania zadań takich jak generowanie tekstu, tłumaczenia oraz analiza nastrojów.
- Automatyzacja stron internetowych: Automatyzuj zadania na różnych stronach i API.
- Niestandardowe procesy: Twórz i wdrażaj dowolne automatyczne procesy dostosowane do Twoich potrzeb.
Pamiętaj, że będziesz musiał zainstalować narzędzia AI, takie jak ComfyUI i Ollama, aby zintegrować je z Twoimi przepływami pracy N8N na serwerze lokalnie. Dodatkowo potrzebujesz wystarczającej ilości pamięci GPU VRAM, aby obsługiwać wszystkie modele. Nie przydzielaj tych GPU do dockera działającego z N8N.
Co to jest Docker w kontekście serwera GPU?
Na serwerze GPU Trooper.AI Docker pozwala na pakowanie aplikacji z ich zależnościami w standaryzowane jednostki zwane kontenerami. Jest to szczególnie potężne dla obciążeń przyspieszonych przez GPU, ponieważ zapewnia spójność w różnych środowiskach i upraszcza wdrożenia. Zamiast instalować zależności bezpośrednio na systemie operacyjnym hosta, kontenery Docker zawierają wszystko, co jest potrzebne do uruchomienia aplikacji - w tym biblioteki, narzędzia systemowe, środowisko wykonawcze i ustawienia.
Dla aplikacji GPU Docker umożliwia efektywne wykorzystanie zasobów GPU serwera. Dzięki wykorzystaniu NVIDIA Container Toolkit kontenery mogą uzyskiwać dostęp do GPU hosta, umożliwiając przyspieszone obliczenia dla zadań takich jak uczenie maszynowe, wnioskowanie głębokiego uczenia się i analityka danych. Ta izolacja również poprawia bezpieczeństwo i zarządzanie zasobami, umożliwiając wielu aplikacjom współdzielenie GPU bez wzajemnego zakłócania. Wdrożenie i skalowanie aplikacji opartych na GPU staje się znacznie łatwiejsze dzięki Dockerowi na serwerze Trooper.AI.
Więcej Dockera do uruchomienia
Możesz łatwo uruchamiać wiele kontenerów Docker i szukać pomocy poprzez: Kontakt z wsparciem