Cualquier Docker
Esta plantilla le permite desplegar contenedores Docker acelerados por GPU como ComfyUI y contenedores sin soporte de GPU, como n8n. Esta flexibilidad habilita una amplia gama de aplicaciones, desde generación de imágenes con IA hasta flujos de trabajo automatizados, todo dentro de un entorno único y manejable. Configure e ejecute sus contenedores Docker deseados sin complicaciones, aprovechando el poder y la comodidad de esta versátil plantilla.
Aunque prefieras gestionar las configuraciones de Docker directamente, recomendamos utilizar nuestra plantilla «Any Docker» para la configuración inicial. La configuración de Docker con soporte para GPU puede ser compleja y esta plantilla ofrece una base simplificada para construir e implementar tus contenedores.
⚠️ ¡Consideración importante para múltiples contenedores de Docker!
Para garantizar un funcionamiento adecuado al ejecutar múltiples contenedores Docker en tu servidor con GPU, es esencial asignar a cada contenedor un nombre único y un directorio de datos exclusivo. Por ejemplo, en lugar de usar «my_docker_container», especifica un nombre como «my_comfyui_container» y configura el directorio de datos en una ruta única como /home/trooperai/docker_comfyui_data. Este paso sencillo permitirá que varios contenedores de Docker funcionen sin conflictos.
Ejemplo 1: Servidor de Modelo de Lenguaje Compatible con OpenAI usando vLLM vía HF
Este ejemplo explica paso a paso cómo ejecutar una API compatible con vLLM y OpenAI utilizando la plantilla de Trooper.AI any-docker
.
Es escrito para ser comprensible incluso con conocimientos mínimos sobre Docker o IA.
Esta configuración utiliza Qwen/Qwen3-4B, que es compatible y ejecutable en todos los servidores de GPU de Trooper.AI
¿Qué hace esta configuración?
- Inicia un servidor vLLM dentro de Docker
- Carga el modelo Qwen/Qwen2-4B desde Hugging Face
- Expone una API HTTP compatible con OpenAI
- Funciona con controladores modernos de NVIDIA (CUDA 13 / 580+)
