Enhver Docker
Denne skabelon giver dig mulighed for at implementere både GPU-accelererede Docker-containere som ComfyUI og containere uden GPU-understøttelse, såsom n8n. Denne fleksibilitet muliggør en bred vifte af applikationer, fra AI-billedgenerering til automatiserede workflows, alt sammen i et enkelt, håndterbart miljø. Konfigurer og kør dine ønskede Docker-containere ubesværet ved at udnytte kraften og bekvemmeligheden ved denne alsidige skabelon.
Selv om du måske foretrækker at håndtere Docker-konfigurationer direkte, anbefaler vi at bruge vores "Any Docker"-mal til opsætning. At konfigurere Docker med GPU-støtte kan være komplekst, og denne mal tilbyder en strømlinet grundlag for opbygning og udplacering af dine containere.
🚨 Vigtig overvejelse for flere Docker-containere!
For at sikre korrekt funktionalitet ved kørsel af flere Docker-containere på din GPU-server, er det vigtigt at tildele hver container et unikt navn og datakatalog. For eksempel, i stedet for at bruge “my_docker_container”, angiv et navn som “my_comfyui_container”, og indstil datakataloget til en unik sti som /home/trooperai/docker_comfyui_dataDette simple trin vil tillade flere Docker-containere at køre uden konflikt.
Eksempel 1: vLLM OpenAI-kompatibel LLM-server via HF
Dette eksempel forklarer trinsvis, hvordan man kører en vLLM API kompatibel med OpenAI ved hjælp af Trooper.AIs any-docker-skabelon.
Det er skrevet til at være forståeligt selv med minimal viden om Docker eller AI.
Denne opsætning bruger Qwen/Qwen3-4B, som er understøttet og kan køre på alle Trooper.AI GPU-servere
Hvad denne opsætning gør
- Starter en vLLM-server inde i Docker
- Henter modellen Qwen/Qwen3-4B fra Hugging Face
- en OpenAI-kompatibel HTTP-API
- Fungerer på moderne NVIDIA-drivers (CUDA 13 / 580+)
Hvorfor denne konfiguration er nødvendig