¿Por qué se necesita esta configuración
En controladores más recientes de NVIDIA, las imágenes antiguas de Docker con vLLM pueden fallar al inicio con errores de CUDA.
Para evitar esto, la plantilla any-docker:
- Utiliza la imagen de vLLM nocturna
- Obliga a Docker a cargar las bibliotecas de controladores NVIDIA del host
No es necesario modificar esta lógica; solo utilice la configuración de abajo.
Variables del plantilla
Consulte aquí en la captura de pantalla cómo configurarlo y el texto completo para copiar y pegar a continuación.
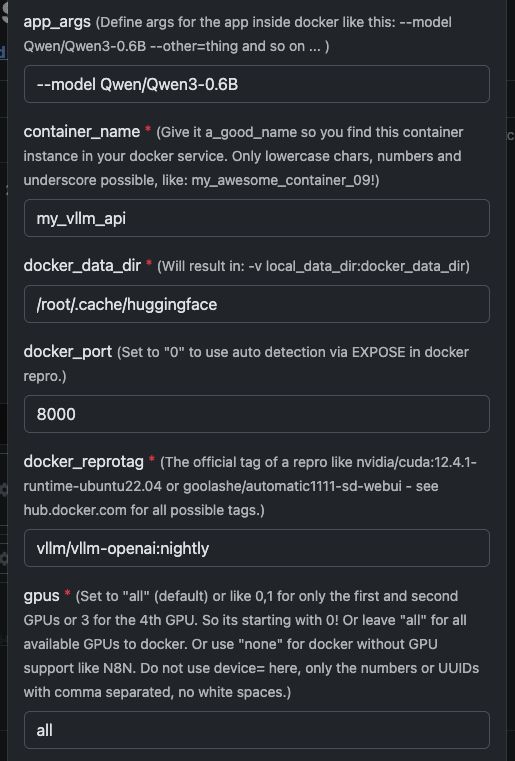
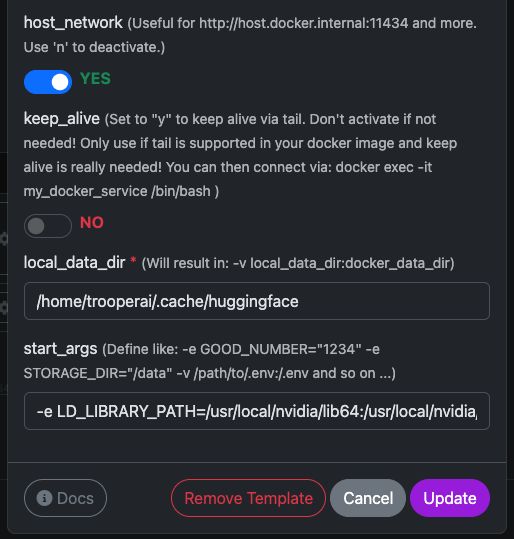
| variable | Valor | ¿Qué significa |
|---|---|---|
app_args |
--model Qwen/Qwen3-4B |
Define el modelo que debe cargar vLLM. |
container_name |
my_vllm_api |
Nombre del contenedor de Docker. |
docker_reprotag |
vllm/vllm-openai:nightly |
imagen de vLLM con correcciones para controladores modernos de NVIDIA. |
docker_port |
8000 |
Puerto interno utilizado por vLLM. |
gpus |
all |
Hace disponibles todas las GPU para Docker. |
host_network |
YES |
Expone la API directamente en la red del host. |
keep_alive |
NO |
Ciclo de vida normal del contenedor (recomendado). |
local_data_dir |
/home/trooperai/.cache/huggingface |
Directorio de caché del modelo en el host. |
docker_data_dir |
/root/.cache/huggingface |
Directorio de caché del modelo dentro del contenedor. |
start_args |
-e LD_LIBRARY_PATH=/usr/local/nvidia/lib64:/usr/local/nvidia/lib:/usr/lib/x86_64-linux-gnu --ipc=host --env HF_TOKEN=… |
Corrección obligatoria para CUDA y memoria compartida. |
Nota importante sobre LD_LIBRARY_PATH
Esta configuración es obligatoria en sistemas con CUDA 13.
Sin ella, vLLM podría fallar al iniciar debido a incompatibilidades con los controladores de NVIDIA.
No lo elimine.
¿Cómo verificar que funcione?
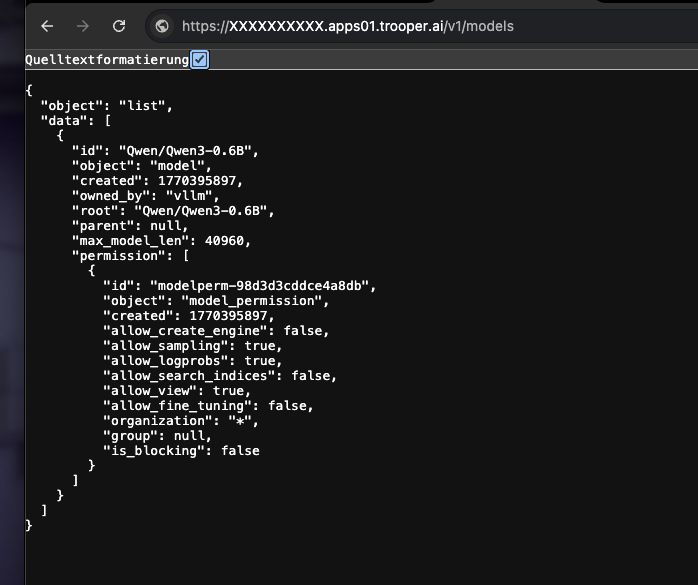
Ejecute el siguiente comando:
curl https://XXXXXXXX.apps01.trooper.ai/v1/models
Si ves Qwen/Qwen3-4B en la respuesta, el servidor está funcionando correctamente.