På nyere NVIDIA-drivere kan ældre vLLM Docker-billeder crashe med CUDA-fejl under opstart.
For at undgå dette, anvend 'any-docker'-skabelonen:
- vLLMs natlige (nightly) Docker-billede
- tvinger Docker til at indlæse værtsmaskinens NVIDIA-styringsbiblioteker
Du behøver ikke at ændre denne logik – brug blot konfigurationen nedenfor.
Skabelonvariabler
Se her som skærmbillede, hvordan du konfigurerer, og nedenfor den komplette tekst til at kopiere og indsætte.
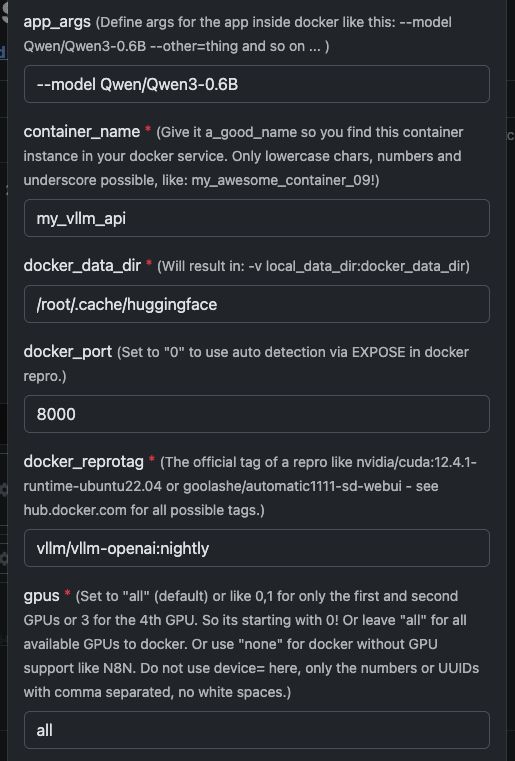
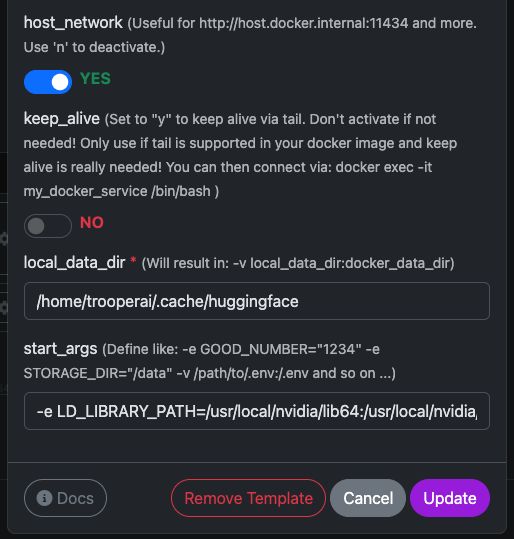
| Variabel | Værdi | Hvad det betyder |
|---|---|---|
app_args |
--model Qwen/Qwen3-4B |
Definerer hvilken model vLLM skal indlæse. |
container_name |
my_vllm_api |
Navnet på Docker-containeren. |
docker_reprotag |
vllm/vllm-openai:nightly |
vLLM-billede med rettelser til moderne NVIDIA-drivere. |
docker_port |
8000 |
Intern port brugt af vLLM. |
gpus |
all |
Gør alle GPU'er tilgængelige for Docker. |
host_network |
YES |
Udsætter API'et direkte på værtsnetværket. |
keep_alive |
NO |
Normal containerlivscyklus (anbefales). |
local_data_dir |
/home/trooperai/.cache/huggingface |
Modelcache-mappe på værten. |
docker_data_dir |
/root/.cache/huggingface |
Modelcache-mappe inde i containeren. |
start_args |
-e LD_LIBRARY_PATH=/usr/local/nvidia/lib64:/usr/local/nvidia/lib:/usr/lib/x86_64-linux-gnu --ipc=host --env HF_TOKEN=… |
Påkrævet rettelse for CUDA + delt hukommelse. |
Vigtig bemærkning om LD_LIBRARY_PATH
Denne indstilling er påkrævet på systemer med CUDA 13.
Uden den kan vLLM muligvis ikke starte grundet uforenelighed mellem NVIDIA-drivere.
Fjern ikke dette.
Sådan kontrolleres det, om det virker
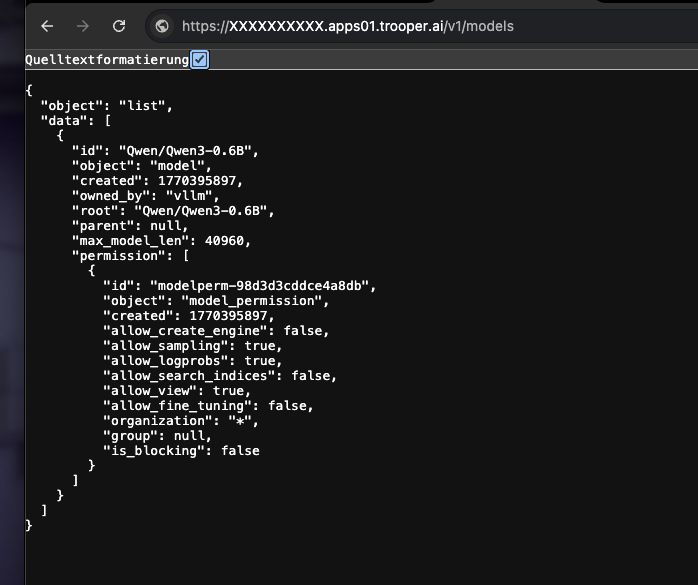
Kør følgende kommando:
curl https://XXXXXXXX.apps01.trooper.ai/v1/models
Hvis du ser Qwen/Qwen3-4B i svaret kører serveren korrekt.