Ejemplo de uso con curl
curl https://XXXXXXXX.apps01.trooper.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer dummy-key" \
-d '{
"model": "Qwen/Qwen3-4B",
"messages": [
{ "role": "user", "content": "What is Trooper.AI?" }
]
}'
Ejemplo de uso con Node.js
Solicitud simple
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const result = await client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: "What is Trooper.AI?" }],
});
console.log(result.choices[0].message.content);
Prueba de carga concurrente en Node.js (16 solicitudes paralelas)
Este ejemplo envía 16 solicitudes concurrentes al API y muestra un resumen básico de la tasa de procesamiento.
import OpenAI from "openai";
import crypto from "crypto";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const CONCURRENCY = 16;
function randomPrompt() {
return `Explain this random concept in one sentence: ${crypto.randomUUID()}`;
}
const startTime = Date.now();
const requests = Array.from({ length: CONCURRENCY }, () =>
client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: randomPrompt() }],
})
);
const responses = await Promise.all(requests);
const endTime = Date.now();
const durationSeconds = (endTime - startTime) / 1000;
let totalTokens = 0;
for (const r of responses) {
totalTokens += r.usage.total_tokens;
}
const tokensPerSecond = (totalTokens / durationSeconds).toFixed(2);
console.log(
`${tokensPerSecond} token/s of total ${totalTokens} tokens in ${durationSeconds.toFixed(
2
)} seconds on ${CONCURRENCY} concurrent connections`
);
Esta prueba es útil para:
- validación de concurrencia
- estimación de rendimiento
- verificaciones rápidas de rendimiento y consistencia
¿Cómo obtener soporte en el servidor GPU de vLLM?
En cualquier problema con vLLM, contáctenos al soporte, tenemos mucha experiencia en su uso: Contacto de Soporte
Consulte nuestra sección de Benchmarks para comparar su instalación de vLLM con nuestras pruebas de rendimiento, centrado en resultados de alta concurrencia.
Guía adicional sobre autenticación en vLLM: Cómo configurar y usar la clave de API
vLLM ejecuta una API compatible con OpenAI, pero no requiere una clave de API real por defecto
Tiene dos opciones:
Opción 1: Usar una clave de prueba (predeterminada, la más sencilla)
Si la autenticación no está impuesta, puedes usar cualquier cadena como clave de API.
curl
-H "Authorization: Bearer dummy-key"
Node.js
apiKey: "dummy-key"
Esto es suficiente para la mayoría de despliegues internos, privados o en redes seguras.
Opción 2: Configurar una clave de API real (recomendado para puntos finales públicos)
Puede exigir una clave de API configurándola como variable de entorno al iniciar el contenedor.
En la plantilla any-docker (start_args):
--env OPENAI_API_KEY=your-secret-key
vLLM entonces requerirá esta clave en cada solicitud.
Ejemplo de solicitud con curl:
curl https://your-endpoint/v1/models \
-H "Authorization: Bearer your-secret-key"
Ejemplo en Node.js:
const client = new OpenAI({
apiKey: "your-secret-key",
baseURL: "https://your-endpoint/v1",
});
¿Cómo rotar o cambiar la clave?
- Actualizar
OPENAI_API_KEYen la plantilla - Haga clic en «actualizar plantilla»
- Las claves antiguas dejan de funcionar inmediatamente
Resumen
- No se requiere clave → usar
dummy-key - Punto de extremo público → configurar
OPENAI_API_KEY - La clave es nunca se genera automáticamente; tú la defines
Esto mantiene la autenticación sencilla y explícita.
Ejemplo 2: Ejecutar Qdrant en un servidor con GPU
Qdrant es una base de datos vectorial de alto rendimiento que admite búsqueda por similitud, búsqueda semántica y embeddings a gran escala.
Al implementarse en un servidor con GPU de Trooper.AI, Qdrant puede indexar y buscar millones de vectores extremadamente rápido — ideal para sistemas RAG, memoria de modelos LLM, motores de personalización e ingenios de recomendación.
La siguiente guía muestra cómo ejecutar Qdrant mediante Docker, cómo se ve en el panel de control y cómo consultarlo correctamente usando Node.js
Ejecutando el contenedor de Docker de Qdrant
Puedes ejecutar fácilmente el oficial qdrant/qdrant Contenedor de Docker con la configuración mostrada a continuación.
Estas capturas de pantalla muestran una configuración típica utilizada en servidores con GPU de Trooper.AI, incluyendo:
- Puerto del API REST expuesto
- Acceso al panel
- Persistencia de datos
- Aceleración opcional con GPU (si está habilitada en tu entorno)
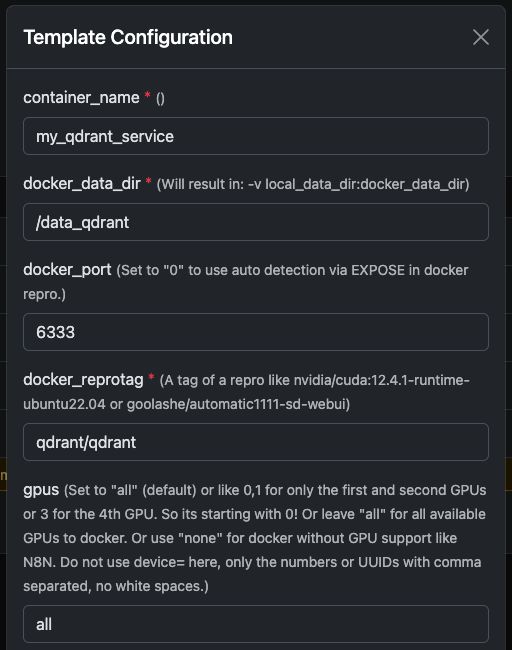
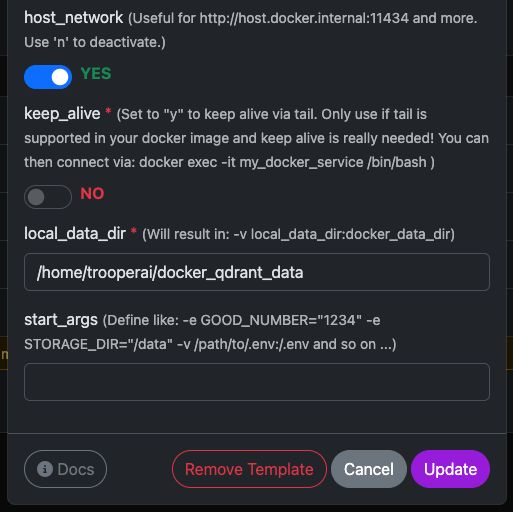
Una vez iniciado, tendrá acceso inmediato tanto al Panel de control de Qdrant como al API REST.
Vista previa del Panel de Qdrant
El panel de control permite inspeccionar colecciones, vectores, cargas útiles y índices.
Una configuración típica del panel de control se ve así:
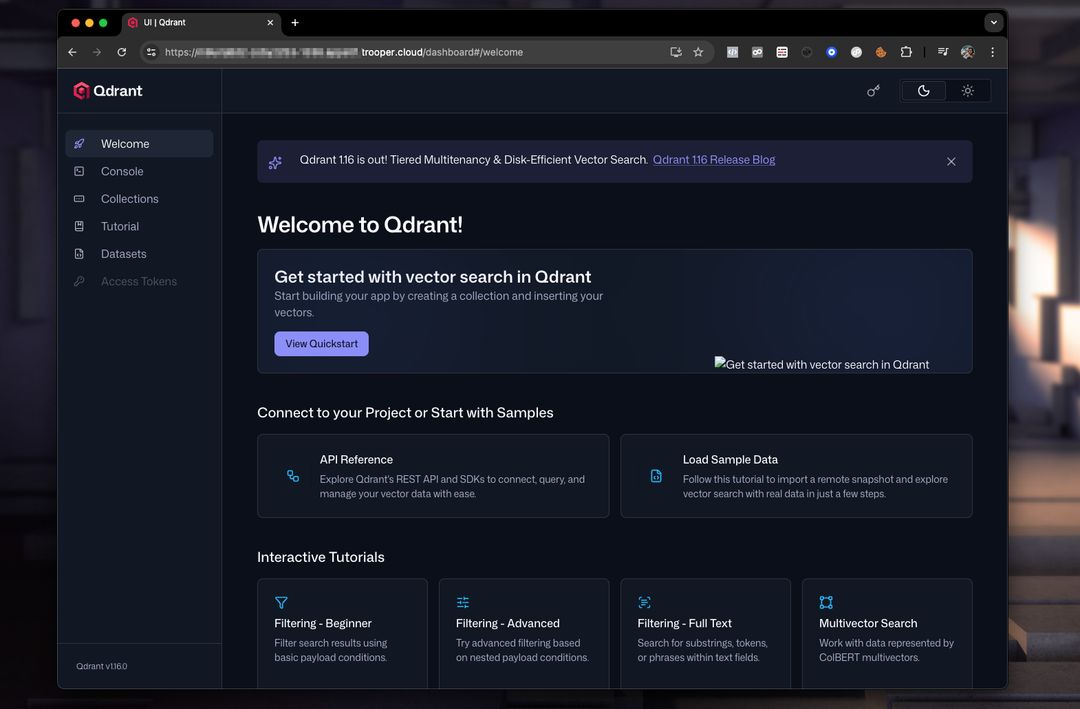
Desde aquí puedes:
- Crear colecciones
- Agregar vectores
- Ejecutar búsquedas de ejemplo
- Revisar metadatos
- Supervisar rendimiento
Consultar Qdrant desde Node.js
A continuación se muestra un ejemplo de funcional y corregido en Node.js usando la Qdrant REST API.