Eksempel på brug med curl
curl https://XXXXXXXX.apps01.trooper.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer dummy-key" \
-d '{
"model": "Qwen/Qwen3-4B",
"messages": [
{ "role": "user", "content": "What is Trooper.AI?" }
]
}'
Eksempel på brug med Node.js
Simpel forespørgsel
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const result = await client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: "What is Trooper.AI?" }],
});
console.log(result.choices[0].message.content);
Node.js Concurrent Load Test (16 parallelle forespørgsler)
Dette eksempel sender 16 samtidige forespørgsler til API'et og udskriver en simpel gennemstrømningsoversigt.
import OpenAI from "openai";
import crypto from "crypto";
const client = new OpenAI({
apiKey: "dummy-key",
baseURL: "https://XXXXXXXX.apps01.trooper.ai/v1",
});
const CONCURRENCY = 16;
function randomPrompt() {
return `Explain this random concept in one sentence: ${crypto.randomUUID()}`;
}
const startTime = Date.now();
const requests = Array.from({ length: CONCURRENCY }, () =>
client.chat.completions.create({
model: "Qwen/Qwen3-4B",
messages: [{ role: "user", content: randomPrompt() }],
})
);
const responses = await Promise.all(requests);
const endTime = Date.now();
const durationSeconds = (endTime - startTime) / 1000;
let totalTokens = 0;
for (const r of responses) {
totalTokens += r.usage.total_tokens;
}
const tokensPerSecond = (totalTokens / durationSeconds).toFixed(2);
console.log(
`${tokensPerSecond} token/s of total ${totalTokens} tokens in ${durationSeconds.toFixed(
2
)} seconds on ${CONCURRENCY} concurrent connections`
);
Denne test er nyttig til:
- verificering af samtidighed
- estimering af gennemstrømning
- hurtige ydeevnetest
Hvordan får man support til vLLM GPU Server?
Kontakt understøttelse ved problemer med vLLM – vi har stor erfaring i brug af vLLM:
Henvis til vores Benchmark-afsnit for at sammenligne din vLLM-installation med vore ydelsestests, med fokus på resultater ved multikonkurranse.
Bonus vedrørende vLLM-godkendelse: Sådan konfigureres og bruges API-nøgle
En API kompatibel med OpenAI, men kræver ikke en ægte API-nøgle som standard
Du har to muligheder:
Mulighed 1: Brug en dummy-nøgle (standard, nemmest)
Hvis autentificering ikke er påkrævet, kan du bruge enhver streng som API-nøgle.
curl
-H "Authorization: Bearer dummy-key"
Node.js
apiKey: "dummy-key"
Dette er tilstrækkeligt for de fleste interne, private eller sikrede netværksimplementeringer.
Mulighed 2: Angiv en ægte API-nøgle (anbefales til offentlige slutpunkter)
Du kan håndhæve en API-nøgle ved at indstille den som en miljøvariabel, når du starter containeren.
I den any-docker-mal (start_args):
--env OPENAI_API_KEY=your-secret-key
kræver denne nøgle
Eksempel på cURL-forespørgsel:
curl https://your-endpoint/v1/models \
-H "Authorization: Bearer your-secret-key"
Eksempel på Node.js:
const client = new OpenAI({
apiKey: "your-secret-key",
baseURL: "https://your-endpoint/v1",
});
Sådan roterer eller ændrer du nøglen
- Opdater
OPENAI_API_KEYi skabelonen - Klik på “opdater skabelon”
- Gamle nøgler holder øjeblikkeligt op med at fungere
Opsummering
- Ingen nøgle nødvendig → brug
dummy-key - Offentligt endepunkt → indstil
OPENAI_API_KEY - Nøglen genereres aldrig automatisk; du definerer den selv
Dette holder godkendelsen simpel og eksplicit.
Eksempel 2: Kørsel af Qdrant på en GPU-server
Qdrant er en højtydende vektordatabase, der understøtter lighedssøgning, semantisk søgning og embeddings i stor skala.
Når Qdrant er implementeret på en GPU-drevet Trooper.AI server, kan den indeksere og søge i millioner af vektorer ekstremt hurtigt – perfekt til RAG-systemer, LLM-hukommelse, personaliseringsmotorer og anbefalingssystemer.
Den følgende vejledning viser hvordan du kører Qdrant via Docker, hvordan det ser ud i dashboards og hvordan du korrekt udfører spørgsmål mod det ved hjælp af Node.js
Kørsel af Qdrant Docker Container
Du kan nemt køre den officielle qdrant/qdrant Docker-container med de viste indstillinger.