Correcciones importantes del ejemplo original:
- Qdrant requiere llamar a un endpoint como:
/collections/<collection_name>/points/search vectordebe ser un arreglo, no[a, b, c]- Node.js moderno tiene soporte nativo
fetch, por lo que ya no es necesarionode-fetch
Ejemplo en Node.js
// Qdrant Vector Search Example – fully compatible with Qdrant 1.x and 2.x
async function queryQdrant() {
// Replace "my_collection" with your actual collection name
const url = 'https://AUTOMATIC-SECURE-URL.trooper.ai/collections/my_collection/points/search';
const payload = {
vector: [0.1, 0.2, 0.3, 0.4], // Must be an array
limit: 5
};
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
});
if (!response.ok) {
throw new Error(`Qdrant request failed with status: ${response.status}`);
}
const data = await response.json();
console.log('Qdrant Response:', data);
return data;
} catch (error) {
console.error('Error querying Qdrant:', error);
return null;
}
}
queryQdrant();
Cuerpo de solicitud válido para búsqueda en Qdrant
Qdrant espera un cuerpo en formato JSON como este:
{
"vector": [0.1, 0.2, 0.3, 0.4],
"limit": 5
}
Dónde:
- vector → tu embedding
- límites → número máximo de resultados devueltos
También puede agregar filtros avanzados si es necesario:
{
"vector": [...],
"limit": 5,
"filter": {
"must": [
{ "key": "category", "match": { "value": "news" } }
]
}
}
Notas para usuarios de Trooper.AI
- Reemplazar
AUTOMATIC-SECURE-URL.trooper.aicon tu punto de extremo seguro asignado - Asegúrese de que su colección exista antes de consultar
Ejemplo: Ejecutar N8N con cualquier contenedor Docker
En este ejemplo, configuraremos Any Docker con su configuración para n8n y almacenamiento de datos persistente para que los reinicios sean posibles sin perder información. Esta configuración no incluye webhooks. Si necesita webhooks, consulte la plantilla preconfigurada dedicada: n8n
Esta guía es solo explicativa. Puedes iniciar cualquier contenedor de docker que prefieras.
Consulte las capturas de pantalla de la configuración a continuación:
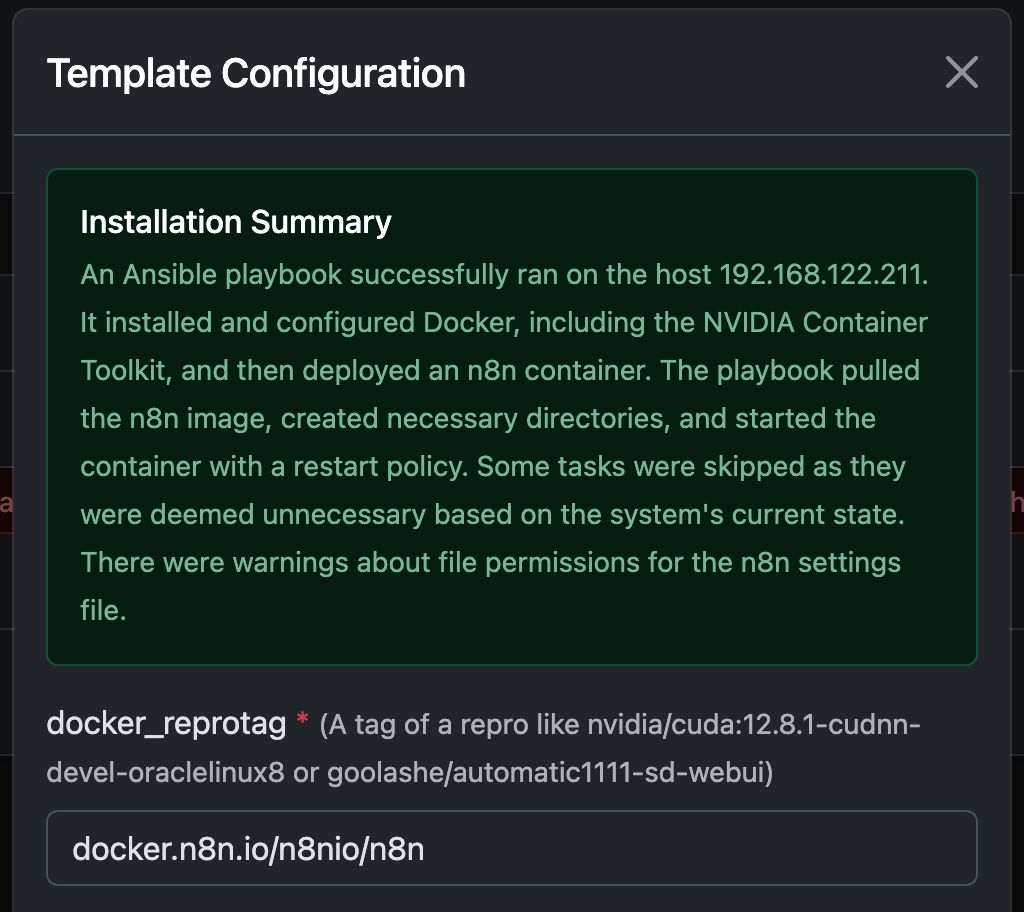
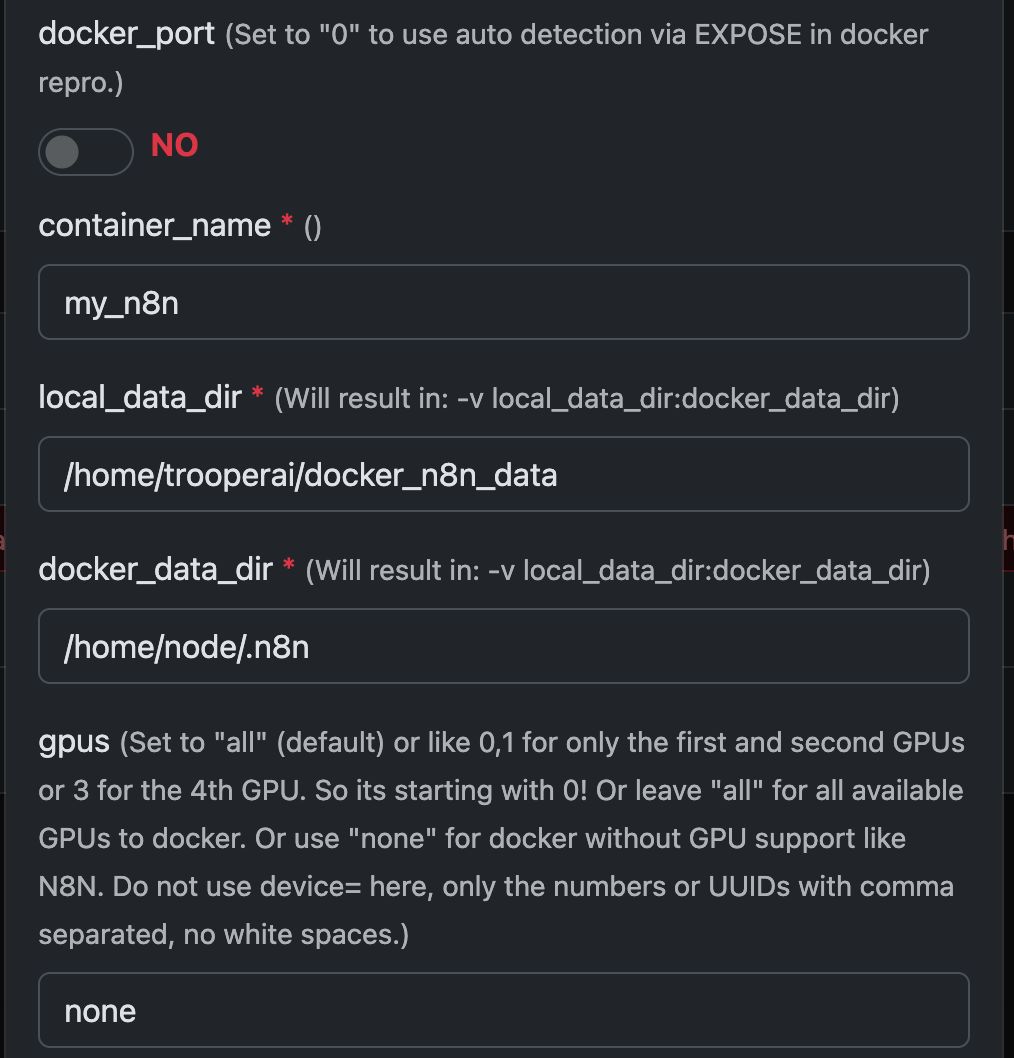
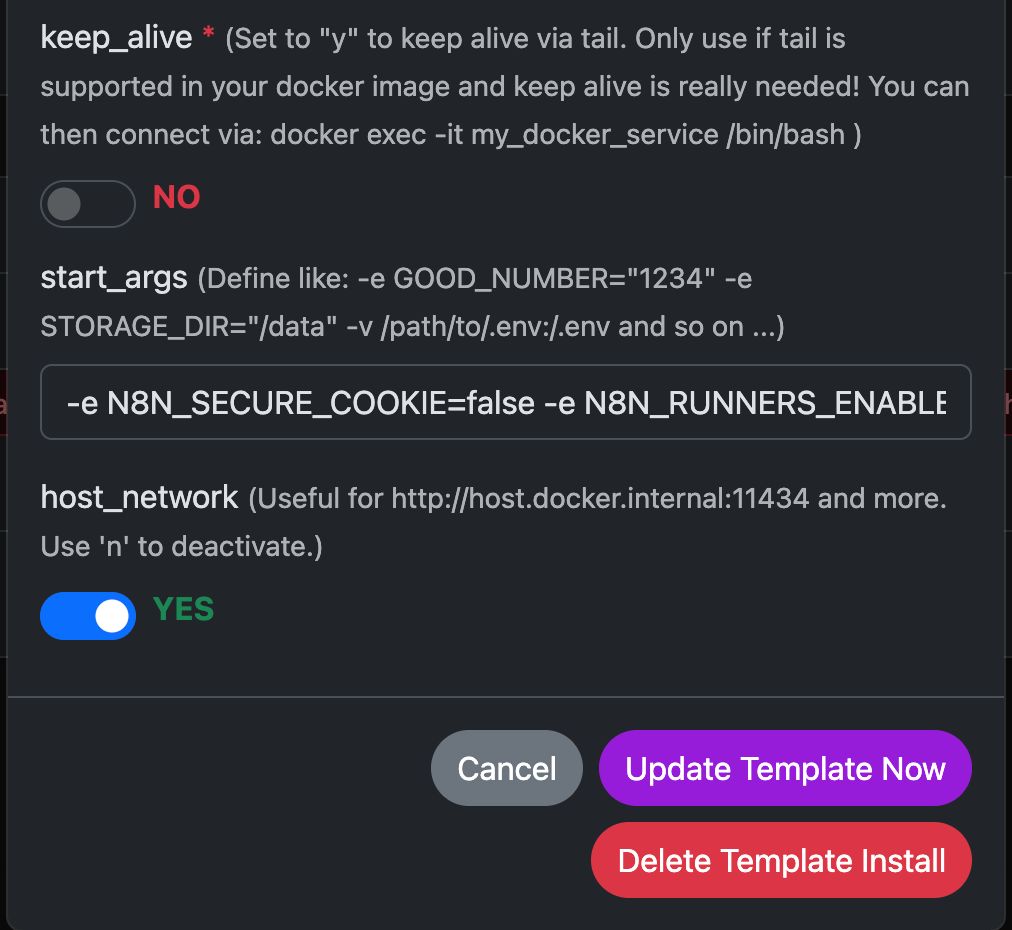
El comando de Docker «detrás del escenario»
Esta plantilla automatiza la configuración completa de un contenedor Docker habilitado para GPU, incluyendo la instalación de todos los paquetes y dependencias necesarios de Ubuntu para el soporte de GPU de NVIDIA. Esto simplifica el proceso, especialmente para usuarios acostumbrados a despliegues con Docker en servidores web, que suelen requerir una configuración más compleja.