Disse skærmbilleder viser en typisk konfiguration, der bruges på Trooper.AI GPU-servere, inklusive:
- Eksponeret REST API port
- Adgang til dashboard
- Datapersistens
- Valgfri GPU-acceleration (hvis aktiveret i dit miljø)
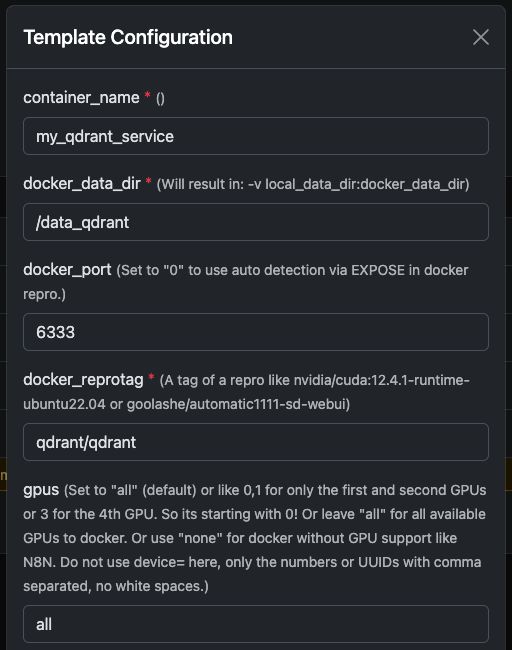
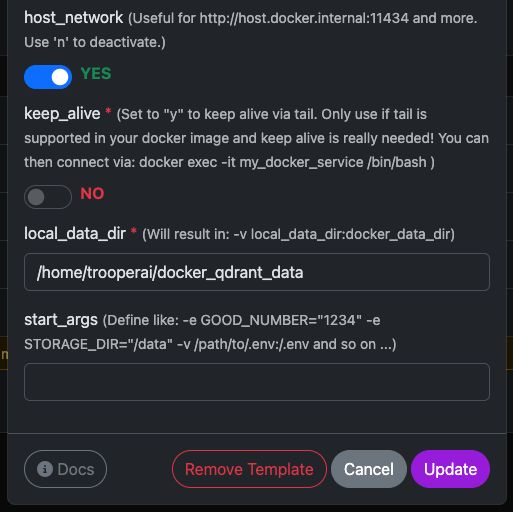
Qdrant Dashboard og REST API’en er straks tilgængelige efter opstart.
Qdrant Dashboard Forhåndsvisning
Dashboardet giver dig mulighed for at inspicere collections, vektorer, payloads og indekser.
Et typisk dashboard-setup ser således ud:
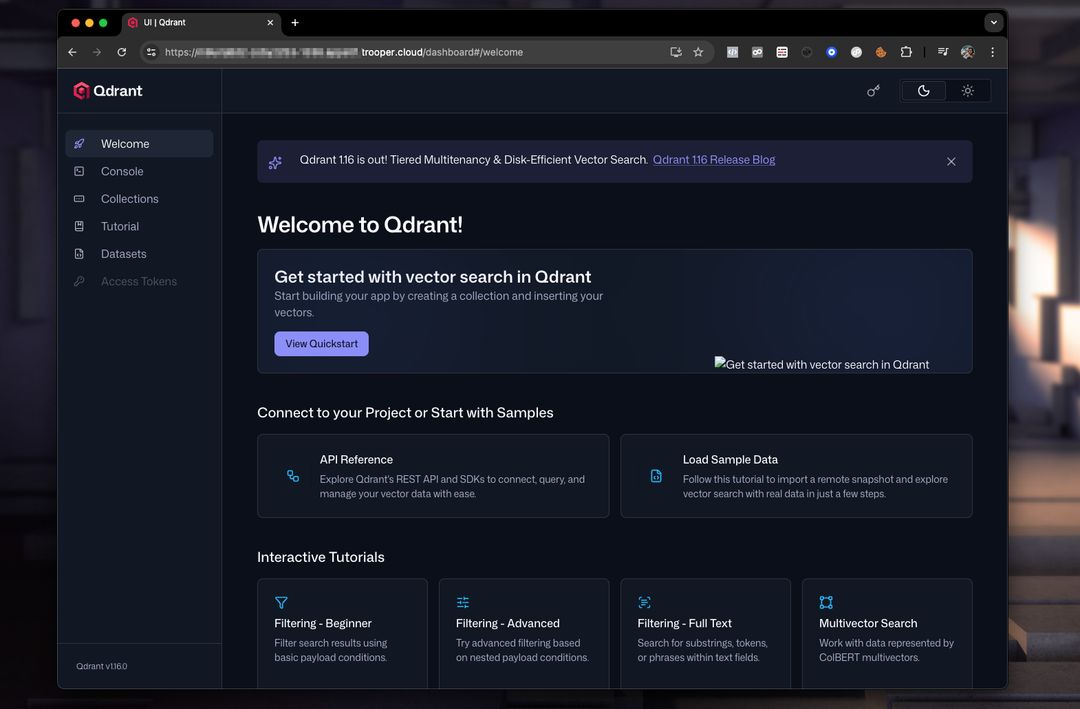
Herfra kan du:
- Opret samlinger
- Tilføj vektorer
- Kør eksempel søgninger
- Inspicer metadata
- Overvåg ydeevne
Forespørgsel af Qdrant fra Node.js
Her er et fungerende og korrigeret Node.js eksempel ved hjælp af Qdrants REST API.
Vigtige rettelser i forhold til det oprindelige eksempel:
- Qdrant kræver, at der kaldes et endpoint som:
/collections/<collection_name>/points/search vektorskal være en array, ikke[a, b, c]- Moderne Node.js har indbygget
fetch, så der er ikke behov fornode-fetch
NODEJS EKSEMPEL
// Qdrant Vector Search Example – fully compatible with Qdrant 1.x and 2.x
async function queryQdrant() {
// Replace "my_collection" with your actual collection name
const url = 'https://AUTOMATIC-SECURE-URL.trooper.ai/collections/my_collection/points/search';
const payload = {
vector: [0.1, 0.2, 0.3, 0.4], // Must be an array
limit: 5
};
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
});
if (!response.ok) {
throw new Error(`Qdrant request failed with status: ${response.status}`);
}
const data = await response.json();
console.log('Qdrant Response:', data);
return data;
} catch (error) {
console.error('Error querying Qdrant:', error);
return null;
}
}
queryQdrant();
Gyldig Qdrant Søgepayload
Qdrant forventer en JSON-brødtekst som denne:
{
"vector": [0.1, 0.2, 0.3, 0.4],
"limit": 5
}
Hvor:
- vektor → din embeddings
- grænse → maksimal antal resultater der returneres
Du kan også tilføje avancerede filtre om nødvendigt:
{
"vector": [...],
"limit": 5,
"filter": {
"must": [
{ "key": "category", "match": { "value": "news" } }
]
}
}
Bemærkninger til Trooper.AI-brugere
- Erstat
AUTOMATIC-SECURE-URL.trooper.aimed dit tildelte sikre endepunkt - Sørg for, at din samling eksisterer, før du forespørger.
Eksempel: Kørsel af N8N med Any Docker
I denne eksempel konfigurerer vi Any Docker med din konfiguration til n8n og vedvarende datalagring, så genstart er mulig uden tab af data. Denne konfiguration inkluderer ikke webhooks. Hvis du har brug for webhooks, gå til den dedikerede forkonfigurerede skabelon:
Denne guide er kun til forklaring. Du kan starte enhver docker-container, du ønsker.