Lo siguiente docker run El comando se genera automáticamente mediante la plantilla para iniciar el contenedor de GPU seleccionado. Este incluye todas las configuraciones necesarias para un rendimiento óptimo y compatibilidad con su servidor Trooper.AI.
Este comando sirve como ejemplo ilustrativo para dar a los desarrolladores una visión de los procesos subyacentes:
docker run -d \
--name ${CONTAINER_NAME} \
--restart always \
--gpus ${GPUS} \
--add-host=host.docker.internal:host-gateway \
-p ${PUBLIC_PORT}:${DOCKER_PORT} \
-v ${LOCAL_DATA_DIR}:/home/node/.n8n \
-e N8N_SECURE_COOKIE=false \
-e N8N_RUNNERS_ENABLED=true \
-e N8N_HOST=${N8N_HOST} \
-e WEBHOOK_URL=${WEBHOOK_URL} \
docker.n8n.io/n8nio/n8n \
tail -f /dev/null
No ejecute este comando manualmente si no es un experto en Docker. Confíe solo en la plantilla.
¿Qué capacidades aporta N8N en el servidor de GPU privado?
n8n desbloquea el potencial para ejecutar flujos de trabajo complejos directamente en tu servidor GPU de Trooper.AI. Esto significa que puedes automatizar tareas como procesamiento de imágenes/videos, análisis de datos, interacciones con modelos de lenguaje grande (LLM), y más — aprovechando el poder del GPU para un rendimiento acelerado.
Específicamente, puedes ejecutar flujos de trabajo para:
- Manipulación de Imágenes/Videos: Automatizar el redimensionamiento, la adición de marcas de agua, detección de objetos y otras tareas visuales.
- Procesamiento de datos: Extraer, transformar y cargar datos desde diversas fuentes.
- Integración con LLMs: Conectar e interactuar con Modelos de Lenguaje Grande para tareas como generación de texto, traducción y análisis de sentimiento.
- Automatización web: Automatizar tareas en diferentes sitios web y APIs.
- Flujos de Trabajo Personalizados: Construye y despliega cualquier proceso automatizado adaptado a tus necesidades.
Ten en cuenta que deberás instalar herramientas de IA como ComfyUI y Ollama para integrarlas en tus flujos de trabajo de n8n en el servidor localmente. Además necesitas suficiente memoria VRAM de la GPU para alimentar todos los modelos. No asignes esas GPUs al contenedor donde corre n8n.
¿Qué es Docker en el contexto de un servidor con GPU?
En un servidor de GPU de Trooper.AI, Docker permite empaquetar aplicaciones junto con sus dependencias en unidades estandarizadas llamadas contenedores. Esto es especialmente potente para cargas de trabajo aceleradas por GPU porque garantiza consistencia entre diferentes entornos y simplifica el despliegue. En lugar de instalar las dependencias directamente en el sistema operativo del host, los contenedores de Docker incluyen todo lo que una aplicación necesita para ejecutarse, como bibliotecas, herramientas del sistema, entorno de ejecución y configuraciones.
Para aplicaciones con GPU, Docker permite aprovechar eficientemente los recursos de GPU del servidor. Al utilizar el NVIDIA Container Toolkit, los contenedores pueden acceder a las GPUs del host, habilitando cómputo acelerado para tareas como machine learning, inferencia en deep learning y análisis de datos. Este aislamiento también mejora la seguridad y la gestión de recursos, permitiendo que múltiples aplicaciones compartan la GPU sin interferir entre sí. Implementar y escalar aplicaciones basadas en GPU se vuelve significativamente más sencillo con Docker en un servidor Trooper.AI.
Más contenedores de Docker para ejecutar
Puede ejecutar fácilmente múltiples contenedores de docker y solicitar ayuda mediante: Contacto de Soporte