Se skærmbilleder af konfigurationen nedenfor:
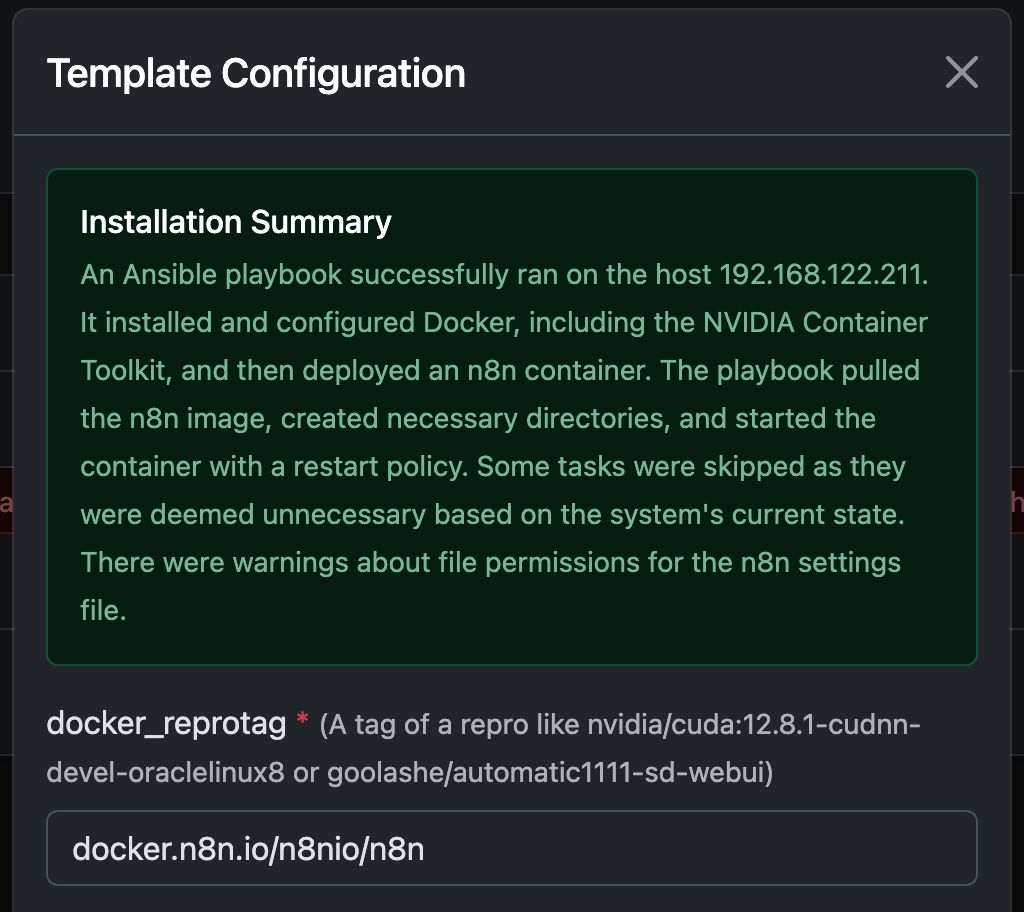
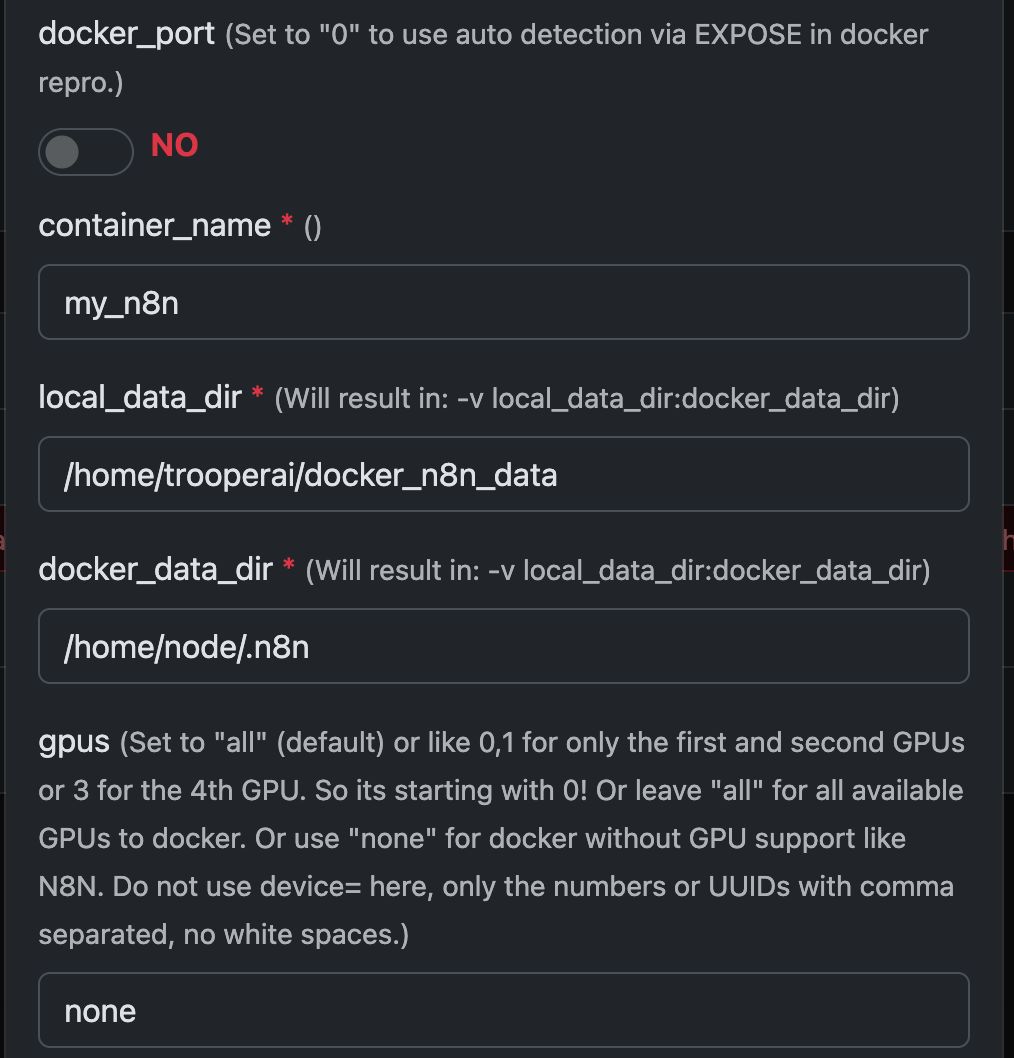
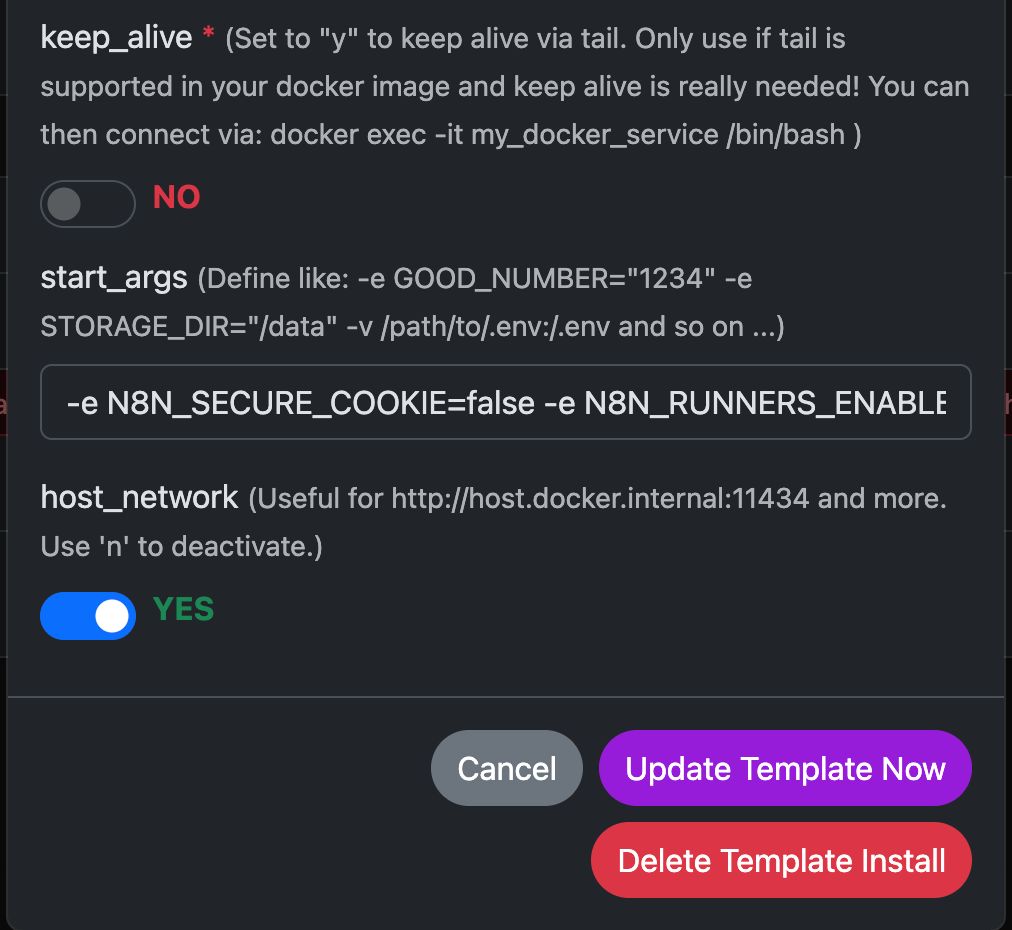
Docker-kommandoen 'Under Motorhjelmen'
Denne skabelon automatiserer den komplette opsætning af en GPU-aktiveret Docker-container, inklusive installationen af alle nødvendige Ubuntu-pakker og afhængigheder for NVIDIA GPU-understøttelse. Dette forenkler processen, især for brugere, der er vant til Docker-implementeringer til webservere, hvilket ofte kræver mere kompleks konfiguration.
Følgende docker run Kommandoet genereres automatisk af skabelonen for at starte din valgte GPU-container. Det indkapsler alle de nødvendige indstillinger for optimal ydeevne og kompatibilitet med din Trooper.AI-server.
Denne kommando fungerer som et illustrativt eksempel for at give udviklere indsigt i de underliggende processer:
docker run -d \
--name ${CONTAINER_NAME} \
--restart always \
--gpus ${GPUS} \
--add-host=host.docker.internal:host-gateway \
-p ${PUBLIC_PORT}:${DOCKER_PORT} \
-v ${LOCAL_DATA_DIR}:/home/node/.n8n \
-e N8N_SECURE_COOKIE=false \
-e N8N_RUNNERS_ENABLED=true \
-e N8N_HOST=${N8N_HOST} \
-e WEBHOOK_URL=${WEBHOOK_URL} \
docker.n8n.io/n8nio/n8n \
tail -f /dev/null
Brug ikke denne kommando manuelt, hvis du ikke er Docker-ekspert! Stol blot på skabelonen.
Hvad gør N8N muligt på den private GPU-server?
n8n frigiver muligheden for at køre komplekse arbejdsprocesser direkte på din Trooper.AI GPU-server. Det betyder, at du kan automatisere opgaver som involverer billede/video-behandling, datanalyse, interaktion med LLMs (Large Language Models) og meget mere – ved hjælp af GPU’ens kraft til accelereret ydeevne.
Konkret kan du køre workflows til:
- Billed/video-manipulation: Automatiser omskæring, vandmærkning, genkendelse af objekter og andre visuelle opgaver.
- Datatabejdning: Ekstraher, transformer og indlæs data fra forskellige kilder.
- Integration af store sprogmodeller (LLMs): Tilslut og interager med Store Sprogmodeller til opgaver som tekstgenerering, oversættelse og analyse af stemning.
- Webautomatisering: Automatiser opgaver på tværs af forskellige websider og APIs.
- Skræddersyede arbejdsgange: Opret og implementer enhver automatiseret proces tilpasset dine behov.
Husk, du skal installere AI-værktøjer som ComfyUI og Ollama for at integrere dem i dine N8N-workflows lokalt på serveren. Du skal også have tilstrækkelig GPU VRAM til at drive alle modeller. Giv ikke disse GPU'er til docker, der kører N8N.
Hvad er Docker i forhold til en GPU-server?
På en Trooper.AI GPU-server giver Docker dig mulighed for at pakke applikationer med deres afhængigheder ind i standardiserede enheder kaldet containere. Dette er særligt kraftfuldt for GPU-accelererede workloads, da det sikrer konsistens på tværs af forskellige miljøer og forenkler implementeringen. I stedet for at installere afhængigheder direkte på host-operativsystemet, inkluderer Docker-containere alt, hvad en applikation har brug for for at køre – herunder biblioteker, systemværktøjer, runtime og indstillinger.
For GPU-applikationer giver Docker dig mulighed for effektivt at udnytte serverens GPU-ressourcer. Ved at bruge NVIDIA Container Toolkit kan containere få adgang til værtsmaskinens GPU'er, hvilket muliggør accelereret computing til opgaver som machine learning, deep learning inference og dataanalyse. Denne isolation forbedrer også sikkerheden og ressourcestyringen, så flere applikationer kan dele GPU'en uden at forstyrre hinanden. Implementering og skalering af GPU-baserede applikationer bliver betydeligt lettere med Docker på en Trooper.AI-server.
Flere Docker-containere kan køres
Du kan nemt køre flere Docker-container og spørge om hjælp via: